 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Slowness in Central Vision Drives Semantic Object Learning
Feb 04, 2026Humans acquire semantic object representations from egocentric visual streams with minimal supervision. Importantly, the visual system processes with high resolution only the center of its field of view and learns similar representations for visual inputs occurring close in time. This emphasizes slowly changing information around gaze locations. This study investigates the role of central vision and slowness learning in the formation of semantic object representations from human-like visual experience. We simulate five months of human-like visual experience using the Ego4D dataset and generate gaze coordinates with a state-of-the-art gaze prediction model. Using these predictions, we extract crops that mimic central vision and train a time-contrastive Self-Supervised Learning model on them. Our results show that combining temporal slowness and central vision improves the encoding of different semantic facets of object representations. Specifically, focusing on central vision strengthens the extraction of foreground object features, while considering temporal slowness, especially during fixational eye movements, allows the model to encode broader semantic information about objects. These findings provide new insights into the mechanisms by which humans may develop semantic object representations from natural visual experience.
Human Gaze Boosts Object-Centered Representation Learning
Jan 06, 2025Recent self-supervised learning (SSL) models trained on human-like egocentric visual inputs substantially underperform on image recognition tasks compared to humans. These models train on raw, uniform visual inputs collected from head-mounted cameras. This is different from humans, as the anatomical structure of the retina and visual cortex relatively amplifies the central visual information, i.e. around humans' gaze location. This selective amplification in humans likely aids in forming object-centered visual representations. Here, we investigate whether focusing on central visual information boosts egocentric visual object learning. We simulate 5-months of egocentric visual experience using the large-scale Ego4D dataset and generate gaze locations with a human gaze prediction model. To account for the importance of central vision in humans, we crop the visual area around the gaze location. Finally, we train a time-based SSL model on these modified inputs. Our experiments demonstrate that focusing on central vision leads to better object-centered representations. Our analysis shows that the SSL model leverages the temporal dynamics of the gaze movements to build stronger visual representations. Overall, our work marks a significant step toward bio-inspired learning of visual representations.
Caregiver Talk Shapes Toddler Vision: A Computational Study of Dyadic Play
Dec 07, 2023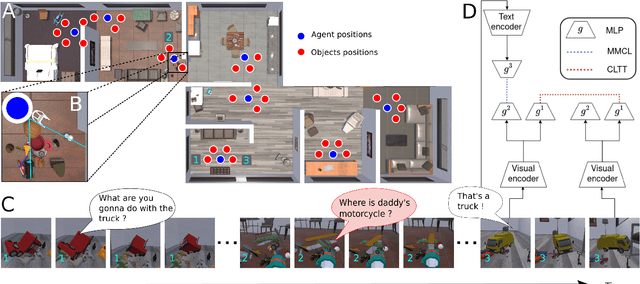
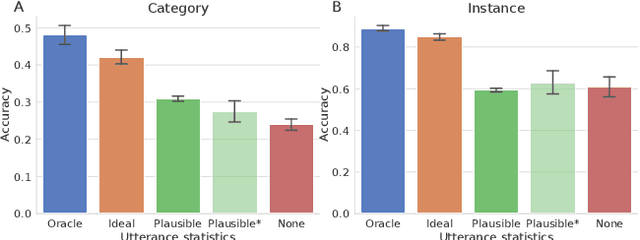
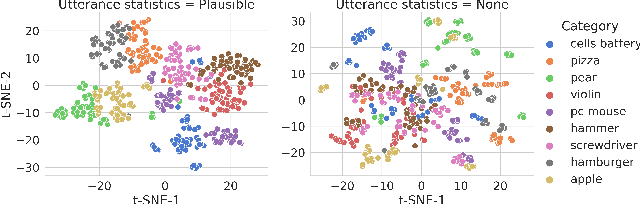
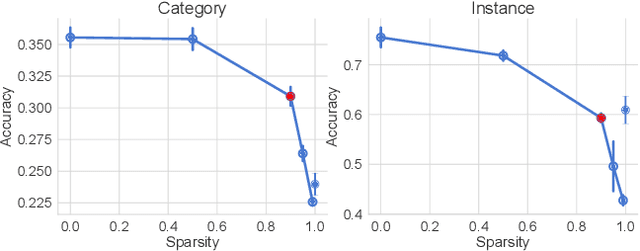
Infants' ability to recognize and categorize objects develops gradually. The second year of life is marked by both the emergence of more semantic visual representations and a better understanding of word meaning. This suggests that language input may play an important role in shaping visual representations. However, even in suitable contexts for word learning like dyadic play sessions, caregivers utterances are sparse and ambiguous, often referring to objects that are different from the one to which the child attends. Here, we systematically investigate to what extent caregivers' utterances can nevertheless enhance visual representations. For this we propose a computational model of visual representation learning during dyadic play. We introduce a synthetic dataset of ego-centric images perceived by a toddler-agent that moves and rotates toy objects in different parts of its home environment while hearing caregivers' utterances, modeled as captions. We propose to model toddlers' learning as simultaneously aligning representations for 1) close-in-time images and 2) co-occurring images and utterances. We show that utterances with statistics matching those of real caregivers give rise to representations supporting improved category recognition. Our analysis reveals that a small decrease/increase in object-relevant naming frequencies can drastically impact the learned representations. This affects the attention on object names within an utterance, which is required for efficient visuo-linguistic alignment. Overall, our results support the hypothesis that caregivers' naming utterances can improve toddlers' visual representations.
Analyzing Vision Transformers for Image Classification in Class Embedding Space
Oct 29, 2023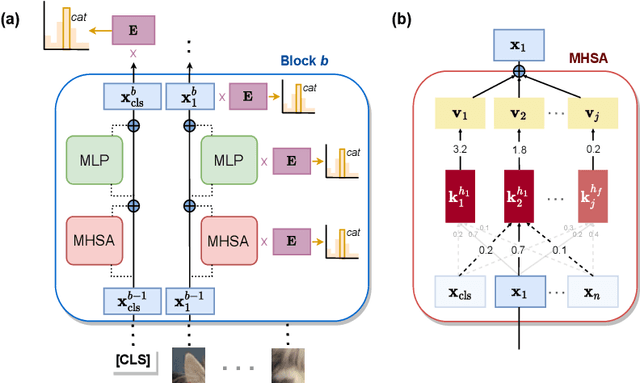

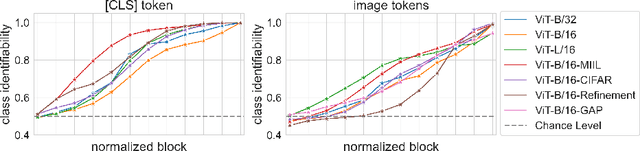

Despite the growing use of transformer models in computer vision, a mechanistic understanding of these networks is still needed. This work introduces a method to reverse-engineer Vision Transformers trained to solve image classification tasks. Inspired by previous research in NLP, we demonstrate how the inner representations at any level of the hierarchy can be projected onto the learned class embedding space to uncover how these networks build categorical representations for their predictions. We use our framework to show how image tokens develop class-specific representations that depend on attention mechanisms and contextual information, and give insights on how self-attention and MLP layers differentially contribute to this categorical composition. We additionally demonstrate that this method (1) can be used to determine the parts of an image that would be important for detecting the class of interest, and (2) exhibits significant advantages over traditional linear probing approaches. Taken together, our results position our proposed framework as a powerful tool for mechanistic interpretability and explainability research.