 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOld can be Gold: Better Gradient Flow can Make Vanilla-GCNs Great Again
Paper and Code
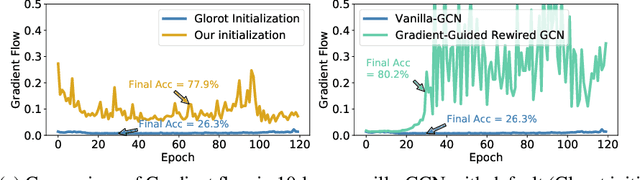

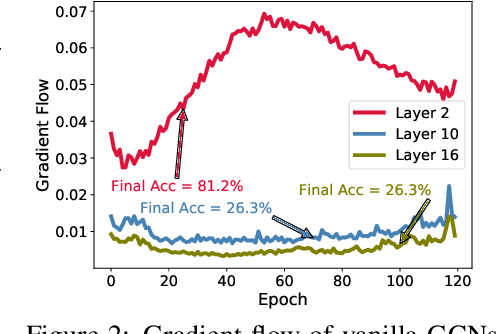
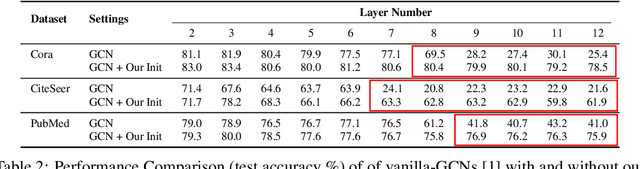
Despite the enormous success of Graph Convolutional Networks (GCNs) in modeling graph-structured data, most of the current GCNs are shallow due to the notoriously challenging problems of over-smoothening and information squashing along with conventional difficulty caused by vanishing gradients and over-fitting. Previous works have been primarily focused on the study of over-smoothening and over-squashing phenomena in training deep GCNs. Surprisingly, in comparison with CNNs/RNNs, very limited attention has been given to understanding how healthy gradient flow can benefit the trainability of deep GCNs. In this paper, firstly, we provide a new perspective of gradient flow to understand the substandard performance of deep GCNs and hypothesize that by facilitating healthy gradient flow, we can significantly improve their trainability, as well as achieve state-of-the-art (SOTA) level performance from vanilla-GCNs. Next, we argue that blindly adopting the Glorot initialization for GCNs is not optimal, and derive a topology-aware isometric initialization scheme for vanilla-GCNs based on the principles of isometry. Additionally, contrary to ad-hoc addition of skip-connections, we propose to use gradient-guided dynamic rewiring of vanilla-GCNs} with skip connections. Our dynamic rewiring method uses the gradient flow within each layer during training to introduce on-demand skip-connections adaptively. We provide extensive empirical evidence across multiple datasets that our methods improve gradient flow in deep vanilla-GCNs and significantly boost their performance to comfortably compete and outperform many fancy state-of-the-art methods. Codes are available at: https://github.com/VITA-Group/GradientGCN.