 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Tissue Segmentation via Deep Constrained Gaussian Network
Aug 04, 2022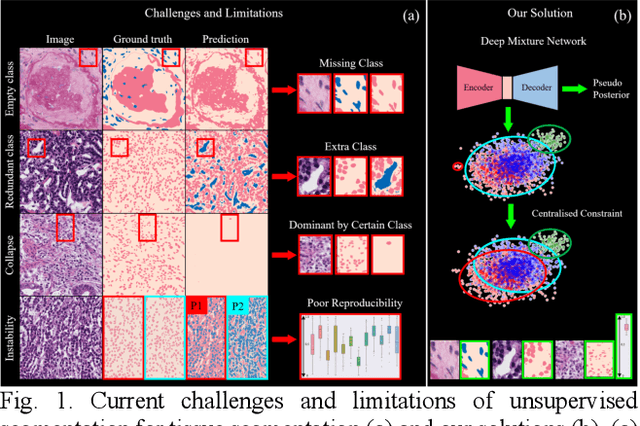
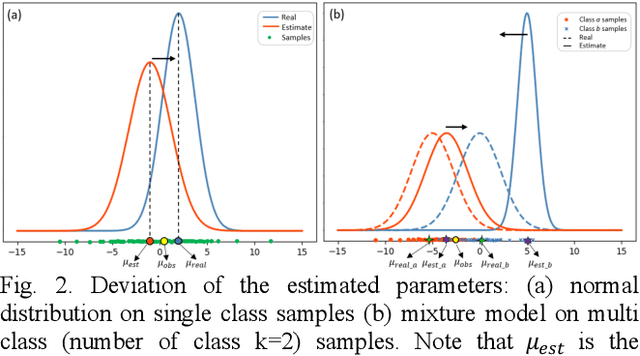
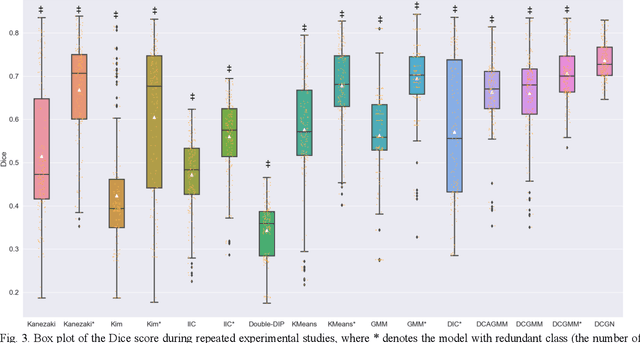
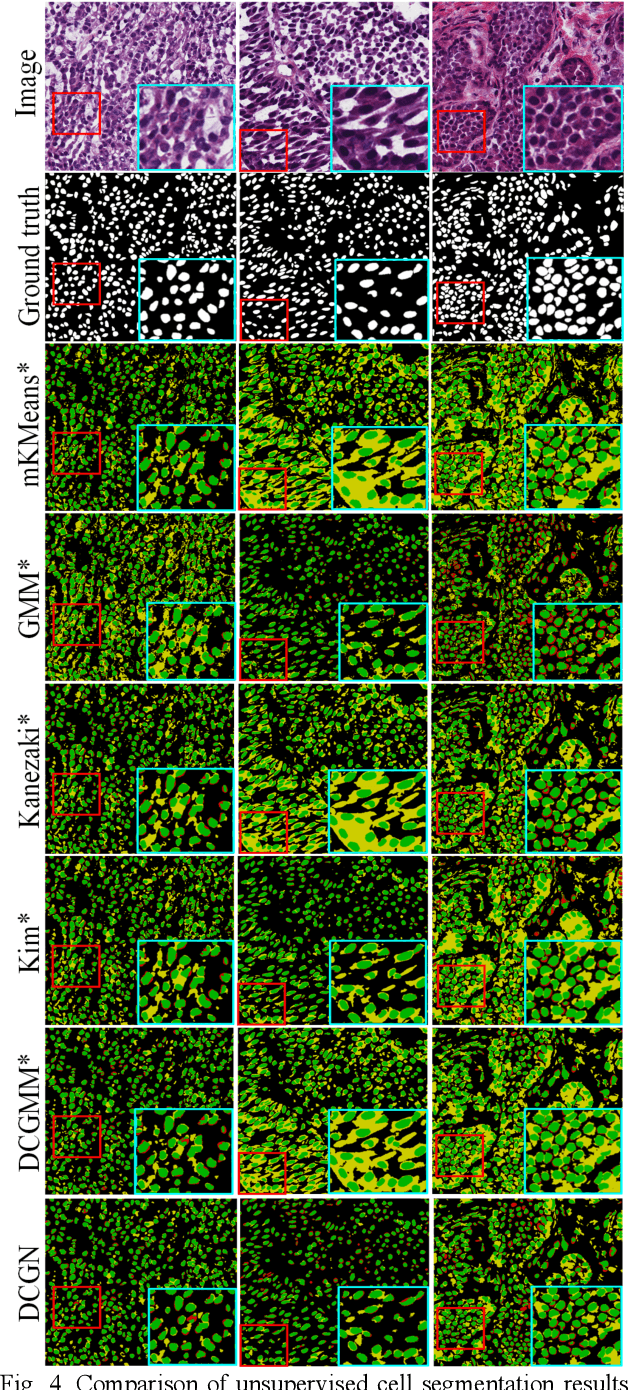
Tissue segmentation is the mainstay of pathological examination, whereas the manual delineation is unduly burdensome. To assist this time-consuming and subjective manual step, researchers have devised methods to automatically segment structures in pathological images. Recently, automated machine and deep learning based methods dominate tissue segmentation research studies. However, most machine and deep learning based approaches are supervised and developed using a large number of training samples, in which the pixelwise annotations are expensive and sometimes can be impossible to obtain. This paper introduces a novel unsupervised learning paradigm by integrating an end-to-end deep mixture model with a constrained indicator to acquire accurate semantic tissue segmentation. This constraint aims to centralise the components of deep mixture models during the calculation of the optimisation function. In so doing, the redundant or empty class issues, which are common in current unsupervised learning methods, can be greatly reduced. By validation on both public and in-house datasets, the proposed deep constrained Gaussian network achieves significantly (Wilcoxon signed-rank test) better performance (with the average Dice scores of 0.737 and 0.735, respectively) on tissue segmentation with improved stability and robustness, compared to other existing unsupervised segmentation approaches. Furthermore, the proposed method presents a similar performance (p-value > 0.05) compared to the fully supervised U-Net.
Automatic Fine-grained Glomerular Lesion Recognition in Kidney Pathology
Mar 11, 2022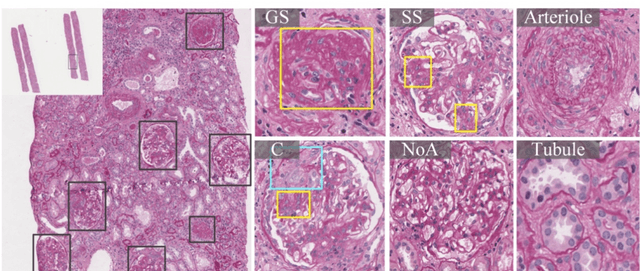
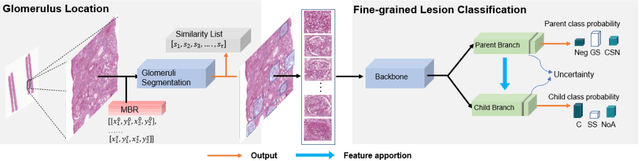
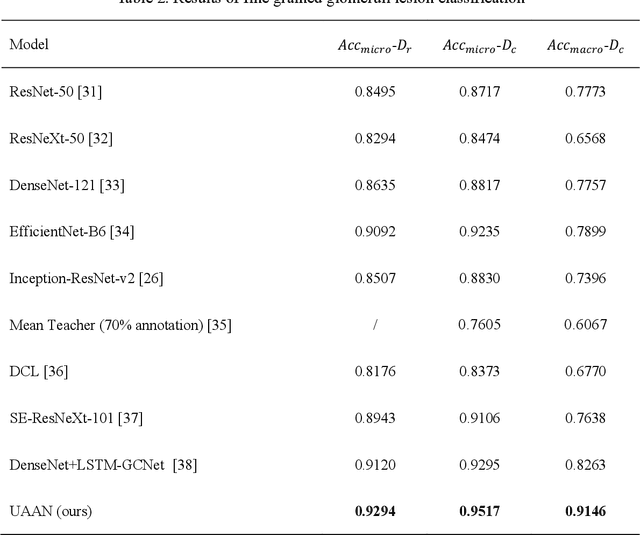
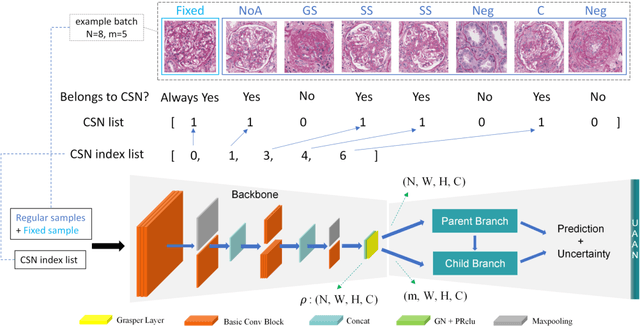
Recognition of glomeruli lesions is the key for diagnosis and treatment planning in kidney pathology; however, the coexisting glomerular structures such as mesangial regions exacerbate the difficulties of this task. In this paper, we introduce a scheme to recognize fine-grained glomeruli lesions from whole slide images. First, a focal instance structural similarity loss is proposed to drive the model to locate all types of glomeruli precisely. Then an Uncertainty Aided Apportionment Network is designed to carry out the fine-grained visual classification without bounding-box annotations. This double branch-shaped structure extracts common features of the child class from the parent class and produces the uncertainty factor for reconstituting the training dataset. Results of slide-wise evaluation illustrate the effectiveness of the entire scheme, with an 8-22% improvement of the mean Average Precision compared with remarkable detection methods. The comprehensive results clearly demonstrate the effectiveness of the proposed method.
Multi-Glimpse LSTM with Color-Depth Feature Fusion for Human Detection
Nov 03, 2017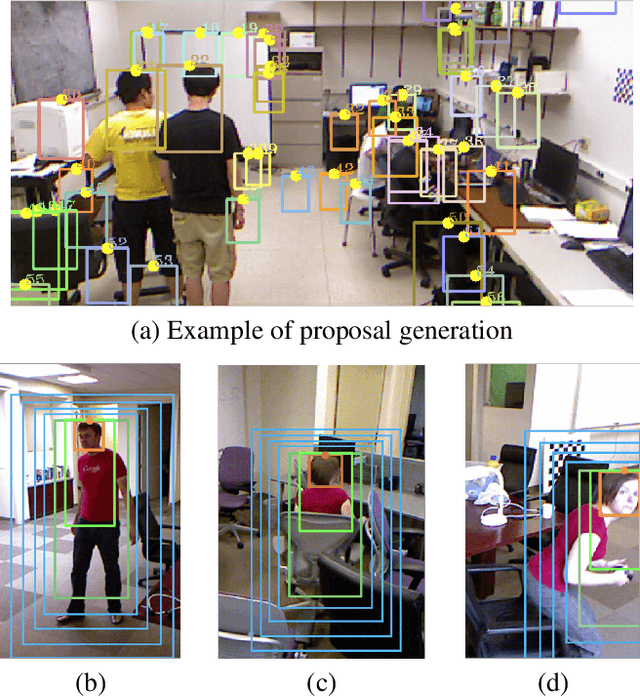
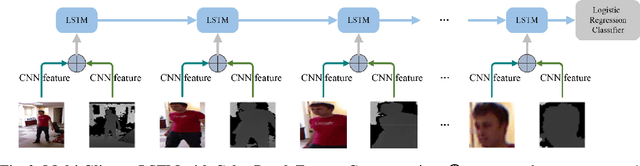
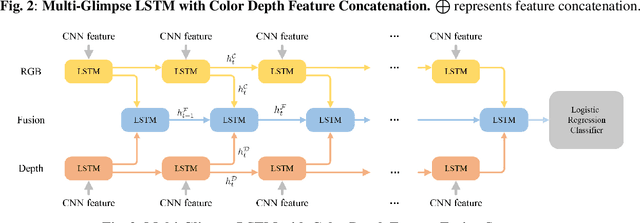
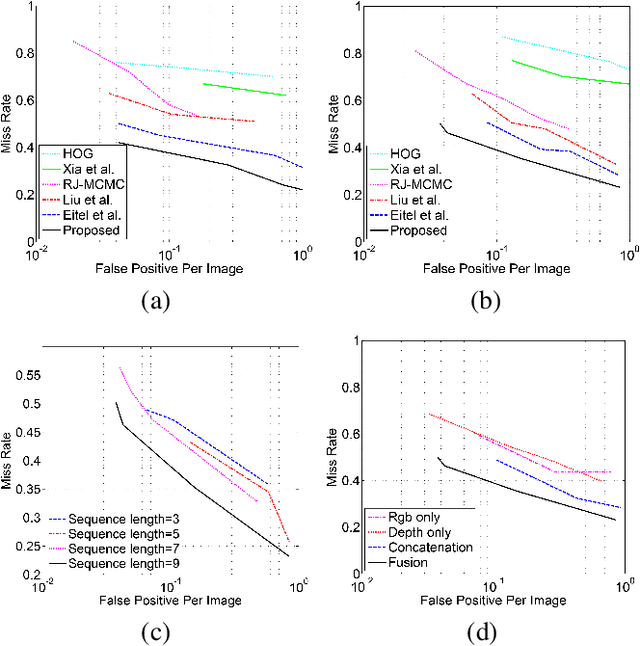
With the development of depth cameras such as Kinect and Intel Realsense, RGB-D based human detection receives continuous research attention due to its usage in a variety of applications. In this paper, we propose a new Multi-Glimpse LSTM (MG-LSTM) network, in which multi-scale contextual information is sequentially integrated to promote the human detection performance. Furthermore, we propose a feature fusion strategy based on our MG-LSTM network to better incorporate the RGB and depth information. To the best of our knowledge, this is the first attempt to utilize LSTM structure for RGB-D based human detection. Our method achieves superior performance on two publicly available datasets.
Temporal Context Network for Activity Localization in Videos
Aug 08, 2017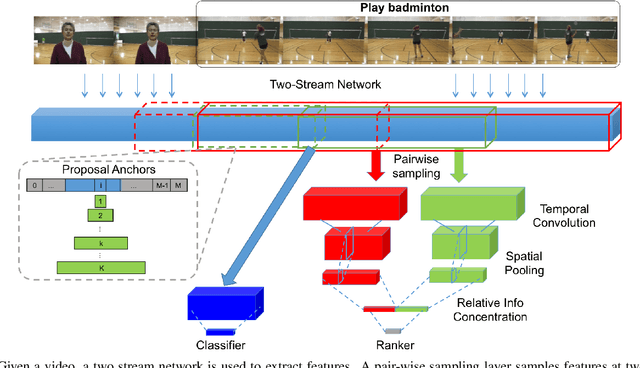

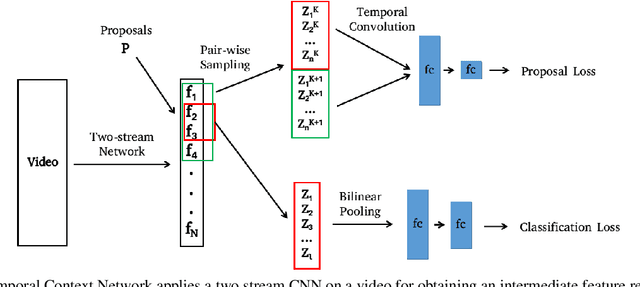
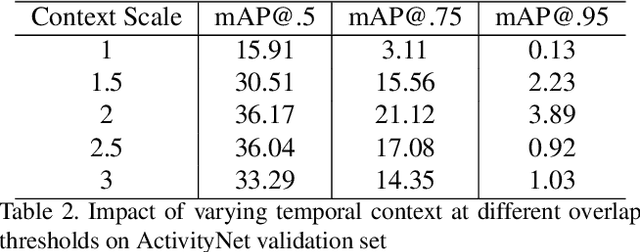
We present a Temporal Context Network (TCN) for precise temporal localization of human activities. Similar to the Faster-RCNN architecture, proposals are placed at equal intervals in a video which span multiple temporal scales. We propose a novel representation for ranking these proposals. Since pooling features only inside a segment is not sufficient to predict activity boundaries, we construct a representation which explicitly captures context around a proposal for ranking it. For each temporal segment inside a proposal, features are uniformly sampled at a pair of scales and are input to a temporal convolutional neural network for classification. After ranking proposals, non-maximum suppression is applied and classification is performed to obtain final detections. TCN outperforms state-of-the-art methods on the ActivityNet dataset and the THUMOS14 dataset.