 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty Quantification of Data Shapley via Statistical Inference
Jul 28, 2024As data plays an increasingly pivotal role in decision-making, the emergence of data markets underscores the growing importance of data valuation. Within the machine learning landscape, Data Shapley stands out as a widely embraced method for data valuation. However, a limitation of Data Shapley is its assumption of a fixed dataset, contrasting with the dynamic nature of real-world applications where data constantly evolves and expands. This paper establishes the relationship between Data Shapley and infinite-order U-statistics and addresses this limitation by quantifying the uncertainty of Data Shapley with changes in data distribution from the perspective of U-statistics. We make statistical inferences on data valuation to obtain confidence intervals for the estimations. We construct two different algorithms to estimate this uncertainty and provide recommendations for their applicable situations. We also conduct a series of experiments on various datasets to verify asymptotic normality and propose a practical trading scenario enabled by this method.
Robust Data Valuation via Variance Reduced Data Shapley
Nov 10, 2022



Data valuation, especially quantifying data value in algorithmic prediction and decision-making, is a fundamental problem in data trading scenarios. The most widely used method is to define the data Shapley and approximate it by means of the permutation sampling algorithm. To make up for the large estimation variance of the permutation sampling that hinders the development of the data marketplace, we propose a more robust data valuation method using stratified sampling, named variance reduced data Shapley (VRDS for short). We theoretically show how to stratify, how many samples are taken at each stratum, and the sample complexity analysis of VRDS. Finally, the effectiveness of VRDS is illustrated in different types of datasets and data removal applications.
Multi-Interest Network with Dynamic Routing for Recommendation at Tmall
Apr 17, 2019

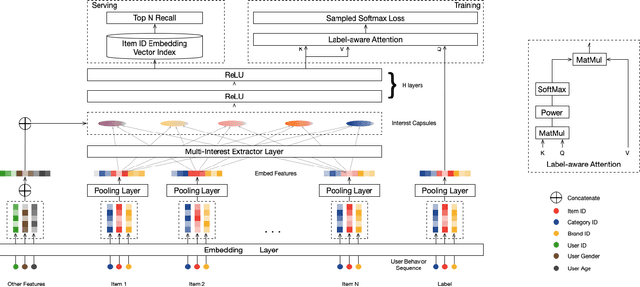

Industrial recommender systems usually consist of the matching stage and the ranking stage, in order to handle the billion-scale of users and items. The matching stage retrieves candidate items relevant to user interests, while the ranking stage sorts candidate items by user interests. Thus, the most critical ability is to model and represent user interests for either stage. Most of the existing deep learning-based models represent one user as a single vector which is insufficient to capture the varying nature of user's interests. In this paper, we approach this problem from a different view, to represent one user with multiple vectors encoding the different aspects of the user's interests. We propose the Multi-Interest Network with Dynamic routing (MIND) for dealing with user's diverse interests in the matching stage. Specifically, we design a multi-interest extractor layer based on capsule routing mechanism, which is applicable for clustering historical behaviors and extracting diverse interests. Furthermore, we develop a technique named label-aware attention to help learn a user representation with multiple vectors. Through extensive experiments on several public benchmarks and one large-scale industrial dataset from Tmall, we demonstrate that MIND can achieve superior performance than state-of-the-art methods for recommendation. Currently, MIND has been deployed for handling major online traffic at the homepage on Mobile Tmall App.