 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Biases and Prejudice of Facial Synthesis via Semantic Latent Space
Paper and Code
Aug 23, 2021
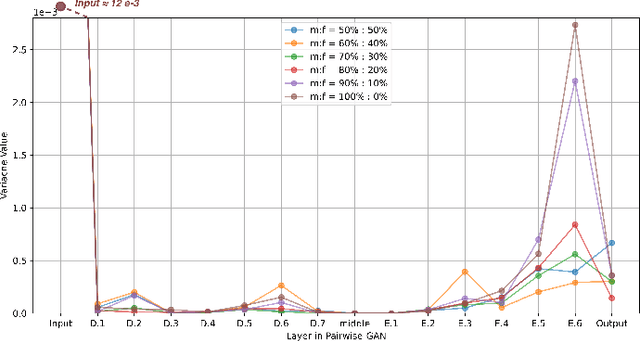
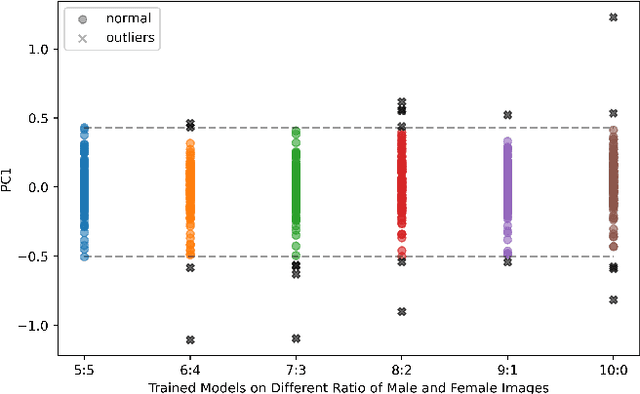
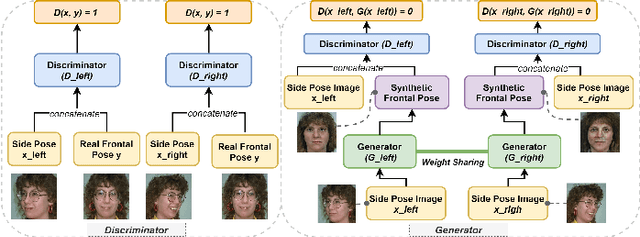
Deep learning (DL) models are widely used to provide a more convenient and smarter life. However, biased algorithms will negatively influence us. For instance, groups targeted by biased algorithms will feel unfairly treated and even fearful of negative consequences of these biases. This work targets biased generative models' behaviors, identifying the cause of the biases and eliminating them. We can (as expected) conclude that biased data causes biased predictions of face frontalization models. Varying the proportions of male and female faces in the training data can have a substantial effect on behavior on the test data: we found that the seemingly obvious choice of 50:50 proportions was not the best for this dataset to reduce biased behavior on female faces, which was 71% unbiased as compared to our top unbiased rate of 84%. Failure in generation and generating incorrect gender faces are two behaviors of these models. In addition, only some layers in face frontalization models are vulnerable to biased datasets. Optimizing the skip-connections of the generator in face frontalization models can make models less biased. We conclude that it is likely to be impossible to eliminate all training bias without an unlimited size dataset, and our experiments show that the bias can be reduced and quantified. We believe the next best to a perfect unbiased predictor is one that has minimized the remaining known bias.