 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRP1M: A Large-Scale Motion Dataset for Piano Playing with Bi-Manual Dexterous Robot Hands
Aug 20, 2024



It has been a long-standing research goal to endow robot hands with human-level dexterity. Bi-manual robot piano playing constitutes a task that combines challenges from dynamic tasks, such as generating fast while precise motions, with slower but contact-rich manipulation problems. Although reinforcement learning based approaches have shown promising results in single-task performance, these methods struggle in a multi-song setting. Our work aims to close this gap and, thereby, enable imitation learning approaches for robot piano playing at scale. To this end, we introduce the Robot Piano 1 Million (RP1M) dataset, containing bi-manual robot piano playing motion data of more than one million trajectories. We formulate finger placements as an optimal transport problem, thus, enabling automatic annotation of vast amounts of unlabeled songs. Benchmarking existing imitation learning approaches shows that such approaches reach state-of-the-art robot piano playing performance by leveraging RP1M.
Learning to Control Emulated Muscles in Real Robots: Towards Exploiting Bio-Inspired Actuator Morphology
Feb 08, 2024Recent studies have demonstrated the immense potential of exploiting muscle actuator morphology for natural and robust movement -- in simulation. A validation on real robotic hardware is yet missing. In this study, we emulate muscle actuator properties on hardware in real-time, taking advantage of modern and affordable electric motors. We demonstrate that our setup can emulate a simplified muscle model on a real robot while being controlled by a learned policy. We improve upon an existing muscle model by deriving a damping rule that ensures that the model is not only performant and stable but also tuneable for the real hardware. Our policies are trained by reinforcement learning entirely in simulation, where we show that previously reported benefits of muscles extend to the case of quadruped locomotion and hopping: the learned policies are more robust and exhibit more regular gaits. Finally, we confirm that the learned policies can be executed on real hardware and show that sim-to-real transfer with real-time emulated muscles on a quadruped robot is possible. These results show that artificial muscles can be highly beneficial actuators for future generations of robust legged robots.
Identifying Policy Gradient Subspaces
Jan 15, 2024Policy gradient methods hold great potential for solving complex continuous control tasks. Still, their training efficiency can be improved by exploiting structure within the optimization problem. Recent work indicates that supervised learning can be accelerated by leveraging the fact that gradients lie in a low-dimensional and slowly-changing subspace. In this paper, we conduct a thorough evaluation of this phenomenon for two popular deep policy gradient methods on various simulated benchmark tasks. Our results demonstrate the existence of such gradient subspaces despite the continuously changing data distribution inherent to reinforcement learning. These findings reveal promising directions for future work on more efficient reinforcement learning, e.g., through improving parameter-space exploration or enabling second-order optimization.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Investigating the Impact of Action Representations in Policy Gradient Algorithms
Sep 13, 2023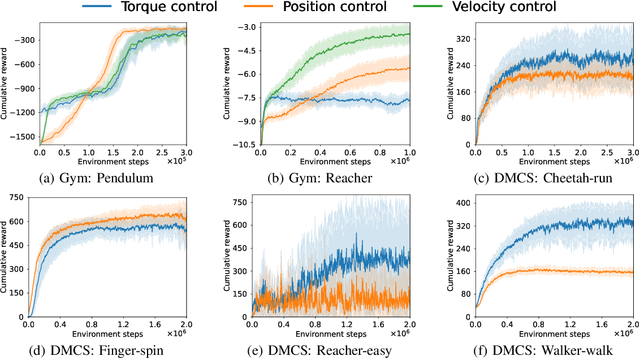
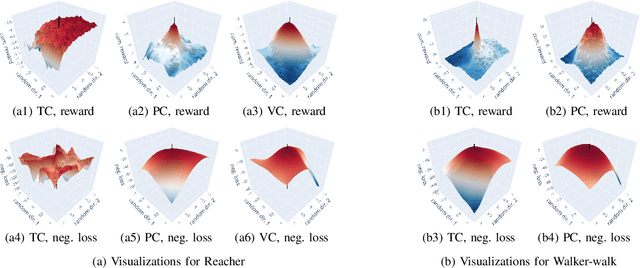
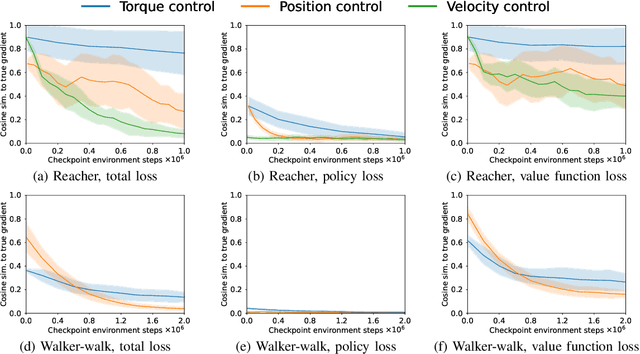
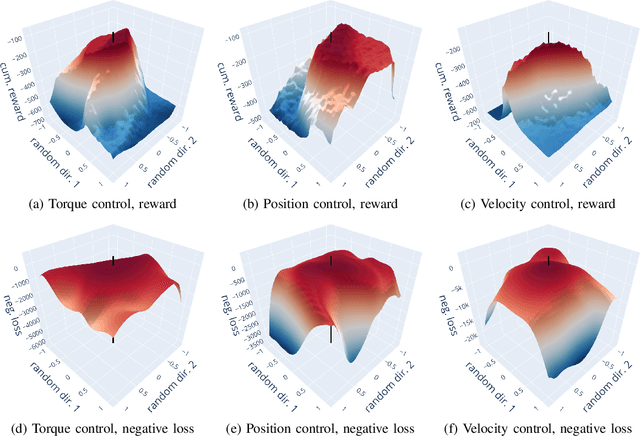
Reinforcement learning~(RL) is a versatile framework for learning to solve complex real-world tasks. However, influences on the learning performance of RL algorithms are often poorly understood in practice. We discuss different analysis techniques and assess their effectiveness for investigating the impact of action representations in RL. Our experiments demonstrate that the action representation can significantly influence the learning performance on popular RL benchmark tasks. The analysis results indicate that some of the performance differences can be attributed to changes in the complexity of the optimization landscape. Finally, we discuss open challenges of analysis techniques for RL algorithms.
A Robust Open-source Tendon-driven Robot Arm for Learning Control of Dynamic Motions
Jul 10, 2023



A long-lasting goal of robotics research is to operate robots safely, while achieving high performance which often involves fast motions. Traditional motor-driven systems frequently struggle to balance these competing demands. Addressing this trade-off is crucial for advancing fields such as manufacturing and healthcare, where seamless collaboration between robots and humans is essential. We introduce a four degree-of-freedom (DoF) tendon-driven robot arm, powered by pneumatic artificial muscles (PAMs), to tackle this challenge. Our new design features low friction, passive compliance, and inherent impact resilience, enabling rapid, precise, high-force, and safe interactions during dynamic tasks. In addition to fostering safer human-robot collaboration, the inherent safety properties are particularly beneficial for reinforcement learning, where the robot's ability to explore dynamic motions without causing self-damage is crucial. We validate our robotic arm through various experiments, including long-term dynamic motions, impact resilience tests, and assessments of its ease of control. On a challenging dynamic table tennis task, we further demonstrate our robot's capabilities in rapid and precise movements. By showcasing our new design's potential, we aim to inspire further research on robotic systems that balance high performance and safety in diverse tasks. Our open-source hardware design, software, and a large dataset of diverse robot motions can be found at https://webdav.tuebingen.mpg.de/pamy2/.
Hindsight States: Blending Sim and Real Task Elements for Efficient Reinforcement Learning
Mar 09, 2023Reinforcement learning has shown great potential in solving complex tasks when large amounts of data can be generated with little effort. In robotics, one approach to generate training data builds on simulations based on dynamics models derived from first principles. However, for tasks that, for instance, involve complex soft robots, devising such models is substantially more challenging. Being able to train effectively in increasingly complicated scenarios with reinforcement learning enables to take advantage of complex systems such as soft robots. Here, we leverage the imbalance in complexity of the dynamics to learn more sample-efficiently. We (i) abstract the task into distinct components, (ii) off-load the simple dynamics parts into the simulation, and (iii) multiply these virtual parts to generate more data in hindsight. Our new method, Hindsight States (HiS), uses this data and selects the most useful transitions for training. It can be used with an arbitrary off-policy algorithm. We validate our method on several challenging simulated tasks and demonstrate that it improves learning both alone and when combined with an existing hindsight algorithm, Hindsight Experience Replay (HER). Finally, we evaluate HiS on a physical system and show that it boosts performance on a complex table tennis task with a muscular robot. Videos and code of the experiments can be found on webdav.tuebingen.mpg.de/his/.
AIMY: An Open-source Table Tennis Ball Launcher for Versatile and High-fidelity Trajectory Generation
Oct 13, 2022

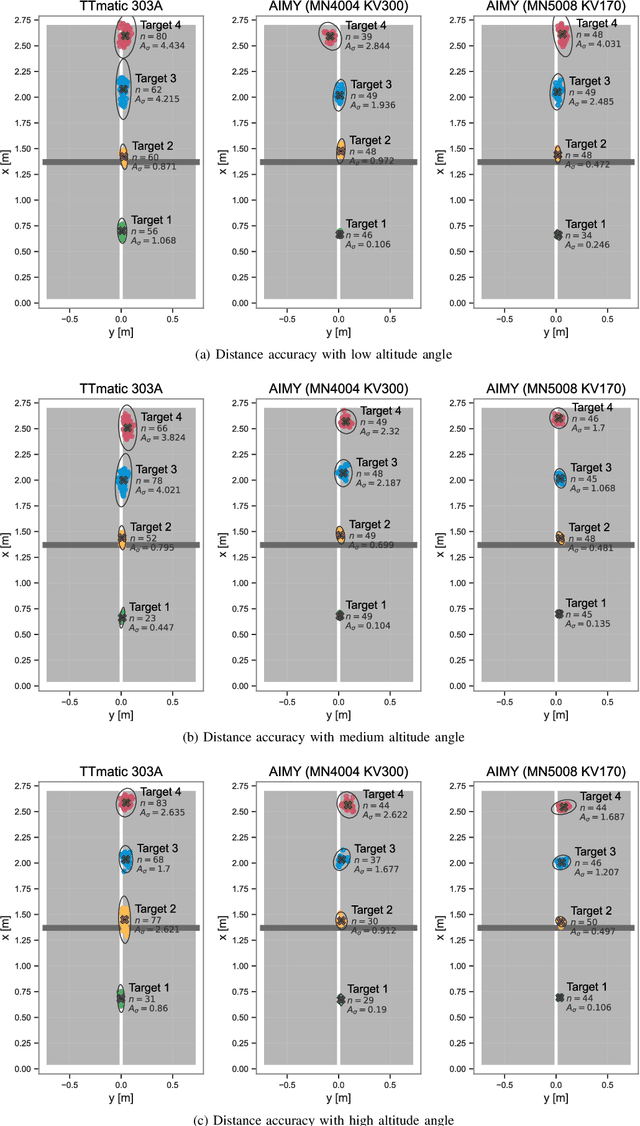
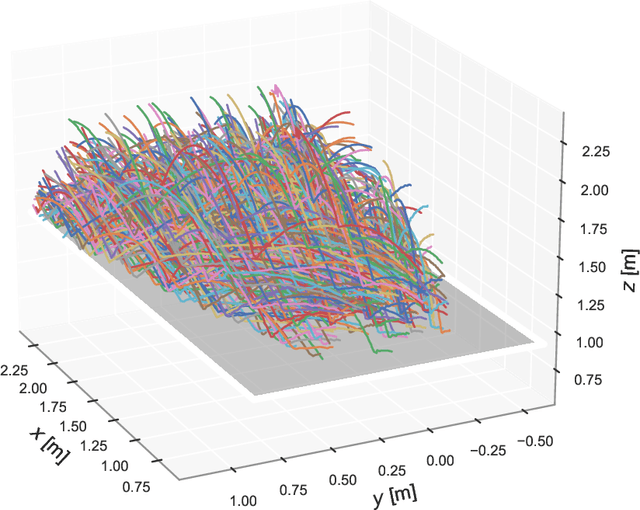
To approach the level of advanced human players in table tennis with robots, generating varied ball trajectories in a reproducible and controlled manner is essential. Current ball launchers used in robot table tennis either do not provide an interface for automatic control or are limited in their capabilities to adapt speed, direction, and spin of the ball. For these reasons, we present AIMY, a three-wheeled open-hardware and open-source table tennis ball launcher, which can generate ball speeds and spins of up to 15.44 m/s and 192/s, respectively, which are comparable to advanced human players. The wheel speeds, launch orientation and time can be fully controlled via an open Ethernet or Wi-Fi interface. We provide a detailed overview of the core design features, as well as open source the software to encourage distribution and duplication within and beyond the robot table tennis research community. We also extensively evaluate the ball launcher's accuracy for different system settings and learn to launch a ball to desired locations. With this ball launcher, we enable long-duration training of robot table tennis approaches where the complexity of the ball trajectory can be automatically adjusted, enabling large-scale real-world online reinforcement learning for table tennis robots.