 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePTQ1.61: Push the Real Limit of Extremely Low-Bit Post-Training Quantization Methods for Large Language Models
Paper and Code

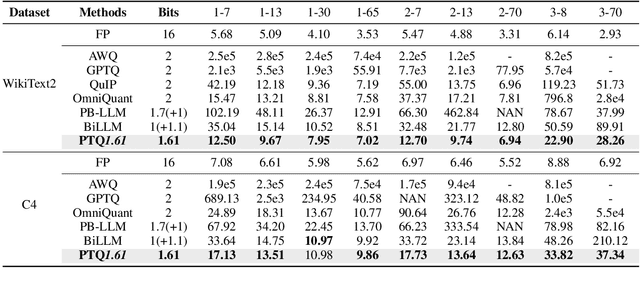
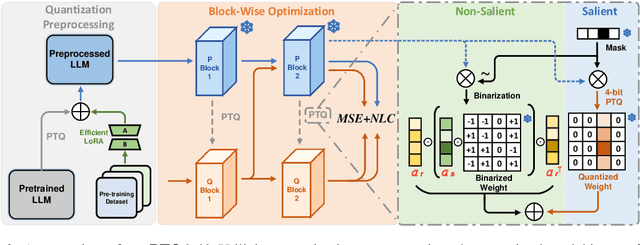
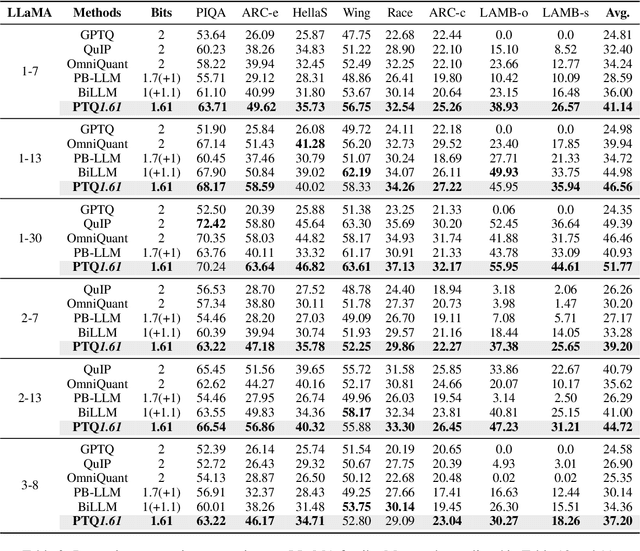
Large Language Models (LLMs) suffer severe performance degradation when facing extremely low-bit (sub 2-bit) quantization. Several existing sub 2-bit post-training quantization (PTQ) methods utilize a mix-precision scheme by leveraging an unstructured fine-grained mask to explicitly distinguish salient weights, while which introduces an extra 1-bit or more per weight. To explore the real limit of PTQ, we propose an extremely low-bit PTQ method called PTQ1.61, which enables weight quantization to 1.61-bit for the first time. Specifically, we first introduce a one-dimensional structured mask with negligibly additional 0.0002-bit per weight based on input activations from the perspective of reducing the upper bound of quantization error to allocate corresponding salient weight channels to 4-bit. For non-salient channels binarization, an efficient block-wise scaling factors optimization framework is then presented to take implicit row-wise correlations and angular biases into account. Different from prior works that concentrate on adjusting quantization methodologies, we further propose a novel paradigm called quantization preprocessing, where we argue that transforming the weight distribution of the pretrained model before quantization can alleviate the difficulty in per-channel extremely low-bit PTQ. Extensive experiments indicate our PTQ1.61 achieves state-of-the-art performance in extremely low-bit quantization. Codes are available at https://github.com/zjq0455/PTQ1.61.