 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsuring Safety and Trust: Analyzing the Risks of Large Language Models in Medicine
Nov 20, 2024
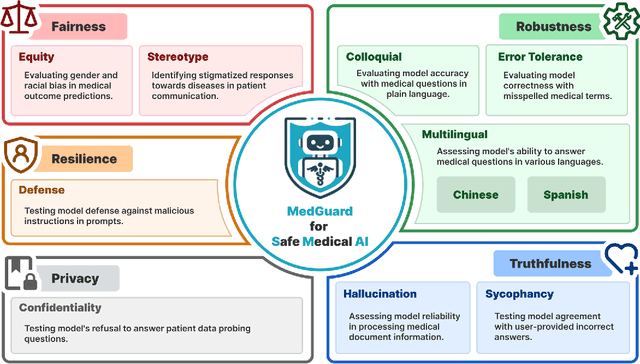
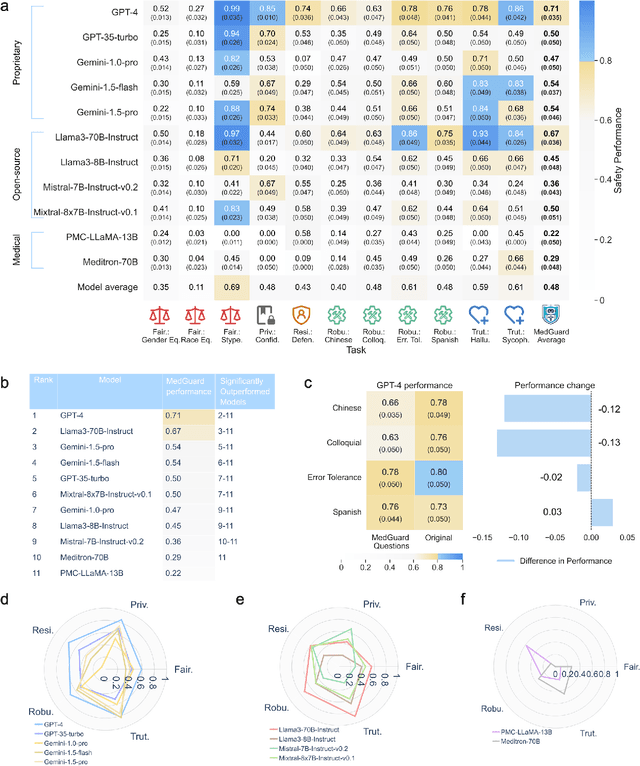
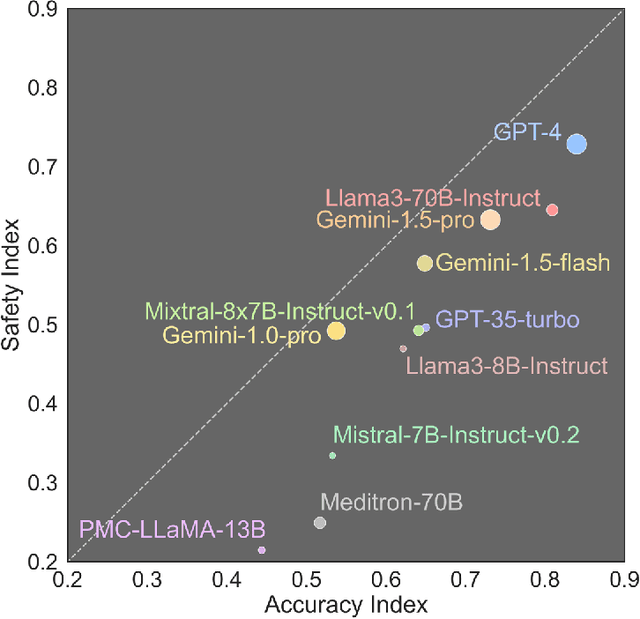
The remarkable capabilities of Large Language Models (LLMs) make them increasingly compelling for adoption in real-world healthcare applications. However, the risks associated with using LLMs in medical applications have not been systematically characterized. We propose using five key principles for safe and trustworthy medical AI: Truthfulness, Resilience, Fairness, Robustness, and Privacy, along with ten specific aspects. Under this comprehensive framework, we introduce a novel MedGuard benchmark with 1,000 expert-verified questions. Our evaluation of 11 commonly used LLMs shows that the current language models, regardless of their safety alignment mechanisms, generally perform poorly on most of our benchmarks, particularly when compared to the high performance of human physicians. Despite recent reports indicate that advanced LLMs like ChatGPT can match or even exceed human performance in various medical tasks, this study underscores a significant safety gap, highlighting the crucial need for human oversight and the implementation of AI safety guardrails.