 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcceleration for Deep Reinforcement Learning using Parallel and Distributed Computing: A Survey
Paper and Code
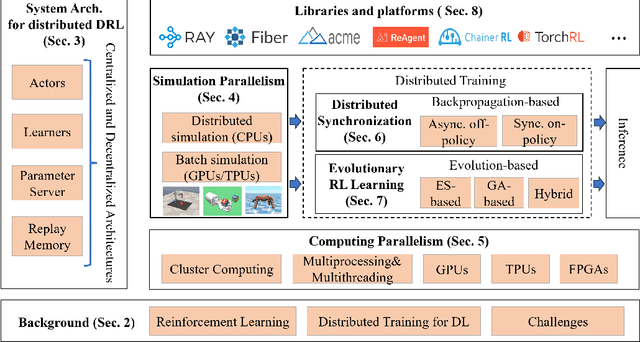

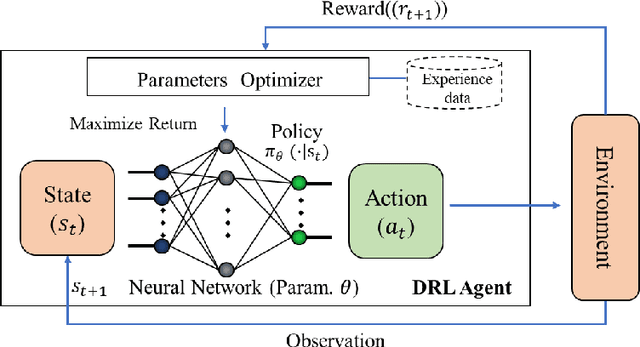

Deep reinforcement learning has led to dramatic breakthroughs in the field of artificial intelligence for the past few years. As the amount of rollout experience data and the size of neural networks for deep reinforcement learning have grown continuously, handling the training process and reducing the time consumption using parallel and distributed computing is becoming an urgent and essential desire. In this paper, we perform a broad and thorough investigation on training acceleration methodologies for deep reinforcement learning based on parallel and distributed computing, providing a comprehensive survey in this field with state-of-the-art methods and pointers to core references. In particular, a taxonomy of literature is provided, along with a discussion of emerging topics and open issues. This incorporates learning system architectures, simulation parallelism, computing parallelism, distributed synchronization mechanisms, and deep evolutionary reinforcement learning. Further, we compare 16 current open-source libraries and platforms with criteria of facilitating rapid development. Finally, we extrapolate future directions that deserve further research.