 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Guided Prompting for Unified Remote Sensing Image Restoration
Apr 03, 2026Remote sensing image restoration (RSIR) is essential for recovering high-fidelity imagery from degraded observations, enabling accurate downstream analysis. However, most existing methods focus on single degradation types within homogeneous data, restricting their practicality in real-world scenarios where multiple degradations often across diverse spectral bands or sensor modalities, creating a significant operational bottleneck. To address this fundamental gap, we propose TGPNet, a unified framework capable of handling denoising, cloud removal, shadow removal, deblurring, and SAR despeckling within a single, unified architecture. The core of our framework is a novel Task-Guided Prompting (TGP) strategy. TGP leverages learnable, task-specific embeddings to generate degradation-aware cues, which then hierarchically modulate features throughout the decoder. This task-adaptive mechanism allows the network to precisely tailor its restoration process for distinct degradation patterns while maintaining a single set of shared weights. To validate our framework, we construct a unified RSIR benchmark covering RGB, multispectral, SAR, and thermal infrared modalities for five aforementioned restoration tasks. Experimental results demonstrate that TGPNet achieves state-of-the-art performance on both unified multi-task scenarios and unseen composite degradations, surpassing even specialized models in individual domains such as cloud removal. By successfully unifying heterogeneous degradation removal within a single adaptive framework, this work presents a significant advancement for multi-task RSIR, offering a practical and scalable solution for operational pipelines. The code and benchmark will be released at https://github.com/huangwenwenlili/TGPNet.
* 17 pages, 11 figures
Any House Any Task: Scalable Long-Horizon Planning for Abstract Human Tasks
Feb 12, 2026Open world language conditioned task planning is crucial for robots operating in large-scale household environments. While many recent works attempt to address this problem using Large Language Models (LLMs) via prompting or training, a key challenge remains scalability. Performance often degrades rapidly with increasing environment size, plan length, instruction ambiguity, and constraint complexity. In this work, we propose Any House Any Task (AHAT), a household task planner optimized for long-horizon planning in large environments given ambiguous human instructions. At its core, AHAT utilizes an LLM trained to map task instructions and textual scene graphs into grounded subgoals defined in the Planning Domain Definition Language (PDDL). These subgoals are subsequently solved to generate feasible and optimal long-horizon plans through explicit symbolic reasoning. To enhance the model's ability to decompose complex and ambiguous intentions, we introduce TGPO, a novel reinforcement learning algorithm that integrates external correction of intermediate reasoning traces into Group Relative Policy Optimization (GRPO). Experiments demonstrate that AHAT achieves significant performance gains over state-of-the-art prompting, planning, and learning methods, particularly in human-style household tasks characterized by brief instructions but requiring complex execution plans.
RealVVT: Towards Photorealistic Video Virtual Try-on via Spatio-Temporal Consistency
Jan 15, 2025Virtual try-on has emerged as a pivotal task at the intersection of computer vision and fashion, aimed at digitally simulating how clothing items fit on the human body. Despite notable progress in single-image virtual try-on (VTO), current methodologies often struggle to preserve a consistent and authentic appearance of clothing across extended video sequences. This challenge arises from the complexities of capturing dynamic human pose and maintaining target clothing characteristics. We leverage pre-existing video foundation models to introduce RealVVT, a photoRealistic Video Virtual Try-on framework tailored to bolster stability and realism within dynamic video contexts. Our methodology encompasses a Clothing & Temporal Consistency strategy, an Agnostic-guided Attention Focus Loss mechanism to ensure spatial consistency, and a Pose-guided Long Video VTO technique adept at handling extended video sequences.Extensive experiments across various datasets confirms that our approach outperforms existing state-of-the-art models in both single-image and video VTO tasks, offering a viable solution for practical applications within the realms of fashion e-commerce and virtual fitting environments.
Enhancing Decision Transformer with Diffusion-Based Trajectory Branch Generation
Nov 18, 2024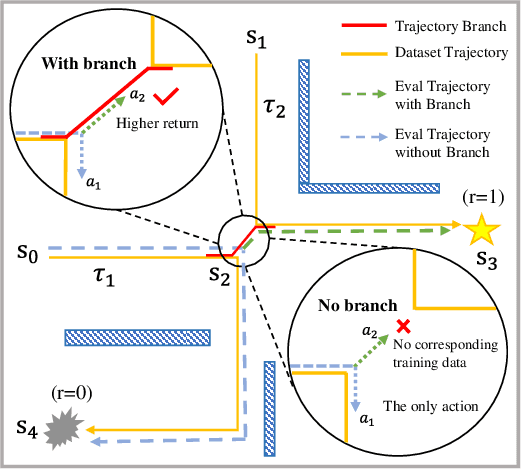
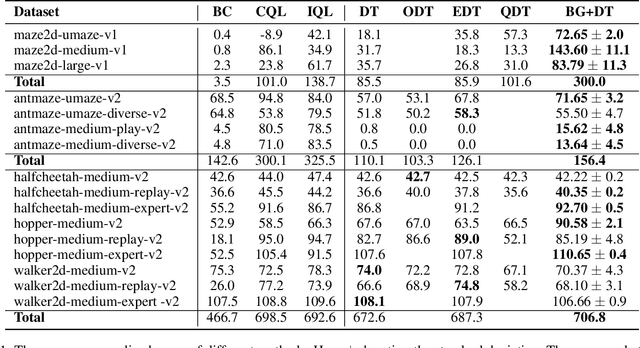
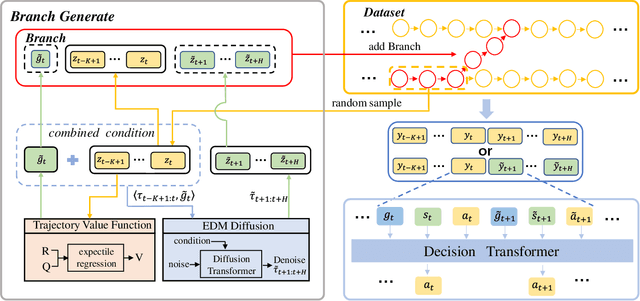
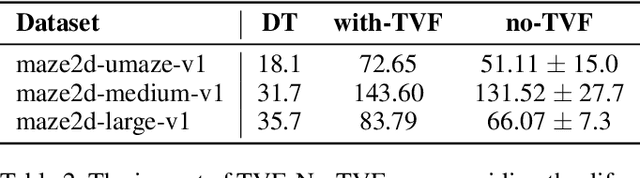
Decision Transformer (DT) can learn effective policy from offline datasets by converting the offline reinforcement learning (RL) into a supervised sequence modeling task, where the trajectory elements are generated auto-regressively conditioned on the return-to-go (RTG).However, the sequence modeling learning approach tends to learn policies that converge on the sub-optimal trajectories within the dataset, for lack of bridging data to move to better trajectories, even if the condition is set to the highest RTG.To address this issue, we introduce Diffusion-Based Trajectory Branch Generation (BG), which expands the trajectories of the dataset with branches generated by a diffusion model.The trajectory branch is generated based on the segment of the trajectory within the dataset, and leads to trajectories with higher returns.We concatenate the generated branch with the trajectory segment as an expansion of the trajectory.After expanding, DT has more opportunities to learn policies to move to better trajectories, preventing it from converging to the sub-optimal trajectories.Empirically, after processing with BG, DT outperforms state-of-the-art sequence modeling methods on D4RL benchmark, demonstrating the effectiveness of adding branches to the dataset without further modifications.
Acceleration for Deep Reinforcement Learning using Parallel and Distributed Computing: A Survey
Nov 08, 2024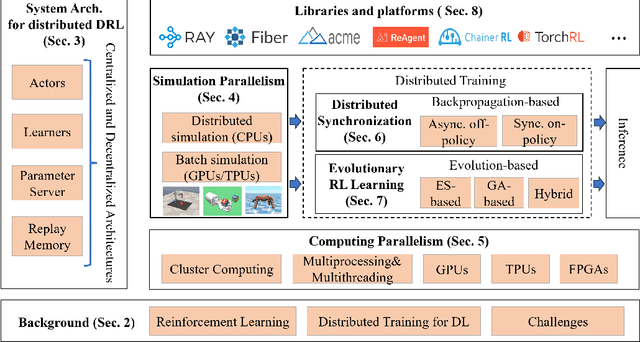

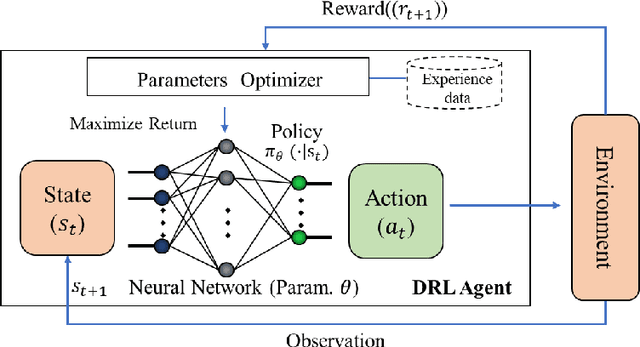

Deep reinforcement learning has led to dramatic breakthroughs in the field of artificial intelligence for the past few years. As the amount of rollout experience data and the size of neural networks for deep reinforcement learning have grown continuously, handling the training process and reducing the time consumption using parallel and distributed computing is becoming an urgent and essential desire. In this paper, we perform a broad and thorough investigation on training acceleration methodologies for deep reinforcement learning based on parallel and distributed computing, providing a comprehensive survey in this field with state-of-the-art methods and pointers to core references. In particular, a taxonomy of literature is provided, along with a discussion of emerging topics and open issues. This incorporates learning system architectures, simulation parallelism, computing parallelism, distributed synchronization mechanisms, and deep evolutionary reinforcement learning. Further, we compare 16 current open-source libraries and platforms with criteria of facilitating rapid development. Finally, we extrapolate future directions that deserve further research.
Uncertainty Quantification of Data Shapley via Statistical Inference
Jul 28, 2024As data plays an increasingly pivotal role in decision-making, the emergence of data markets underscores the growing importance of data valuation. Within the machine learning landscape, Data Shapley stands out as a widely embraced method for data valuation. However, a limitation of Data Shapley is its assumption of a fixed dataset, contrasting with the dynamic nature of real-world applications where data constantly evolves and expands. This paper establishes the relationship between Data Shapley and infinite-order U-statistics and addresses this limitation by quantifying the uncertainty of Data Shapley with changes in data distribution from the perspective of U-statistics. We make statistical inferences on data valuation to obtain confidence intervals for the estimations. We construct two different algorithms to estimate this uncertainty and provide recommendations for their applicable situations. We also conduct a series of experiments on various datasets to verify asymptotic normality and propose a practical trading scenario enabled by this method.
2D-Shapley: A Framework for Fragmented Data Valuation
Jun 18, 2023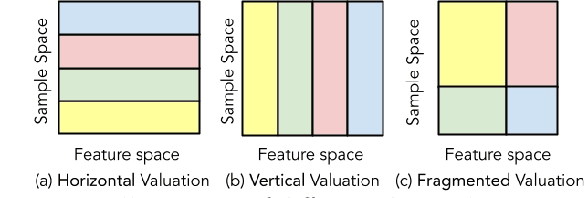

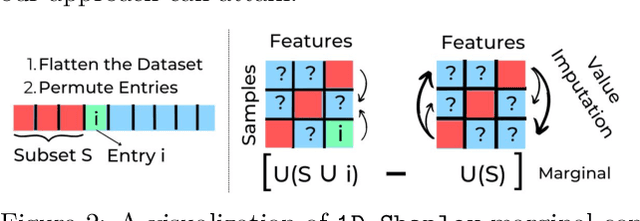
Data valuation -- quantifying the contribution of individual data sources to certain predictive behaviors of a model -- is of great importance to enhancing the transparency of machine learning and designing incentive systems for data sharing. Existing work has focused on evaluating data sources with the shared feature or sample space. How to valuate fragmented data sources of which each only contains partial features and samples remains an open question. We start by presenting a method to calculate the counterfactual of removing a fragment from the aggregated data matrix. Based on the counterfactual calculation, we further propose 2D-Shapley, a theoretical framework for fragmented data valuation that uniquely satisfies some appealing axioms in the fragmented data context. 2D-Shapley empowers a range of new use cases, such as selecting useful data fragments, providing interpretation for sample-wise data values, and fine-grained data issue diagnosis.
Unsupervised Tissue Segmentation via Deep Constrained Gaussian Network
Aug 04, 2022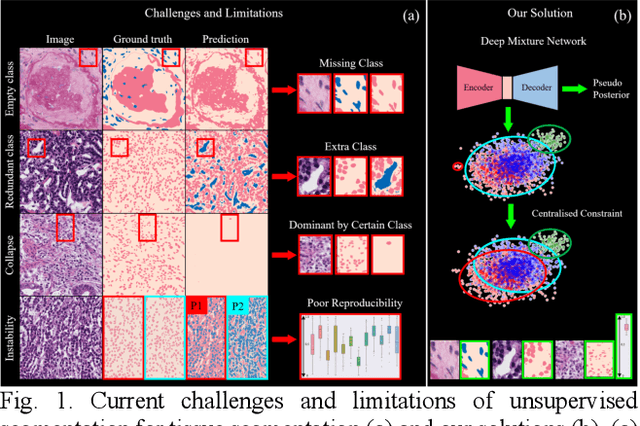
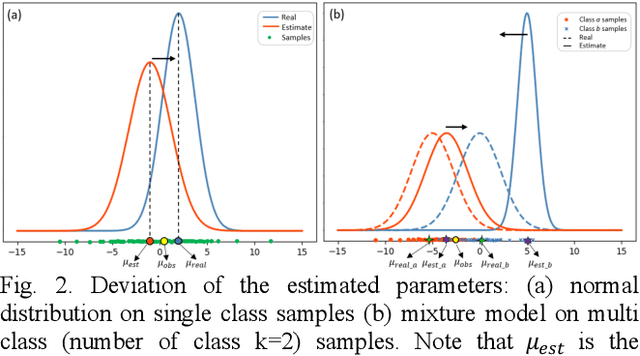
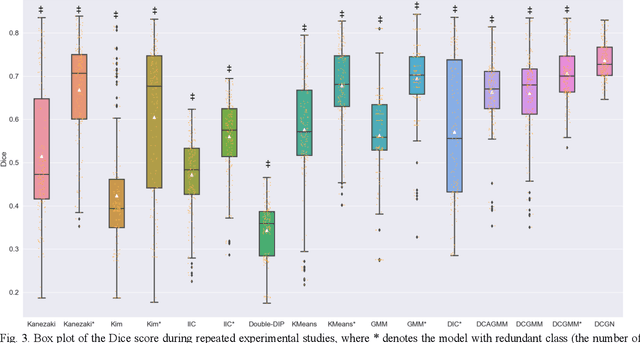
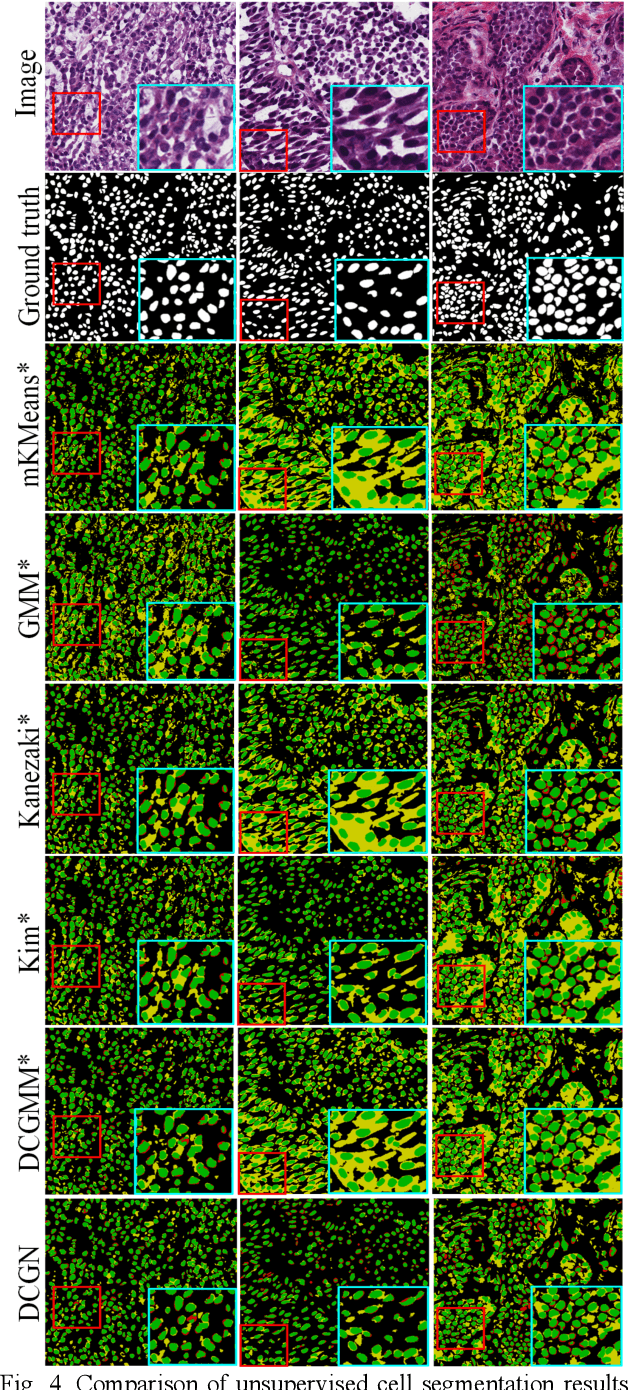
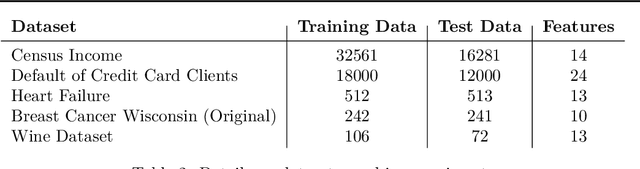
Tissue segmentation is the mainstay of pathological examination, whereas the manual delineation is unduly burdensome. To assist this time-consuming and subjective manual step, researchers have devised methods to automatically segment structures in pathological images. Recently, automated machine and deep learning based methods dominate tissue segmentation research studies. However, most machine and deep learning based approaches are supervised and developed using a large number of training samples, in which the pixelwise annotations are expensive and sometimes can be impossible to obtain. This paper introduces a novel unsupervised learning paradigm by integrating an end-to-end deep mixture model with a constrained indicator to acquire accurate semantic tissue segmentation. This constraint aims to centralise the components of deep mixture models during the calculation of the optimisation function. In so doing, the redundant or empty class issues, which are common in current unsupervised learning methods, can be greatly reduced. By validation on both public and in-house datasets, the proposed deep constrained Gaussian network achieves significantly (Wilcoxon signed-rank test) better performance (with the average Dice scores of 0.737 and 0.735, respectively) on tissue segmentation with improved stability and robustness, compared to other existing unsupervised segmentation approaches. Furthermore, the proposed method presents a similar performance (p-value > 0.05) compared to the fully supervised U-Net.
Automatic Fine-grained Glomerular Lesion Recognition in Kidney Pathology
Mar 11, 2022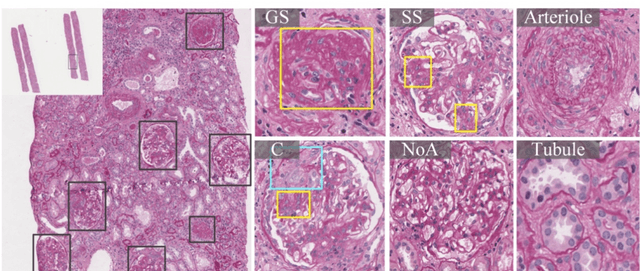
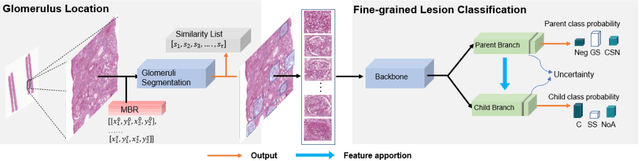
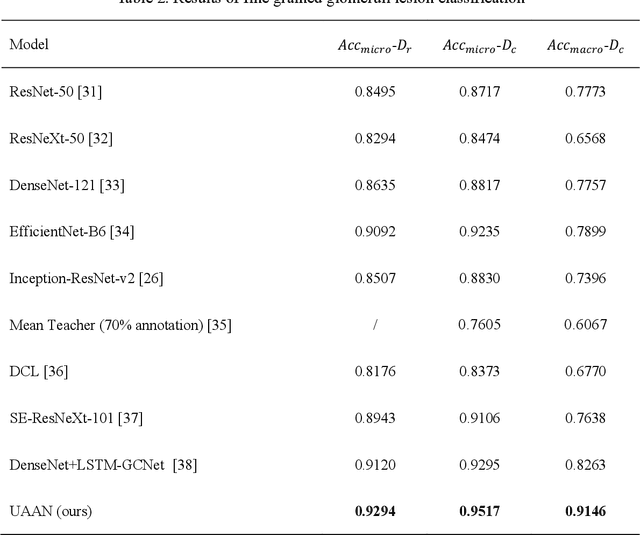
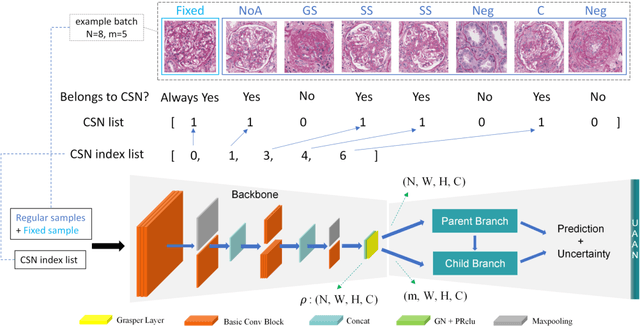
Recognition of glomeruli lesions is the key for diagnosis and treatment planning in kidney pathology; however, the coexisting glomerular structures such as mesangial regions exacerbate the difficulties of this task. In this paper, we introduce a scheme to recognize fine-grained glomeruli lesions from whole slide images. First, a focal instance structural similarity loss is proposed to drive the model to locate all types of glomeruli precisely. Then an Uncertainty Aided Apportionment Network is designed to carry out the fine-grained visual classification without bounding-box annotations. This double branch-shaped structure extracts common features of the child class from the parent class and produces the uncertainty factor for reconstituting the training dataset. Results of slide-wise evaluation illustrate the effectiveness of the entire scheme, with an 8-22% improvement of the mean Average Precision compared with remarkable detection methods. The comprehensive results clearly demonstrate the effectiveness of the proposed method.
Deep Learning Methods for Lung Cancer Segmentation in Whole-slide Histopathology Images -- the ACDC@LungHP Challenge 2019
Aug 21, 2020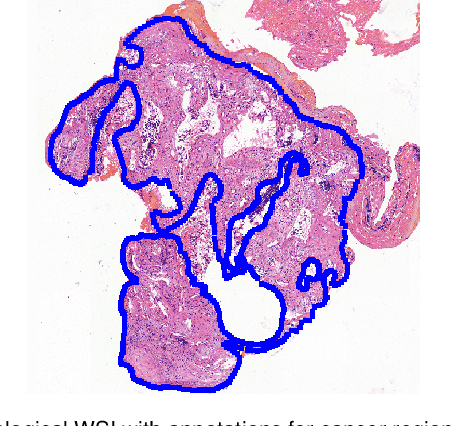
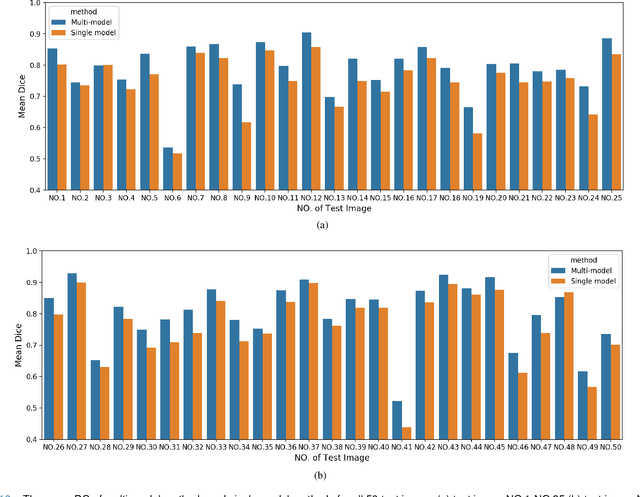
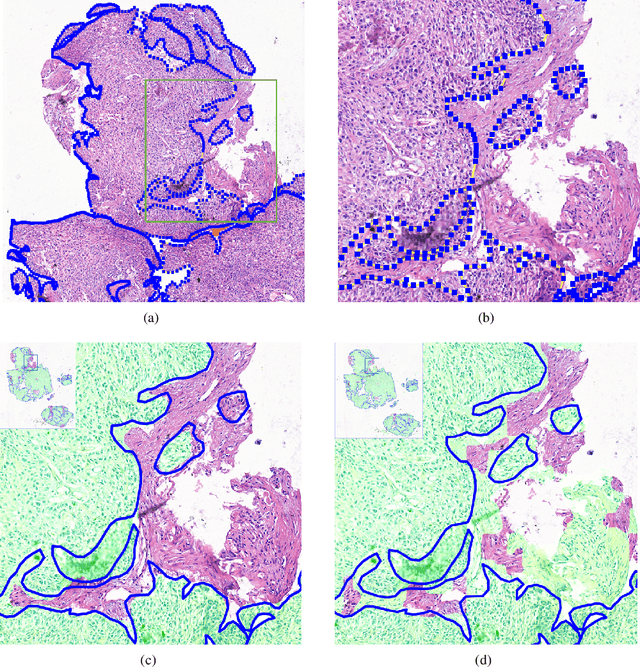

Accurate segmentation of lung cancer in pathology slides is a critical step in improving patient care. We proposed the ACDC@LungHP (Automatic Cancer Detection and Classification in Whole-slide Lung Histopathology) challenge for evaluating different computer-aided diagnosis (CADs) methods on the automatic diagnosis of lung cancer. The ACDC@LungHP 2019 focused on segmentation (pixel-wise detection) of cancer tissue in whole slide imaging (WSI), using an annotated dataset of 150 training images and 50 test images from 200 patients. This paper reviews this challenge and summarizes the top 10 submitted methods for lung cancer segmentation. All methods were evaluated using the false positive rate, false negative rate, and DICE coefficient (DC). The DC ranged from 0.7354$\pm$0.1149 to 0.8372$\pm$0.0858. The DC of the best method was close to the inter-observer agreement (0.8398$\pm$0.0890). All methods were based on deep learning and categorized into two groups: multi-model method and single model method. In general, multi-model methods were significantly better ($\textit{p}$<$0.01$) than single model methods, with mean DC of 0.7966 and 0.7544, respectively. Deep learning based methods could potentially help pathologists find suspicious regions for further analysis of lung cancer in WSI.