 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAG-Gym: Optimizing Reasoning and Search Agents with Process Supervision
Feb 19, 2025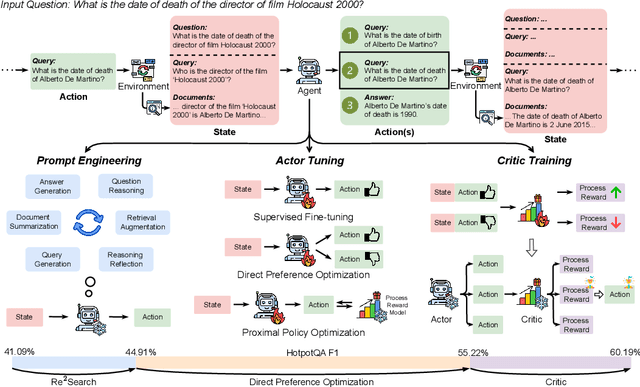

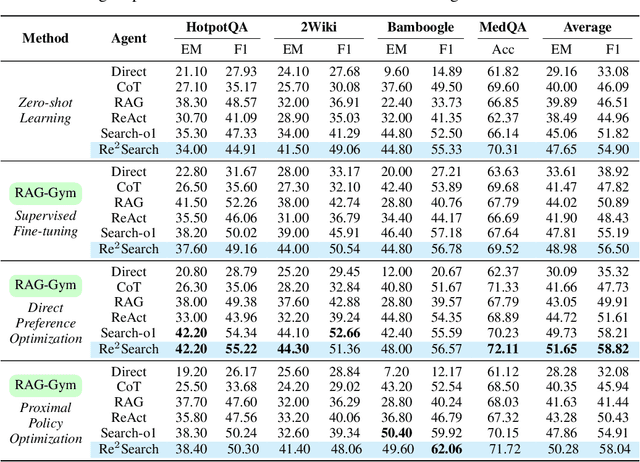
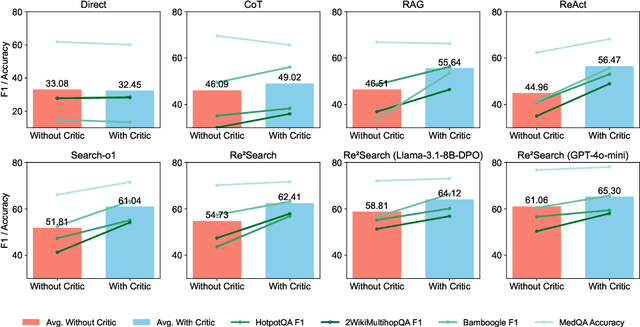
Retrieval-augmented generation (RAG) has shown great potential for knowledge-intensive tasks, but its traditional architectures rely on static retrieval, limiting their effectiveness for complex questions that require sequential information-seeking. While agentic reasoning and search offer a more adaptive approach, most existing methods depend heavily on prompt engineering. In this work, we introduce RAG-Gym, a unified optimization framework that enhances information-seeking agents through fine-grained process supervision at each search step. We also propose ReSearch, a novel agent architecture that synergizes answer reasoning and search query generation within the RAG-Gym framework. Experiments on four challenging datasets show that RAG-Gym improves performance by up to 25.6\% across various agent architectures, with ReSearch consistently outperforming existing baselines. Further analysis highlights the effectiveness of advanced LLMs as process reward judges and the transferability of trained reward models as verifiers for different LLMs. Additionally, we examine the scaling properties of training and inference in agentic RAG. The project homepage is available at https://rag-gym.github.io/.
Hidden Flaws Behind Expert-Level Accuracy of GPT-4 Vision in Medicine
Jan 24, 2024Recent studies indicate that Generative Pre-trained Transformer 4 with Vision (GPT-4V) outperforms human physicians in medical challenge tasks. However, these evaluations primarily focused on the accuracy of multi-choice questions alone. Our study extends the current scope by conducting a comprehensive analysis of GPT-4V's rationales of image comprehension, recall of medical knowledge, and step-by-step multimodal reasoning when solving New England Journal of Medicine (NEJM) Image Challenges - an imaging quiz designed to test the knowledge and diagnostic capabilities of medical professionals. Evaluation results confirmed that GPT-4V outperforms human physicians regarding multi-choice accuracy (88.0% vs. 77.0%, p=0.034). GPT-4V also performs well in cases where physicians incorrectly answer, with over 80% accuracy. However, we discovered that GPT-4V frequently presents flawed rationales in cases where it makes the correct final choices (27.3%), most prominent in image comprehension (21.6%). Regardless of GPT-4V's high accuracy in multi-choice questions, our findings emphasize the necessity for further in-depth evaluations of its rationales before integrating such models into clinical workflows.