 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Generate Cross-Task Unexploitable Examples
Dec 15, 2025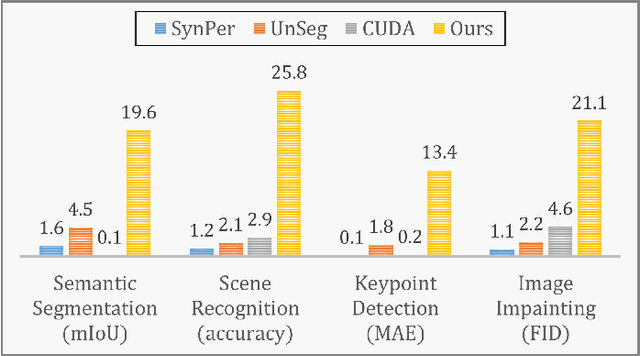
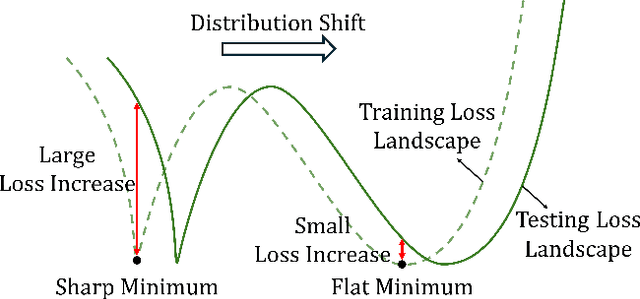

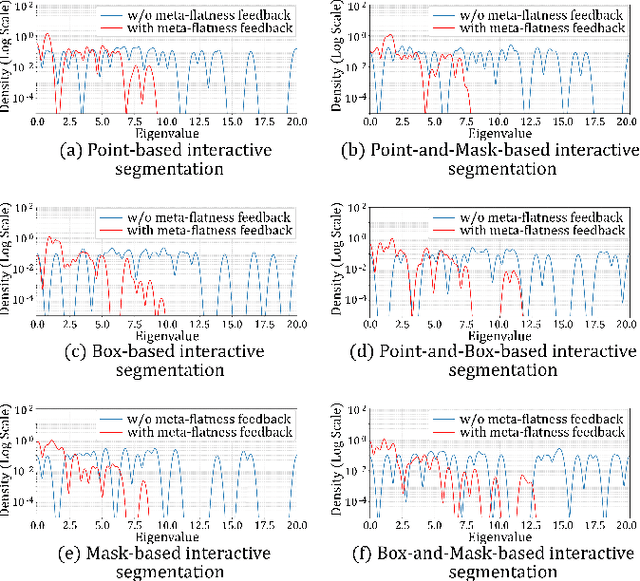
Unexploitable example generation aims to transform personal images into their unexploitable (unlearnable) versions before they are uploaded online, thereby preventing unauthorized exploitation of online personal images. Recently, this task has garnered significant research attention due to its critical relevance to personal data privacy. Yet, despite recent progress, existing methods for this task can still suffer from limited practical applicability, as they can fail to generate examples that are broadly unexploitable across different real-world computer vision tasks. To deal with this problem, in this work, we propose a novel Meta Cross-Task Unexploitable Example Generation (MCT-UEG) framework. At the core of our framework, to optimize the unexploitable example generator for effectively producing broadly unexploitable examples, we design a flat-minima-oriented meta training and testing scheme. Extensive experiments show the efficacy of our framework.
EHNet: An Efficient Hybrid Network for Crowd Counting and Localization
Mar 15, 2025In recent years, crowd counting and localization have become crucial techniques in computer vision, with applications spanning various domains. The presence of multi-scale crowd distributions within a single image remains a fundamental challenge in crowd counting tasks. To address these challenges, we introduce the Efficient Hybrid Network (EHNet), a novel framework for efficient crowd counting and localization. By reformulating crowd counting into a point regression framework, EHNet leverages the Spatial-Position Attention Module (SPAM) to capture comprehensive spatial contexts and long-range dependencies. Additionally, we develop an Adaptive Feature Aggregation Module (AFAM) to effectively fuse and harmonize multi-scale feature representations. Building upon these, we introduce the Multi-Scale Attentive Decoder (MSAD). Experimental results on four benchmark datasets demonstrate that EHNet achieves competitive performance with reduced computational overhead, outperforming existing methods on ShanghaiTech Part \_A, ShanghaiTech Part \_B, UCF-CC-50, and UCF-QNRF. Our code is in https://anonymous.4open.science/r/EHNet.
DLA-Count: Dynamic Label Assignment Network for Dense Cell Distribution Counting
Mar 15, 2025



Cell counting remains a fundamental yet challenging task in medical and biological research due to the diverse morphology of cells, their dense distribution, and variations in image quality. We present DLA-Count, a breakthrough approach to cell counting that introduces three key innovations: (1) K-adjacent Hungarian Matching (KHM), which dramatically improves cell matching in dense regions, (2) Multi-scale Deformable Gaussian Convolution (MDGC), which adapts to varying cell morphologies, and (3) Gaussian-enhanced Feature Decoder (GFD) for efficient multi-scale feature fusion. Our extensive experiments on four challenging cell counting datasets (ADI, MBM, VGG, and DCC) demonstrate that our method outperforms previous methods across diverse datasets, with improvements in Mean Absolute Error of up to 46.7\% on ADI and 42.5\% on MBM datasets. Our code is available at https://anonymous.4open.science/r/DLA-Count.
Incremental Few-Shot Semantic Segmentation via Embedding Adaptive-Update and Hyper-class Representation
Jul 26, 2022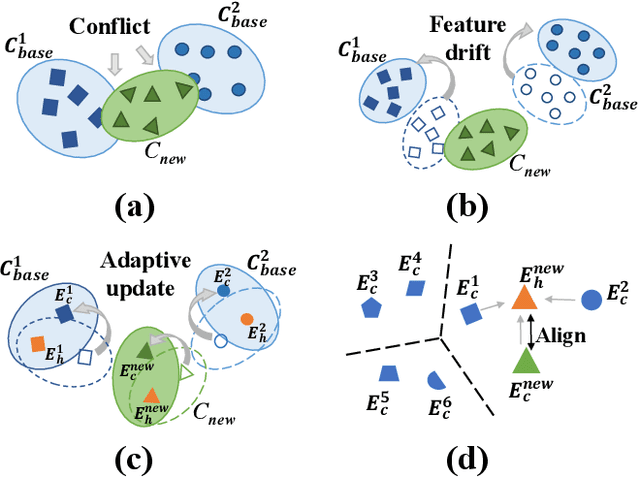

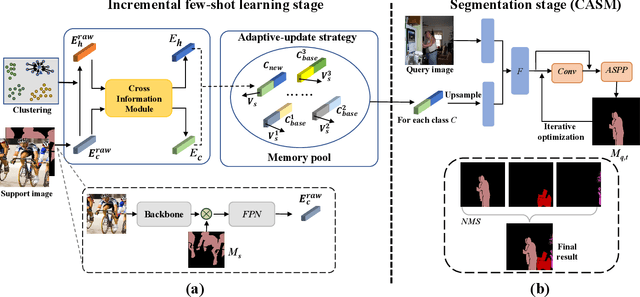

Incremental few-shot semantic segmentation (IFSS) targets at incrementally expanding model's capacity to segment new class of images supervised by only a few samples. However, features learned on old classes could significantly drift, causing catastrophic forgetting. Moreover, few samples for pixel-level segmentation on new classes lead to notorious overfitting issues in each learning session. In this paper, we explicitly represent class-based knowledge for semantic segmentation as a category embedding and a hyper-class embedding, where the former describes exclusive semantical properties, and the latter expresses hyper-class knowledge as class-shared semantic properties. Aiming to solve IFSS problems, we present EHNet, i.e., Embedding adaptive-update and Hyper-class representation Network from two aspects. First, we propose an embedding adaptive-update strategy to avoid feature drift, which maintains old knowledge by hyper-class representation, and adaptively update category embeddings with a class-attention scheme to involve new classes learned in individual sessions. Second, to resist overfitting issues caused by few training samples, a hyper-class embedding is learned by clustering all category embeddings for initialization and aligned with category embedding of the new class for enhancement, where learned knowledge assists to learn new knowledge, thus alleviating performance dependence on training data scale. Significantly, these two designs provide representation capability for classes with sufficient semantics and limited biases, enabling to perform segmentation tasks requiring high semantic dependence. Experiments on PASCAL-5i and COCO datasets show that EHNet achieves new state-of-the-art performance with remarkable advantages.
Multi-Glimpse LSTM with Color-Depth Feature Fusion for Human Detection
Nov 03, 2017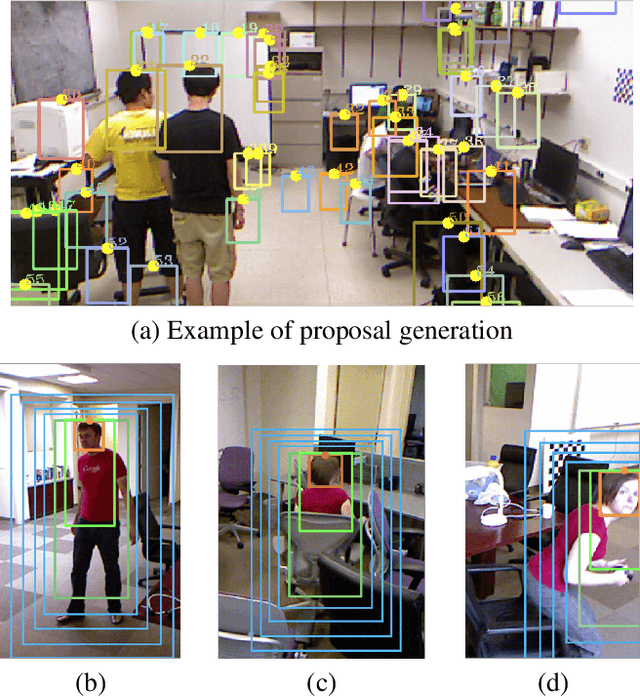
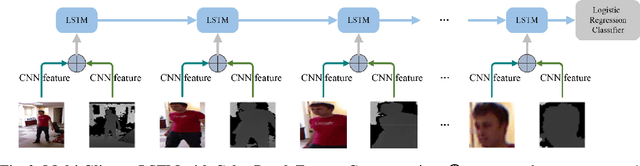
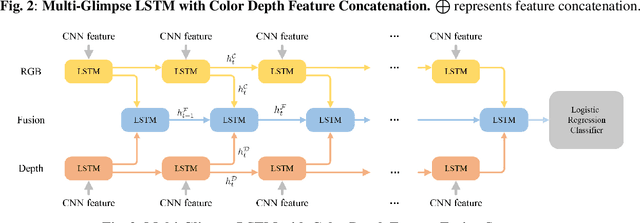
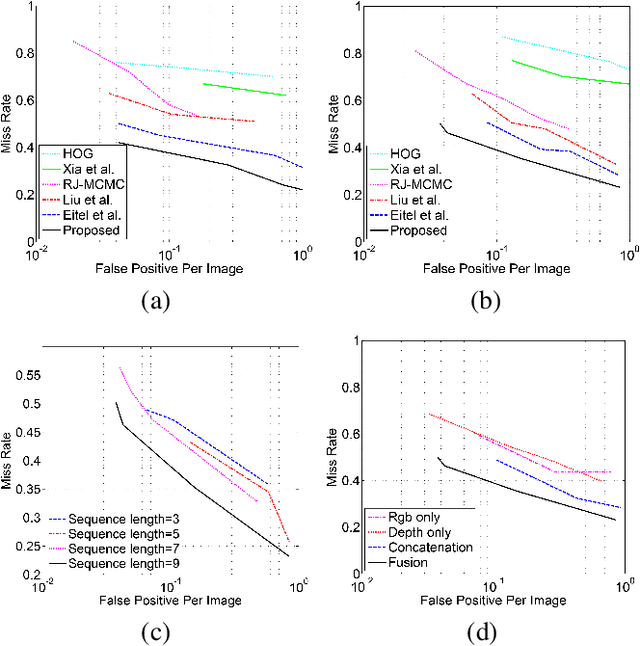
With the development of depth cameras such as Kinect and Intel Realsense, RGB-D based human detection receives continuous research attention due to its usage in a variety of applications. In this paper, we propose a new Multi-Glimpse LSTM (MG-LSTM) network, in which multi-scale contextual information is sequentially integrated to promote the human detection performance. Furthermore, we propose a feature fusion strategy based on our MG-LSTM network to better incorporate the RGB and depth information. To the best of our knowledge, this is the first attempt to utilize LSTM structure for RGB-D based human detection. Our method achieves superior performance on two publicly available datasets.