 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusicGen-Stem: Multi-stem music generation and edition through autoregressive modeling
Jan 07, 2025



While most music generation models generate a mixture of stems (in mono or stereo), we propose to train a multi-stem generative model with 3 stems (bass, drums and other) that learn the musical dependencies between them. To do so, we train one specialized compression algorithm per stem to tokenize the music into parallel streams of tokens. Then, we leverage recent improvements in the task of music source separation to train a multi-stream text-to-music language model on a large dataset. Finally, thanks to a particular conditioning method, our model is able to edit bass, drums or other stems on existing or generated songs as well as doing iterative composition (e.g. generating bass on top of existing drums). This gives more flexibility in music generation algorithms and it is to the best of our knowledge the first open-source multi-stem autoregressive music generation model that can perform good quality generation and coherent source editing. Code and model weights will be released and samples are available on https://simonrouard.github.io/musicgenstem/.
Large Concept Models: Language Modeling in a Sentence Representation Space
Dec 11, 2024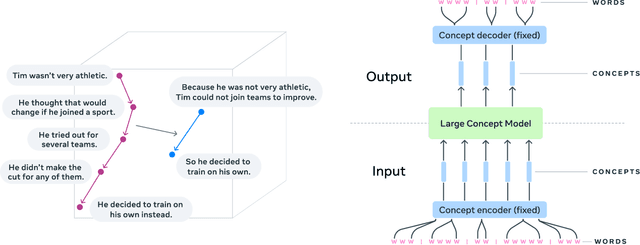
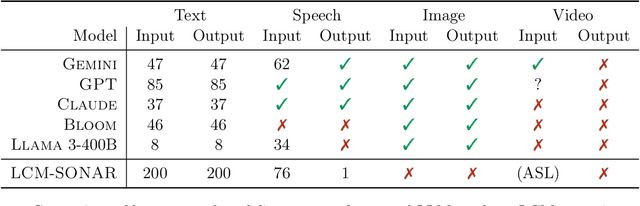
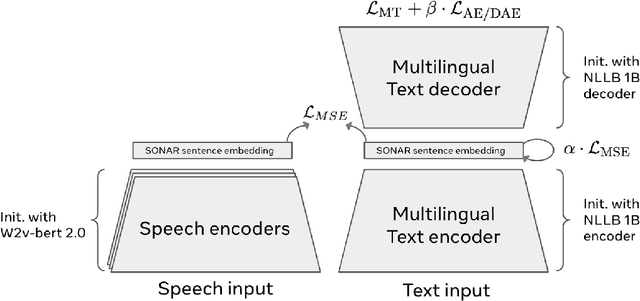
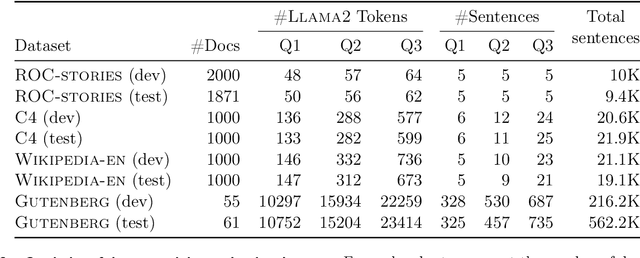
LLMs have revolutionized the field of artificial intelligence and have emerged as the de-facto tool for many tasks. The current established technology of LLMs is to process input and generate output at the token level. This is in sharp contrast to humans who operate at multiple levels of abstraction, well beyond single words, to analyze information and to generate creative content. In this paper, we present an attempt at an architecture which operates on an explicit higher-level semantic representation, which we name a concept. Concepts are language- and modality-agnostic and represent a higher level idea or action in a flow. Hence, we build a "Large Concept Model". In this study, as proof of feasibility, we assume that a concept corresponds to a sentence, and use an existing sentence embedding space, SONAR, which supports up to 200 languages in both text and speech modalities. The Large Concept Model is trained to perform autoregressive sentence prediction in an embedding space. We explore multiple approaches, namely MSE regression, variants of diffusion-based generation, and models operating in a quantized SONAR space. These explorations are performed using 1.6B parameter models and training data in the order of 1.3T tokens. We then scale one architecture to a model size of 7B parameters and training data of about 2.7T tokens. We perform an experimental evaluation on several generative tasks, namely summarization and a new task of summary expansion. Finally, we show that our model exhibits impressive zero-shot generalization performance to many languages, outperforming existing LLMs of the same size. The training code of our models is freely available.
Latent Watermarking of Audio Generative Models
Sep 04, 2024



The advancements in audio generative models have opened up new challenges in their responsible disclosure and the detection of their misuse. In response, we introduce a method to watermark latent generative models by a specific watermarking of their training data. The resulting watermarked models produce latent representations whose decoded outputs are detected with high confidence, regardless of the decoding method used. This approach enables the detection of the generated content without the need for a post-hoc watermarking step. It provides a more secure solution for open-sourced models and facilitates the identification of derivative works that fine-tune or use these models without adhering to their license terms. Our results indicate for instance that generated outputs are detected with an accuracy of more than 75% at a false positive rate of $10^{-3}$, even after fine-tuning the latent generative model.
Proactive Detection of Voice Cloning with Localized Watermarking
Jan 30, 2024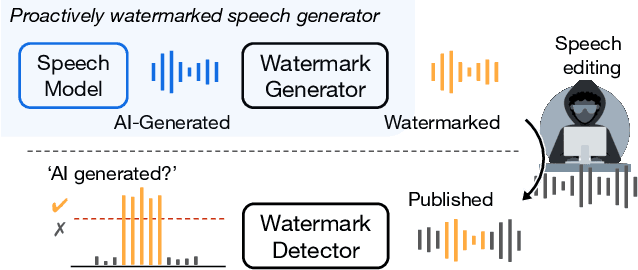
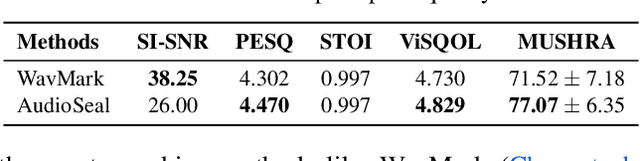
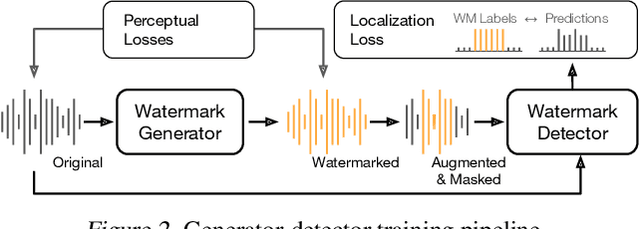
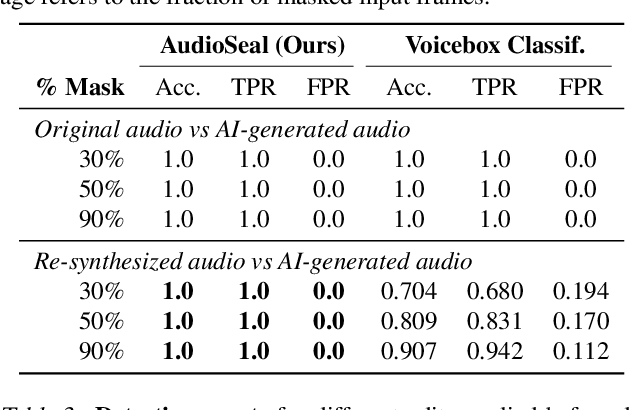
In the rapidly evolving field of speech generative models, there is a pressing need to ensure audio authenticity against the risks of voice cloning. We present AudioSeal, the first audio watermarking technique designed specifically for localized detection of AI-generated speech. AudioSeal employs a generator/detector architecture trained jointly with a localization loss to enable localized watermark detection up to the sample level, and a novel perceptual loss inspired by auditory masking, that enables AudioSeal to achieve better imperceptibility. AudioSeal achieves state-of-the-art performance in terms of robustness to real life audio manipulations and imperceptibility based on automatic and human evaluation metrics. Additionally, AudioSeal is designed with a fast, single-pass detector, that significantly surpasses existing models in speed - achieving detection up to two orders of magnitude faster, making it ideal for large-scale and real-time applications.
Seamless: Multilingual Expressive and Streaming Speech Translation
Dec 08, 2023



Large-scale automatic speech translation systems today lack key features that help machine-mediated communication feel seamless when compared to human-to-human dialogue. In this work, we introduce a family of models that enable end-to-end expressive and multilingual translations in a streaming fashion. First, we contribute an improved version of the massively multilingual and multimodal SeamlessM4T model-SeamlessM4T v2. This newer model, incorporating an updated UnitY2 framework, was trained on more low-resource language data. SeamlessM4T v2 provides the foundation on which our next two models are initiated. SeamlessExpressive enables translation that preserves vocal styles and prosody. Compared to previous efforts in expressive speech research, our work addresses certain underexplored aspects of prosody, such as speech rate and pauses, while also preserving the style of one's voice. As for SeamlessStreaming, our model leverages the Efficient Monotonic Multihead Attention mechanism to generate low-latency target translations without waiting for complete source utterances. As the first of its kind, SeamlessStreaming enables simultaneous speech-to-speech/text translation for multiple source and target languages. To ensure that our models can be used safely and responsibly, we implemented the first known red-teaming effort for multimodal machine translation, a system for the detection and mitigation of added toxicity, a systematic evaluation of gender bias, and an inaudible localized watermarking mechanism designed to dampen the impact of deepfakes. Consequently, we bring major components from SeamlessExpressive and SeamlessStreaming together to form Seamless, the first publicly available system that unlocks expressive cross-lingual communication in real-time. The contributions to this work are publicly released and accessible at https://github.com/facebookresearch/seamless_communication
From Discrete Tokens to High-Fidelity Audio Using Multi-Band Diffusion
Aug 02, 2023
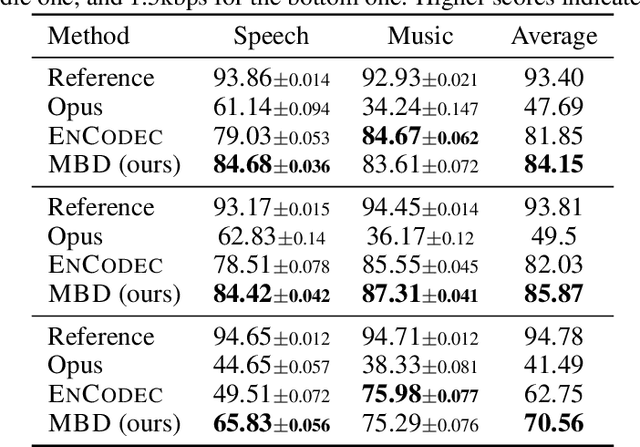

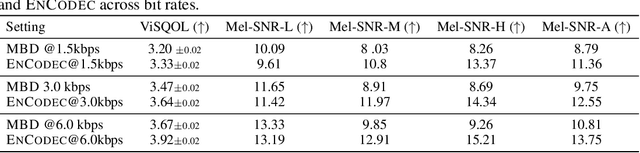
Deep generative models can generate high-fidelity audio conditioned on various types of representations (e.g., mel-spectrograms, Mel-frequency Cepstral Coefficients (MFCC)). Recently, such models have been used to synthesize audio waveforms conditioned on highly compressed representations. Although such methods produce impressive results, they are prone to generate audible artifacts when the conditioning is flawed or imperfect. An alternative modeling approach is to use diffusion models. However, these have mainly been used as speech vocoders (i.e., conditioned on mel-spectrograms) or generating relatively low sampling rate signals. In this work, we propose a high-fidelity multi-band diffusion-based framework that generates any type of audio modality (e.g., speech, music, environmental sounds) from low-bitrate discrete representations. At equal bit rate, the proposed approach outperforms state-of-the-art generative techniques in terms of perceptual quality. Training and, evaluation code, along with audio samples, are available on the facebookresearch/audiocraft Github page.
Denoising Diffusion Gamma Models
Oct 10, 2021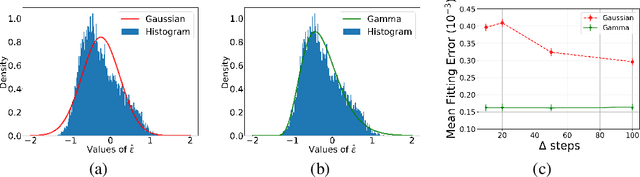
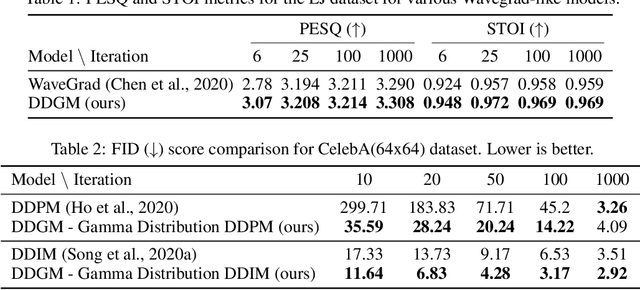
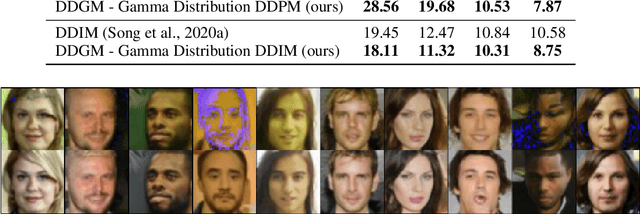
Generative diffusion processes are an emerging and effective tool for image and speech generation. In the existing methods, the underlying noise distribution of the diffusion process is Gaussian noise. However, fitting distributions with more degrees of freedom could improve the performance of such generative models. In this work, we investigate other types of noise distribution for the diffusion process. Specifically, we introduce the Denoising Diffusion Gamma Model (DDGM) and show that noise from Gamma distribution provides improved results for image and speech generation. Our approach preserves the ability to efficiently sample state in the training diffusion process while using Gamma noise.
Non Gaussian Denoising Diffusion Models
Jun 14, 2021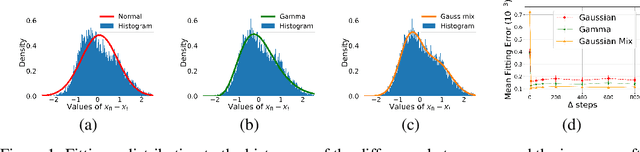

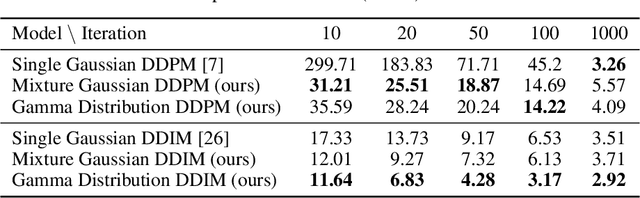

Generative diffusion processes are an emerging and effective tool for image and speech generation. In the existing methods, the underline noise distribution of the diffusion process is Gaussian noise. However, fitting distributions with more degrees of freedom, could help the performance of such generative models. In this work, we investigate other types of noise distribution for the diffusion process. Specifically, we show that noise from Gamma distribution provides improved results for image and speech generation. Moreover, we show that using a mixture of Gaussian noise variables in the diffusion process improves the performance over a diffusion process that is based on a single distribution. Our approach preserves the ability to efficiently sample state in the training diffusion process while using Gamma noise and a mixture of noise.