 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord-level Sign Language Recognition with Multi-stream Neural Networks Focusing on Local Regions
Paper and Code
Jun 30, 2021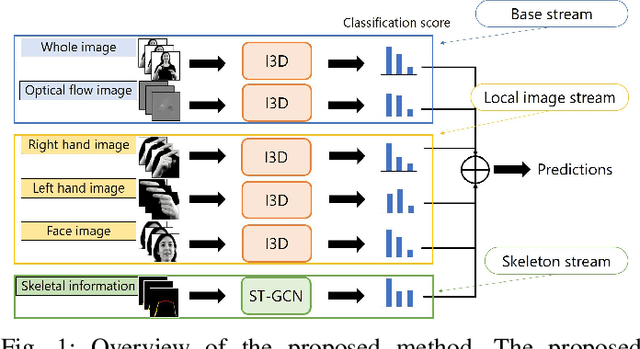
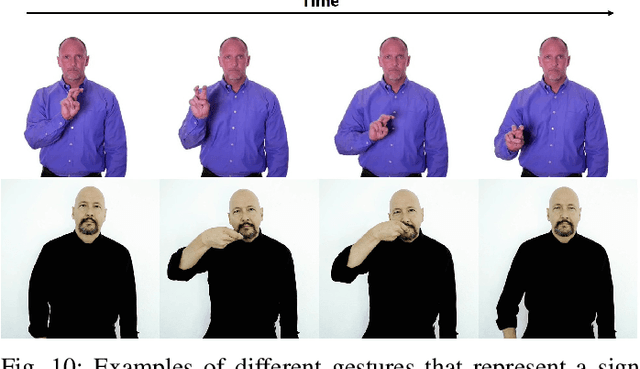
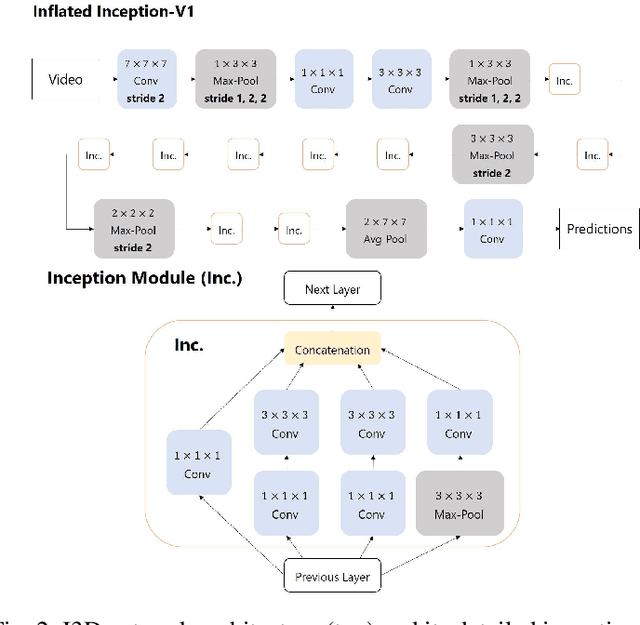
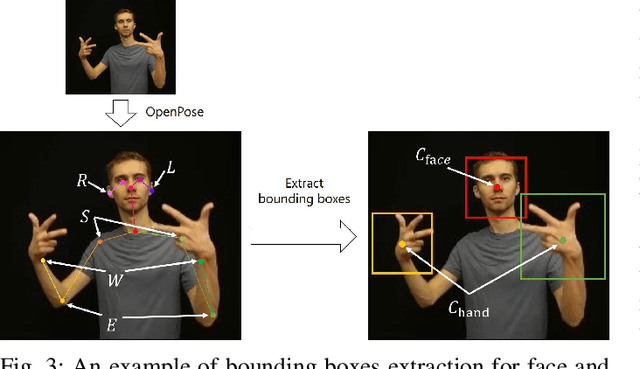
In recent years, Word-level Sign Language Recognition (WSLR) research has gained popularity in the computer vision community, and thus various approaches have been proposed. Among these approaches, the method using I3D network achieves the highest recognition accuracy on large public datasets for WSLR. However, the method with I3D only utilizes appearance information of the upper body of the signers to recognize sign language words. On the other hand, in WSLR, the information of local regions, such as the hand shape and facial expression, and the positional relationship among the body and both hands are important. Thus in this work, we utilized local region images of both hands and face, along with skeletal information to capture local information and the positions of both hands relative to the body, respectively. In other words, we propose a novel multi-stream WSLR framework, in which a stream with local region images and a stream with skeletal information are introduced by extending I3D network to improve the recognition accuracy of WSLR. From the experimental results on WLASL dataset, it is evident that the proposed method has achieved about 15% improvement in the Top-1 accuracy than the existing conventional methods.