 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUPER -- A Framework for Sensitivity-based Uncertainty-aware Performance and Risk Assessment in Visual Inertial Odometry
Dec 16, 2025While many visual odometry (VO), visual-inertial odometry (VIO), and SLAM systems achieve high accuracy, the majority of existing methods miss to assess risks at runtime. This paper presents SUPER (Sensitivity-based Uncertainty-aware PErformance and Risk assessment) that is a generic and explainable framework that propagates uncertainties via sensitivities for real-time risk assessment in VIO. The scientific novelty lies in the derivation of a real-time risk indicator that is backend-agnostic and exploits the Schur complement blocks of the Gauss-Newton normal matrix to propagate uncertainties. Practically, the Schur complement captures the sensitivity that reflects the influence of the uncertainty on the risk occurrence. Our framework estimates risks on the basis of the residual magnitudes, geometric conditioning, and short horizon temporal trends without requiring ground truth knowledge. Our framework enables to reliably predict trajectory degradation 50 frames ahead with an improvement of 20% to the baseline. In addition, SUPER initiates a stop or relocalization policy with 89.1% recall. The framework is backend agnostic and operates in real time with less than 0.2% additional CPU cost. Experiments show that SUPER provides consistent uncertainty estimates. A SLAM evaluation highlights the applicability to long horizon mapping.
Identifying Policy Gradient Subspaces
Jan 15, 2024Policy gradient methods hold great potential for solving complex continuous control tasks. Still, their training efficiency can be improved by exploiting structure within the optimization problem. Recent work indicates that supervised learning can be accelerated by leveraging the fact that gradients lie in a low-dimensional and slowly-changing subspace. In this paper, we conduct a thorough evaluation of this phenomenon for two popular deep policy gradient methods on various simulated benchmark tasks. Our results demonstrate the existence of such gradient subspaces despite the continuously changing data distribution inherent to reinforcement learning. These findings reveal promising directions for future work on more efficient reinforcement learning, e.g., through improving parameter-space exploration or enabling second-order optimization.
Investigating the Impact of Action Representations in Policy Gradient Algorithms
Sep 13, 2023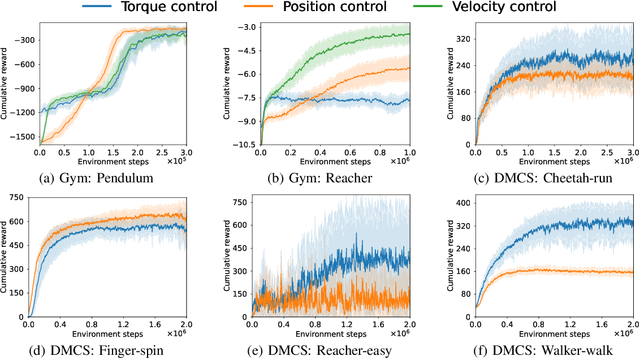
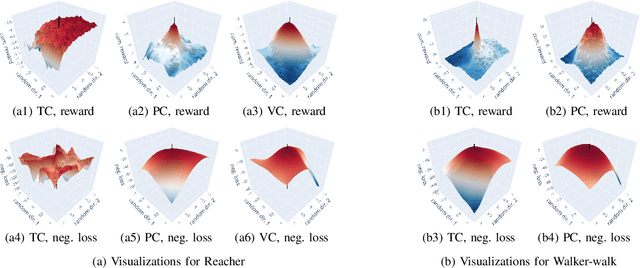
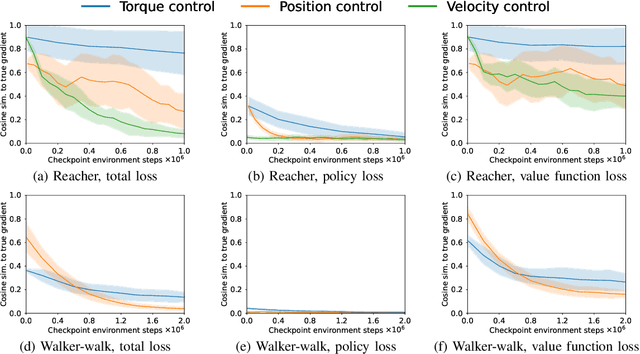
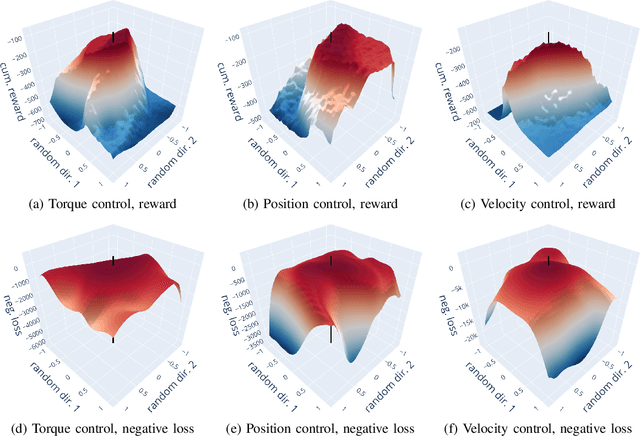
Reinforcement learning~(RL) is a versatile framework for learning to solve complex real-world tasks. However, influences on the learning performance of RL algorithms are often poorly understood in practice. We discuss different analysis techniques and assess their effectiveness for investigating the impact of action representations in RL. Our experiments demonstrate that the action representation can significantly influence the learning performance on popular RL benchmark tasks. The analysis results indicate that some of the performance differences can be attributed to changes in the complexity of the optimization landscape. Finally, we discuss open challenges of analysis techniques for RL algorithms.
DEP-RL: Embodied Exploration for Reinforcement Learning in Overactuated and Musculoskeletal Systems
May 30, 2022



Muscle-actuated organisms are capable of learning an unparalleled diversity of dexterous movements despite their vast amount of muscles. Reinforcement learning (RL) on large musculoskeletal models, however, has not been able to show similar performance. We conjecture that ineffective exploration in large overactuated action spaces is a key problem. This is supported by the finding that common exploration noise strategies are inadequate in synthetic examples of overactuated systems. We identify differential extrinsic plasticity (DEP), a method from the domain of self-organization, as being able to induce state-space covering exploration within seconds of interaction. By integrating DEP into RL, we achieve fast learning of reaching and locomotion in musculoskeletal systems, outperforming current approaches in all considered tasks in sample efficiency and robustness.