 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEHNet: An Efficient Hybrid Network for Crowd Counting and Localization
Mar 15, 2025In recent years, crowd counting and localization have become crucial techniques in computer vision, with applications spanning various domains. The presence of multi-scale crowd distributions within a single image remains a fundamental challenge in crowd counting tasks. To address these challenges, we introduce the Efficient Hybrid Network (EHNet), a novel framework for efficient crowd counting and localization. By reformulating crowd counting into a point regression framework, EHNet leverages the Spatial-Position Attention Module (SPAM) to capture comprehensive spatial contexts and long-range dependencies. Additionally, we develop an Adaptive Feature Aggregation Module (AFAM) to effectively fuse and harmonize multi-scale feature representations. Building upon these, we introduce the Multi-Scale Attentive Decoder (MSAD). Experimental results on four benchmark datasets demonstrate that EHNet achieves competitive performance with reduced computational overhead, outperforming existing methods on ShanghaiTech Part \_A, ShanghaiTech Part \_B, UCF-CC-50, and UCF-QNRF. Our code is in https://anonymous.4open.science/r/EHNet.
DLA-Count: Dynamic Label Assignment Network for Dense Cell Distribution Counting
Mar 15, 2025



Cell counting remains a fundamental yet challenging task in medical and biological research due to the diverse morphology of cells, their dense distribution, and variations in image quality. We present DLA-Count, a breakthrough approach to cell counting that introduces three key innovations: (1) K-adjacent Hungarian Matching (KHM), which dramatically improves cell matching in dense regions, (2) Multi-scale Deformable Gaussian Convolution (MDGC), which adapts to varying cell morphologies, and (3) Gaussian-enhanced Feature Decoder (GFD) for efficient multi-scale feature fusion. Our extensive experiments on four challenging cell counting datasets (ADI, MBM, VGG, and DCC) demonstrate that our method outperforms previous methods across diverse datasets, with improvements in Mean Absolute Error of up to 46.7\% on ADI and 42.5\% on MBM datasets. Our code is available at https://anonymous.4open.science/r/DLA-Count.
RGBT Tracking via Multi-Adapter Network with Hierarchical Divergence Loss
Nov 14, 2020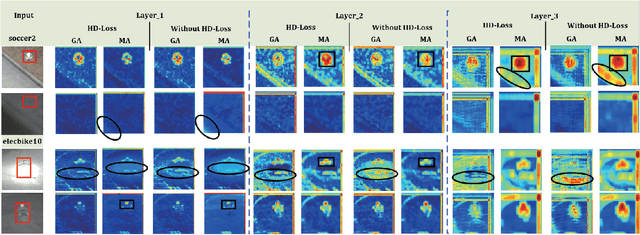
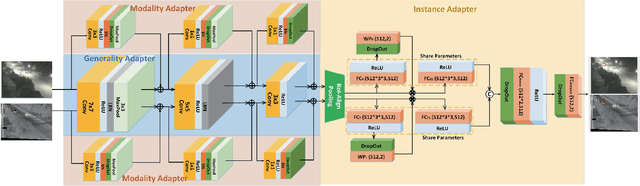

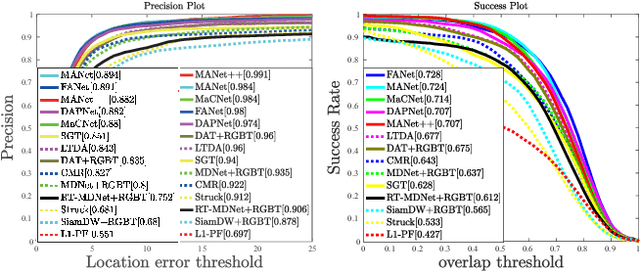
RGBT tracking has attracted increasing attention since RGB and thermal infrared data have strong complementary advantages, which could make trackers all-day and all-weather work. However, how to effectively represent RGBT data for visual tracking remains unstudied well. Existing works usually focus on extracting modality-shared or modality-specific information, but the potentials of these two cues are not well explored and exploited in RGBT tracking. In this paper, we propose a novel multi-adapter network to jointly perform modality-shared, modality-specific and instance-aware target representation learning for RGBT tracking. To this end, we design three kinds of adapters within an end-to-end deep learning framework. In specific, we use the modified VGG-M as the generality adapter to extract the modality-shared target representations.To extract the modality-specific features while reducing the computational complexity, we design a modality adapter, which adds a small block to the generality adapter in each layer and each modality in a parallel manner. Such a design could learn multilevel modality-specific representations with a modest number of parameters as the vast majority of parameters are shared with the generality adapter. We also design instance adapter to capture the appearance properties and temporal variations of a certain target. Moreover, to enhance the shared and specific features, we employ the loss of multiple kernel maximum mean discrepancy to measure the distribution divergence of different modal features and integrate it into each layer for more robust representation learning. Extensive experiments on two RGBT tracking benchmark datasets demonstrate the outstanding performance of the proposed tracker against the state-of-the-art methods.