 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgexSIM++: An Improved Proxy to Bitext Mining Performance for Low-Resource Languages
Paper and Code

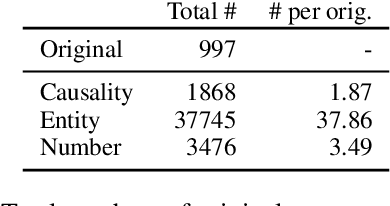

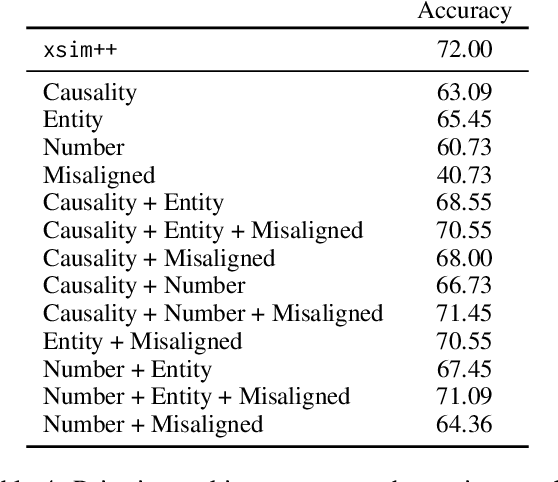
We introduce a new proxy score for evaluating bitext mining based on similarity in a multilingual embedding space: xSIM++. In comparison to xSIM, this improved proxy leverages rule-based approaches to extend English sentences in any evaluation set with synthetic, hard-to-distinguish examples which more closely mirror the scenarios we encounter during large-scale mining. We validate this proxy by running a significant number of bitext mining experiments for a set of low-resource languages, and subsequently train NMT systems on the mined data. In comparison to xSIM, we show that xSIM++ is better correlated with the downstream BLEU scores of translation systems trained on mined bitexts, providing a reliable proxy of bitext mining performance without needing to run expensive bitext mining pipelines. xSIM++ also reports performance for different error types, offering more fine-grained feedback for model development.