 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
xSIM++: An Improved Proxy to Bitext Mining Performance for Low-Resource Languages
Jun 22, 2023
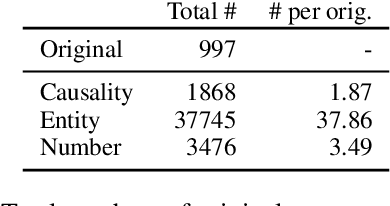

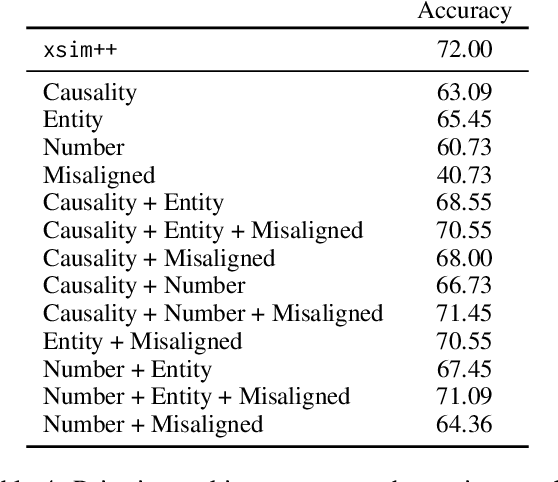
We introduce a new proxy score for evaluating bitext mining based on similarity in a multilingual embedding space: xSIM++. In comparison to xSIM, this improved proxy leverages rule-based approaches to extend English sentences in any evaluation set with synthetic, hard-to-distinguish examples which more closely mirror the scenarios we encounter during large-scale mining. We validate this proxy by running a significant number of bitext mining experiments for a set of low-resource languages, and subsequently train NMT systems on the mined data. In comparison to xSIM, we show that xSIM++ is better correlated with the downstream BLEU scores of translation systems trained on mined bitexts, providing a reliable proxy of bitext mining performance without needing to run expensive bitext mining pipelines. xSIM++ also reports performance for different error types, offering more fine-grained feedback for model development.
Listen to what they say: Better understand and detect online misinformation with user feedback
Oct 31, 2022



Social media users who report content are key allies in the management of online misinformation, however, no research has been conducted yet to understand their role and the different trends underlying their reporting activity. We suggest an original approach to studying misinformation: examining it from the reporting users perspective at the content-level and comparatively across regions and platforms. We propose the first classification of reported content pieces, resulting from a review of c. 9,000 items reported on Facebook and Instagram in France, the UK, and the US in June 2020. This allows us to observe meaningful distinctions regarding reporting content between countries and platforms as it significantly varies in volume, type, topic, and manipulation technique. Examining six of these techniques, we identify a novel one that is specific to Instagram US and significantly more sophisticated than others, potentially presenting a concrete challenge for algorithmic detection and human moderation. We also identify four reporting behaviours, from which we derive four types of noise capable of explaining half of the inaccuracy found in content reported as misinformation. We finally show that breaking down the user reporting signal into a plurality of behaviours allows to train a simple, although competitive, classifier on a small dataset with a combination of basic users-reports to classify the different types of reported content pieces.
No Language Left Behind: Scaling Human-Centered Machine Translation
Jul 11, 2022
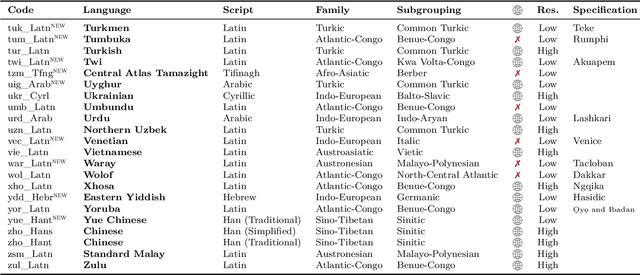
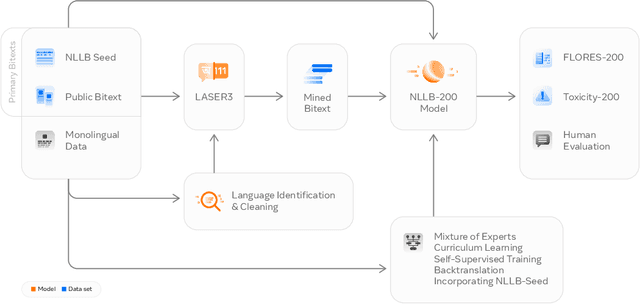
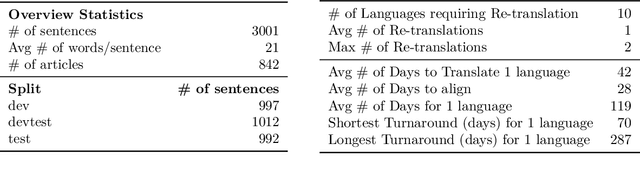
Driven by the goal of eradicating language barriers on a global scale, machine translation has solidified itself as a key focus of artificial intelligence research today. However, such efforts have coalesced around a small subset of languages, leaving behind the vast majority of mostly low-resource languages. What does it take to break the 200 language barrier while ensuring safe, high quality results, all while keeping ethical considerations in mind? In No Language Left Behind, we took on this challenge by first contextualizing the need for low-resource language translation support through exploratory interviews with native speakers. Then, we created datasets and models aimed at narrowing the performance gap between low and high-resource languages. More specifically, we developed a conditional compute model based on Sparsely Gated Mixture of Experts that is trained on data obtained with novel and effective data mining techniques tailored for low-resource languages. We propose multiple architectural and training improvements to counteract overfitting while training on thousands of tasks. Critically, we evaluated the performance of over 40,000 different translation directions using a human-translated benchmark, Flores-200, and combined human evaluation with a novel toxicity benchmark covering all languages in Flores-200 to assess translation safety. Our model achieves an improvement of 44% BLEU relative to the previous state-of-the-art, laying important groundwork towards realizing a universal translation system. Finally, we open source all contributions described in this work, accessible at https://github.com/facebookresearch/fairseq/tree/nllb.
Bitext Mining Using Distilled Sentence Representations for Low-Resource Languages
May 25, 2022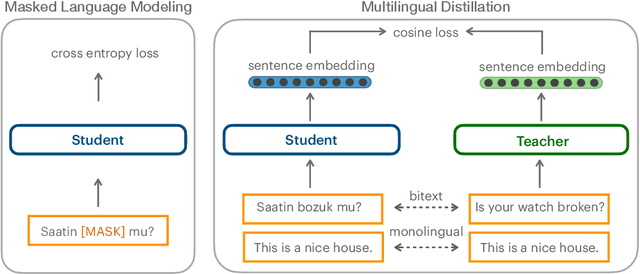
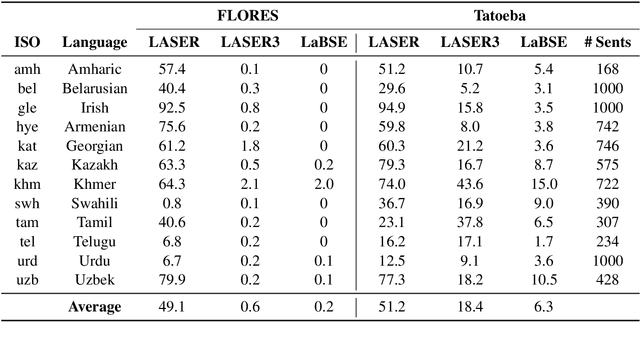
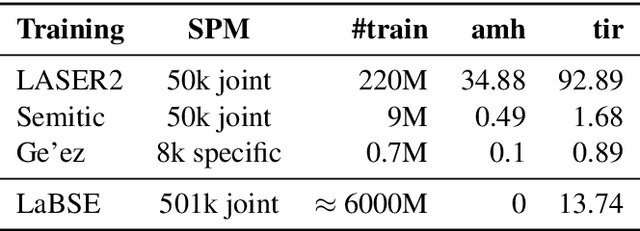

Scaling multilingual representation learning beyond the hundred most frequent languages is challenging, in particular to cover the long tail of low-resource languages. A promising approach has been to train one-for-all multilingual models capable of cross-lingual transfer, but these models often suffer from insufficient capacity and interference between unrelated languages. Instead, we move away from this approach and focus on training multiple language (family) specific representations, but most prominently enable all languages to still be encoded in the same representational space. To achieve this, we focus on teacher-student training, allowing all encoders to be mutually compatible for bitext mining, and enabling fast learning of new languages. We introduce a new teacher-student training scheme which combines supervised and self-supervised training, allowing encoders to take advantage of monolingual training data, which is valuable in the low-resource setting. Our approach significantly outperforms the original LASER encoder. We study very low-resource languages and handle 50 African languages, many of which are not covered by any other model. For these languages, we train sentence encoders, mine bitexts, and validate the bitexts by training NMT systems.