 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-GRPO: Stabilizing Multi-Agent Topology Learning via Group Relative Policy Optimization
Mar 03, 2026Optimizing communication topology is fundamental to the efficiency and effectiveness of Large Language Model (LLM)-based Multi-Agent Systems (MAS). While recent approaches utilize reinforcement learning to dynamically construct task-specific graphs, they typically rely on single-sample policy gradients with absolute rewards (e.g., binary correctness). This paradigm suffers from severe gradient variance and the credit assignment problem: simple queries yield non-informative positive rewards for suboptimal structures, while difficult queries often result in failures that provide no learning signal. To address these challenges, we propose Graph-GRPO, a novel topology optimization framework that integrates Group Relative Policy Optimization. Instead of evaluating a single topology in isolation, Graph-GRPO samples a group of diverse communication graphs for each query and computes the advantage of specific edges based on their relative performance within the group. By normalizing rewards across the sampled group, our method effectively mitigates the noise derived from task difficulty variance and enables fine-grained credit assignment. Extensive experiments on reasoning and code generation benchmarks demonstrate that Graph-GRPO significantly outperforms state-of-the-art baselines, achieving superior training stability and identifying critical communication pathways previously obscured by reward noise.
Intelligent Pathological Diagnosis of Gestational Trophoblastic Diseases via Visual-Language Deep Learning Model
Mar 03, 2026The pathological diagnosis of gestational trophoblastic disease(GTD) takes a long time, relies heavily on the experience of pathologists, and the consistency of initial diagnosis is low, which seriously threatens maternal health and reproductive outcomes. We developed an expert model for GTD pathological diagnosis, named GTDoctor. GTDoctor can perform pixel-based lesion segmentation on pathological slides, and output diagnostic conclusions and personalized pathological analysis results. We developed a software system, GTDiagnosis, based on this technology and conducted clinical trials. The retrospective results demonstrated that GTDiagnosis achieved a mean precision of over 0.91 for lesion detection in pathological slides (n=679 slides). In prospective studies, pathologists using GTDiagnosis attained a Positive Predictive Value of 95.59% (n=68 patients). The tool reduced average diagnostic time from 56 to 16 seconds per case (n=285 patients). GTDoctor and GTDiagnosis offer a novel solution for GTD pathological diagnosis, enhancing diagnostic performance and efficiency while maintaining clinical interpretability.
DINT Transformer
Jan 29, 2025DIFF Transformer addresses the issue of irrelevant context interference by introducing a differential attention mechanism that enhances the robustness of local attention. However, it has two critical limitations: the lack of global context modeling, which is essential for identifying globally significant tokens, and numerical instability due to the absence of strict row normalization in the attention matrix. To overcome these challenges, we propose DINT Transformer, which extends DIFF Transformer by incorporating a differential-integral mechanism. By computing global importance scores and integrating them into the attention matrix, DINT Transformer improves its ability to capture global dependencies. Moreover, the unified parameter design enforces row-normalized attention matrices, improving numerical stability. Experimental results demonstrate that DINT Transformer excels in accuracy and robustness across various practical applications, such as long-context language modeling and key information retrieval. These results position DINT Transformer as a highly effective and promising architecture.
Shared DIFF Transformer
Jan 29, 2025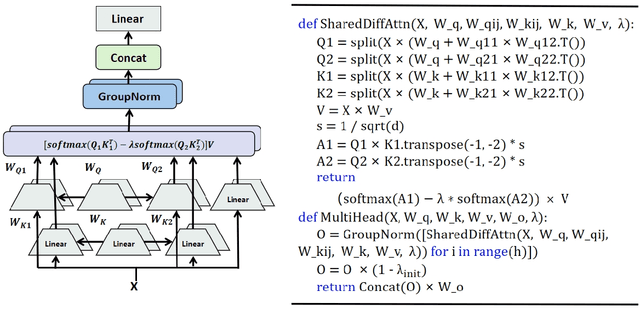
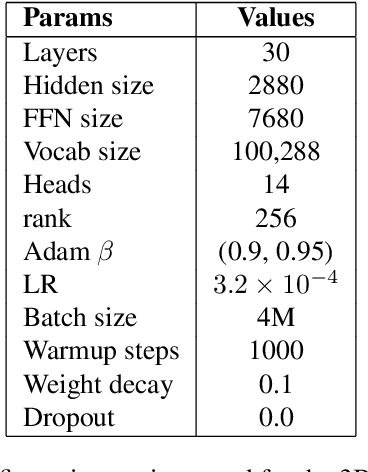
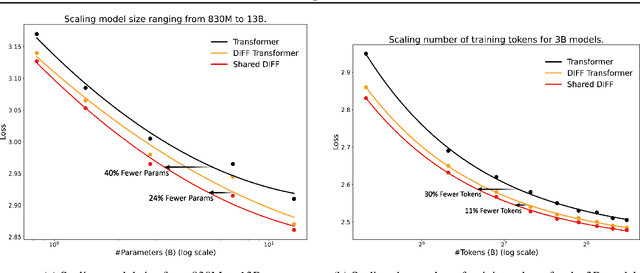
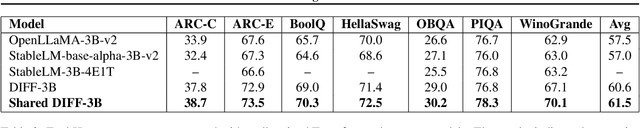
DIFF Transformer improves attention allocation by enhancing focus on relevant context while suppressing noise. It introduces a differential attention mechanism that calculates the difference between two independently generated attention distributions, effectively reducing noise and promoting sparse attention patterns. However, the independent signal generation in DIFF Transformer results in parameter redundancy and suboptimal utilization of information. In this work, we propose Shared DIFF Transformer, which draws on the idea of a differential amplifier by introducing a shared base matrix to model global patterns and incorporating low-rank updates to enhance task-specific flexibility. This design significantly reduces parameter redundancy, improves efficiency, and retains strong noise suppression capabilities. Experimental results show that, compared to DIFF Transformer, our method achieves better performance in tasks such as long-sequence modeling, key information retrieval, and in-context learning. Our work provides a novel and efficient approach to optimizing differential attention mechanisms and advancing robust Transformer architectures.
Can KAN Work? Exploring the Potential of Kolmogorov-Arnold Networks in Computer Vision
Nov 14, 2024Kolmogorov-Arnold Networks(KANs), as a theoretically efficient neural network architecture, have garnered attention for their potential in capturing complex patterns. However, their application in computer vision remains relatively unexplored. This study first analyzes the potential of KAN in computer vision tasks, evaluating the performance of KAN and its convolutional variants in image classification and semantic segmentation. The focus is placed on examining their characteristics across varying data scales and noise levels. Results indicate that while KAN exhibits stronger fitting capabilities, it is highly sensitive to noise, limiting its robustness. To address this challenge, we propose a smoothness regularization method and introduce a Segment Deactivation technique. Both approaches enhance KAN's stability and generalization, demonstrating its potential in handling complex visual data tasks.
RetCompletion:High-Speed Inference Image Completion with Retentive Network
Oct 05, 2024



Time cost is a major challenge in achieving high-quality pluralistic image completion. Recently, the Retentive Network (RetNet) in natural language processing offers a novel approach to this problem with its low-cost inference capabilities. Inspired by this, we apply RetNet to the pluralistic image completion task in computer vision. We present RetCompletion, a two-stage framework. In the first stage, we introduce Bi-RetNet, a bidirectional sequence information fusion model that integrates contextual information from images. During inference, we employ a unidirectional pixel-wise update strategy to restore consistent image structures, achieving both high reconstruction quality and fast inference speed. In the second stage, we use a CNN for low-resolution upsampling to enhance texture details. Experiments on ImageNet and CelebA-HQ demonstrate that our inference speed is 10$\times$ faster than ICT and 15$\times$ faster than RePaint. The proposed RetCompletion significantly improves inference speed and delivers strong performance, especially when masks cover large areas of the image.