Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText Line Identification in Tagore's Manuscript
Paper and Code
Aug 18, 2016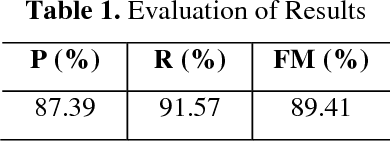

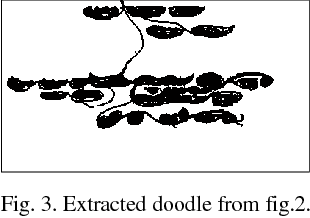
In this paper, a text line identification method is proposed. The text lines of printed document are easy to segment due to uniform straightness of the lines and sufficient gap between the lines. But in handwritten documents, the line is non-uniform and interline gaps are variable. We take Rabindranath Tagore's manuscript as it is one of the most difficult manuscripts that contain doodles. Our method consists of a pre-processing stage to clean the document image. Then we separate doodles from the manuscript to get the textual region. After that we identify the text lines on the manuscript. For text line identification, we use window examination, black run-length smearing, horizontal histogram and connected component analysis.
* Proc. IEEE TechSym-2014, IEEE Conf. #32812, pp. 210-213,
Kharagpur, India, 28 Feb.-2 Mar., 2014
View paper on