 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Vision-Language-Action Models across XPUs: Constraints and Acceleration for On-Robot Deployment
Apr 27, 2026Vision-Language-Action (VLA) models are promising for generalist robot control, but on-robot deployment is bottlenecked by real-time inference under tight cost and energy budgets. Most prior evaluations rely on desktop-grade GPUs, obscuring the trade-offs and opportunities offered by heterogeneous edge accelerators (GPUs/XPUs/NPUs). We present a systematic analysis for low-cost VLA deployment via model-hardware co-characterization. First, we build a cross-accelerator leaderboard and evaluate model-hardware pairs under CET (Cost, Energy, Time), showing that right-sized edge devices can be more cost-/energy-efficient than flagship GPUs while meeting control-rate constraints. Second, using in-depth profiling, we uncover a consistent two-phase inference pattern: a compute-bound VLM backbone followed by a memory-bound Action Expert, which induces phase-dependent underutilization and hardware inefficiency. Finally, guided by these insights, we propose DP-Cache and V-AEFusion to reduce diffusion redundancy and enable asynchronous pipeline parallelism, achieving up to 2.9x speedup on GPUs and 6x on edge NPUs with only marginal success degradation. The example leaderboard website is available at: https://vla-leaderboard-01.vercel.app/.
MixFormer: Co-Scaling Up Dense and Sequence in Industrial Recommenders
Feb 15, 2026As industrial recommender systems enter a scaling-driven regime, Transformer architectures have become increasingly attractive for scaling models towards larger capacity and longer sequence. However, existing Transformer-based recommendation models remain structurally fragmented, where sequence modeling and feature interaction are implemented as separate modules with independent parameterization. Such designs introduce a fundamental co-scaling challenge, as model capacity must be suboptimally allocated between dense feature interaction and sequence modeling under a limited computational budget. In this work, we propose MixFormer, a unified Transformer-style architecture tailored for recommender systems, which jointly models sequential behaviors and feature interactions within a single backbone. Through a unified parameterization, MixFormer enables effective co-scaling across both dense capacity and sequence length, mitigating the trade-off observed in decoupled designs. Moreover, the integrated architecture facilitates deep interaction between sequential and non-sequential representations, allowing high-order feature semantics to directly inform sequence aggregation and enhancing overall expressiveness. To ensure industrial practicality, we further introduce a user-item decoupling strategy for efficiency optimizations that significantly reduce redundant computation and inference latency. Extensive experiments on large-scale industrial datasets demonstrate that MixFormer consistently exhibits superior accuracy and efficiency. Furthermore, large-scale online A/B tests on two production recommender systems, Douyin and Douyin Lite, show consistent improvements in user engagement metrics, including active days and in-app usage duration.
Compute Only Once: UG-Separation for Efficient Large Recommendation Models
Feb 11, 2026Driven by scaling laws, recommender systems increasingly rely on large-scale models to capture complex feature interactions and user behaviors, but this trend also leads to prohibitive training and inference costs. While long-sequence models(e.g., LONGER) can reuse user-side computation through KV caching, such reuse is difficult in dense feature interaction architectures(e.g., RankMixer), where user and group (candidate item) features are deeply entangled across layers. In this work, we propose User-Group Separation (UG-Sep), a novel framework that enables reusable user-side computation in dense interaction models for the first time. UG-Sep introduces a masking mechanism that explicitly disentangles user-side and item-side information flows within token-mixing layers, ensuring that a subset of tokens to preserve purely user-side representations across layers. This design enables corresponding token computations to be reused across multiple samples, significantly reducing redundant inference cost. To compensate for potential expressiveness loss induced by masking, we further propose an Information Compensation strategy that adaptively reconstructs suppressed user-item interactions. Moreover, as UG-Sep substantially reduces user-side FLOPs and exposes memory-bound components, we incorporate W8A16 (8-bit weight, 16-bit activation) weight-only quantization to alleviate memory bandwidth bottlenecks and achieve additional acceleration. We conduct extensive offline evaluations and large-scale online A/B experiments at ByteDance, demonstrating that UG-Sep reduces inference latency by up to 20 percent without degrading online user experience or commercial metrics across multiple business scenarios, including feed recommendation and advertising systems.
Make It Long, Keep It Fast: End-to-End 10k-Sequence Modeling at Billion Scale on Douyin
Nov 08, 2025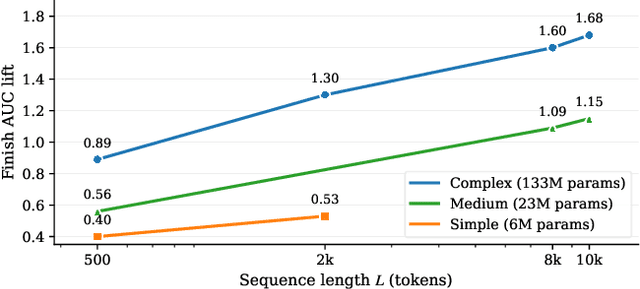
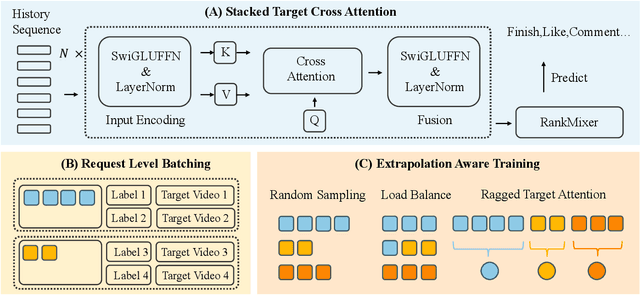

Short-video recommenders such as Douyin must exploit extremely long user histories without breaking latency or cost budgets. We present an end-to-end system that scales long-sequence modeling to 10k-length histories in production. First, we introduce Stacked Target-to-History Cross Attention (STCA), which replaces history self-attention with stacked cross-attention from the target to the history, reducing complexity from quadratic to linear in sequence length and enabling efficient end-to-end training. Second, we propose Request Level Batching (RLB), a user-centric batching scheme that aggregates multiple targets for the same user/request to share the user-side encoding, substantially lowering sequence-related storage, communication, and compute without changing the learning objective. Third, we design a length-extrapolative training strategy -- train on shorter windows, infer on much longer ones -- so the model generalizes to 10k histories without additional training cost. Across offline and online experiments, we observe predictable, monotonic gains as we scale history length and model capacity, mirroring the scaling law behavior observed in large language models. Deployed at full traffic on Douyin, our system delivers significant improvements on key engagement metrics while meeting production latency, demonstrating a practical path to scaling end-to-end long-sequence recommendation to the 10k regime.
Entire Space Learning Framework: Unbias Conversion Rate Prediction in Full Stages of Recommender System
Mar 01, 2023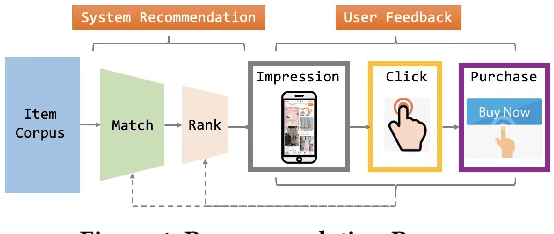

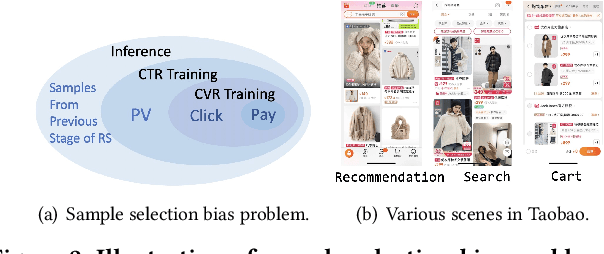

Recommender system is an essential part of online services, especially for e-commerce platform. Conversion Rate (CVR) prediction in RS plays a significant role in optimizing Gross Merchandise Volume (GMV) goal of e-commerce. However, CVR suffers from well-known Sample Selection Bias (SSB) and Data Sparsity (DS) problems. Although existing methods ESMM and ESM2 train with all impression samples over the entire space by modeling user behavior paths, SSB and DS problems still exist. In real practice, the online inference space are samples from previous stage of RS process, rather than the impression space modeled by existing methods. Moreover, existing methods solve the DS problem mainly by building behavior paths of their own specific scene, ignoring the behaviors in various scenes of e-commerce platform. In this paper, we propose Entire Space Learning Framework: Unbias Conversion Rate Prediction in Full Stages of Recommender System, solving SSB and DS problems by reformulating GMV goal in a novel manner. Specifically, we rebuild the CVR on the entire data space with samples from previous stage of RS process, unifying training and online inference space. Moreover, we explicitly introduce purchase samples from other scenes of e-commerce platform in model learning process. Online A/B test and offline experiments show the superiority of our framework. Our framework has been deployed in rank stage of Taobao recommendation, providing recommendation service for hundreds of millions of consumers everyday.
Hierarchical Multi-Interest Co-Network For Coarse-Grained Ranking
Oct 19, 2022
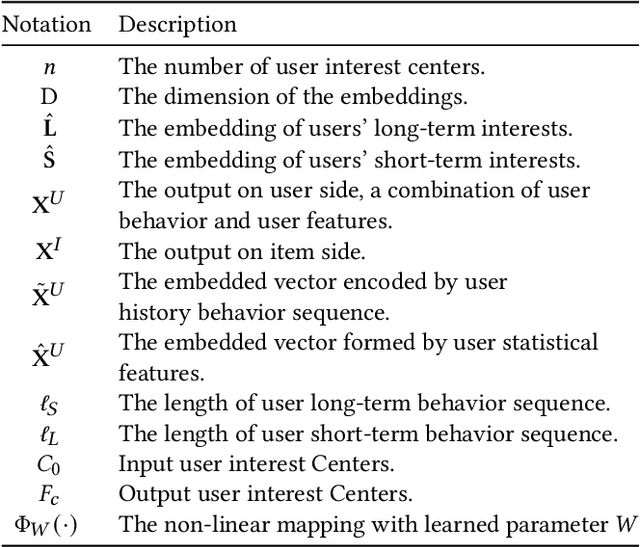
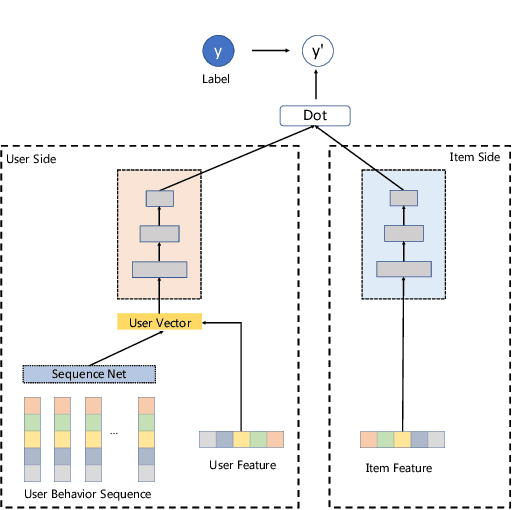
In this era of information explosion, a personalized recommendation system is convenient for users to get information they are interested in. To deal with billions of users and items, large-scale online recommendation services usually consist of three stages: candidate generation, coarse-grained ranking, and fine-grained ranking. The success of each stage depends on whether the model accurately captures the interests of users, which are usually hidden in users' behavior data. Previous research shows that users' interests are diverse, and one vector is not sufficient to capture users' different preferences. Therefore, many methods use multiple vectors to encode users' interests. However, there are two unsolved problems: (1) The similarity of different vectors in existing methods is too high, with too much redundant information. Consequently, the interests of users are not fully represented. (2) Existing methods model the long-term and short-term behaviors together, ignoring the differences between them. This paper proposes a Hierarchical Multi-Interest Co-Network (HCN) to capture users' diverse interests in the coarse-grained ranking stage. Specifically, we design a hierarchical multi-interest extraction layer to update users' diverse interest centers iteratively. The multiple embedded vectors obtained in this way contain more information and represent the interests of users better in various aspects. Furthermore, we develop a Co-Interest Network to integrate users' long-term and short-term interests. Experiments on several real-world datasets and one large-scale industrial dataset show that HCN effectively outperforms the state-of-the-art methods. We deploy HCN into a large-scale real world E-commerce system and achieve extra 2.5\% improvements on GMV (Gross Merchandise Value).
Efficient Long Sequential User Data Modeling for Click-Through Rate Prediction
Sep 25, 2022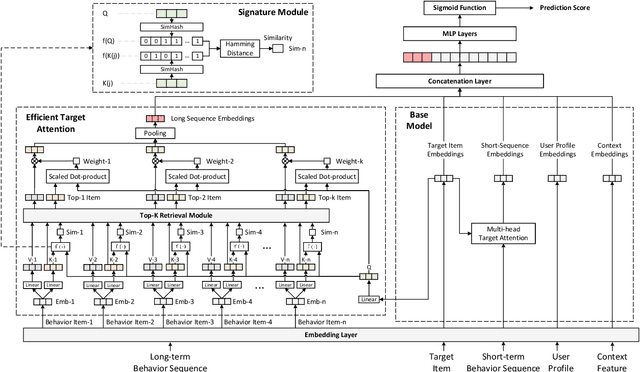

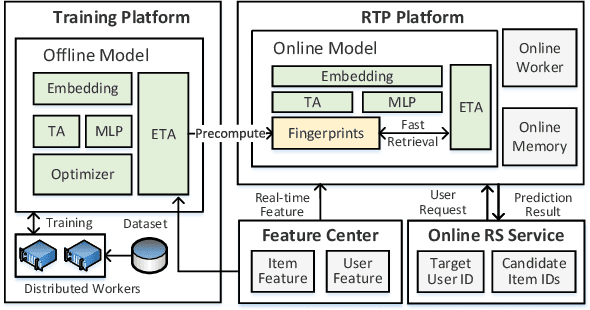

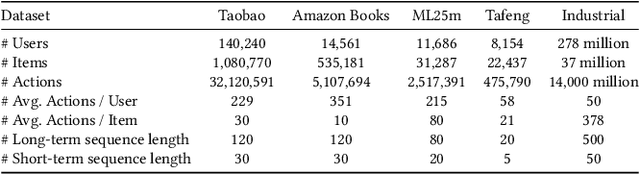
Recent studies on Click-Through Rate (CTR) prediction has reached new levels by modeling longer user behavior sequences. Among others, the two-stage methods stand out as the state-of-the-art (SOTA) solution for industrial applications. The two-stage methods first train a retrieval model to truncate the long behavior sequence beforehand and then use the truncated sequences to train a CTR model. However, the retrieval model and the CTR model are trained separately. So the retrieved subsequences in the CTR model is inaccurate, which degrades the final performance. In this paper, we propose an end-to-end paradigm to model long behavior sequences, which is able to achieve superior performance along with remarkable cost-efficiency compared to existing models. Our contribution is three-fold: First, we propose a hashing-based efficient target attention (TA) network named ETA-Net to enable end-to-end user behavior retrieval based on low-cost bit-wise operations. The proposed ETA-Net can reduce the complexity of standard TA by orders of magnitude for sequential data modeling. Second, we propose a general system architecture as one viable solution to deploy ETA-Net on industrial systems. Particularly, ETA-Net has been deployed on the recommender system of Taobao, and brought 1.8% lift on CTR and 3.1% lift on Gross Merchandise Value (GMV) compared to the SOTA two-stage methods. Third, we conduct extensive experiments on both offline datasets and online A/B test. The results verify that the proposed model outperforms existing CTR models considerably, in terms of both CTR prediction performance and online cost-efficiency. ETA-Net now serves the main traffic of Taobao, delivering services to hundreds of millions of users towards billions of items every day.
End-to-End User Behavior Retrieval in Click-Through RatePrediction Model
Aug 10, 2021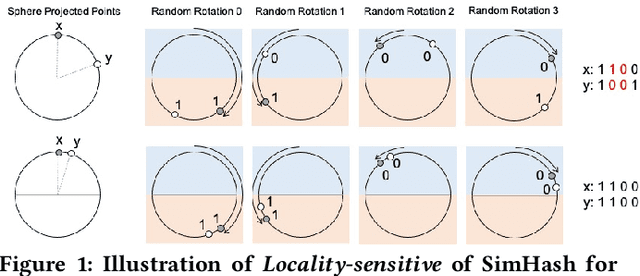

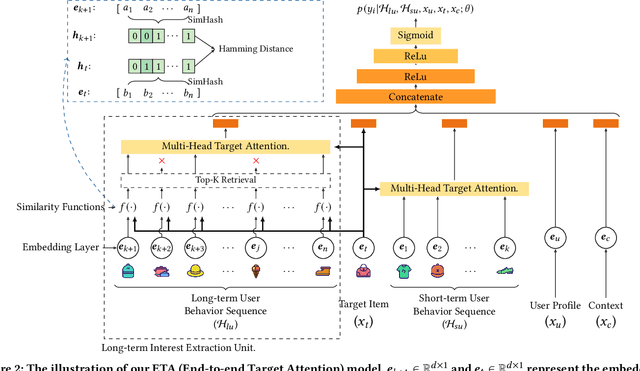

Click-Through Rate (CTR) prediction is one of the core tasks in recommender systems (RS). It predicts a personalized click probability for each user-item pair. Recently, researchers have found that the performance of CTR model can be improved greatly by taking user behavior sequence into consideration, especially long-term user behavior sequence. The report on an e-commerce website shows that 23\% of users have more than 1000 clicks during the past 5 months. Though there are numerous works focus on modeling sequential user behaviors, few works can handle long-term user behavior sequence due to the strict inference time constraint in real world system. Two-stage methods are proposed to push the limit for better performance. At the first stage, an auxiliary task is designed to retrieve the top-$k$ similar items from long-term user behavior sequence. At the second stage, the classical attention mechanism is conducted between the candidate item and $k$ items selected in the first stage. However, information gap happens between retrieval stage and the main CTR task. This goal divergence can greatly diminishing the performance gain of long-term user sequence. In this paper, inspired by Reformer, we propose a locality-sensitive hashing (LSH) method called ETA (End-to-end Target Attention) which can greatly reduce the training and inference cost and make the end-to-end training with long-term user behavior sequence possible. Both offline and online experiments confirm the effectiveness of our model. We deploy ETA into a large-scale real world E-commerce system and achieve extra 3.1\% improvements on GMV (Gross Merchandise Value) compared to a two-stage long user sequence CTR model.
Dynamic Routing for Traffic Flow through Multi-agent Systems
May 02, 2021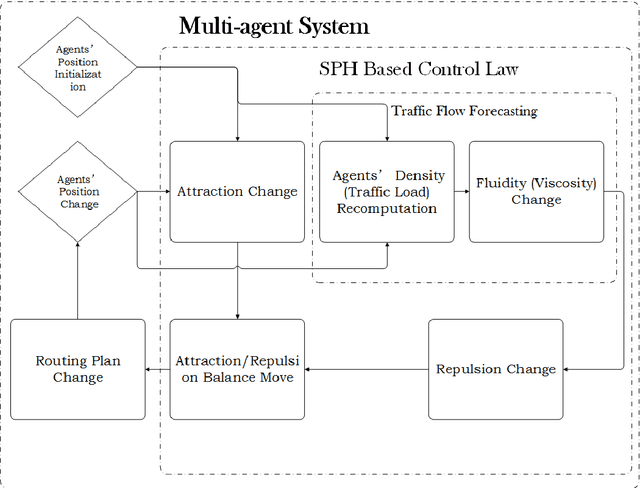
Routing strategies for traffics and vehicles have been historically studied. However, in the absence of considering drivers' preferences, current route planning algorithms are developed under ideal situations where all drivers are expected to behave rationally and properly. Especially, for jumbled urban road networks, drivers' actual routing strategies deteriorated to a series of empirical and selfish decisions that result in congestion. Self-evidently, if minimum mobility can be kept, traffic congestion is avoidable by traffic load dispersing. In this paper, we establish a novel dynamic routing method catering drivers' preferences and retaining maximum traffic mobility simultaneously through multi-agent systems (MAS). Modeling human-drivers' behavior through agents' dynamics, MAS can analyze the global behavior of the entire traffic flow. Therefore, regarding agents as particles in smoothed particles hydrodynamics (SPH), we can enforce the traffic flow to behave like a real flow. Thereby, with the characteristic of distributing itself uniformly in road networks, our dynamic routing method realizes traffic load balancing without violating the individual time-saving motivation. Moreover, as a discrete control mechanism, our method is robust to chaos meaning driver's disobedience can be tolerated. As controlled by SPH based density, the only intelligent transportation system (ITS) we require is the location-based service (LBS). A mathematical proof is accomplished to scrutinize the stability of the proposed control law. Also, multiple testing cases are built to verify the effectiveness of the proposed dynamic routing algorithm.
Behavior Sequence Transformer for E-commerce Recommendation in Alibaba
May 15, 2019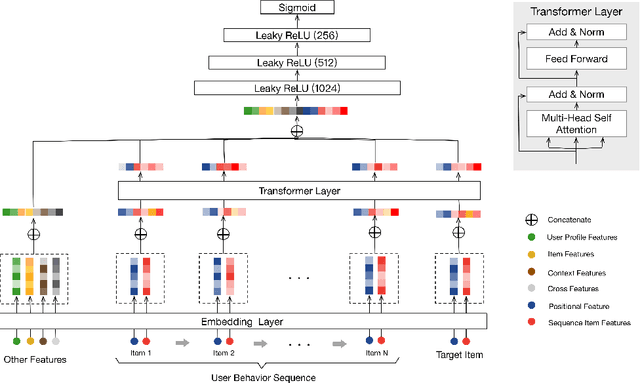



Deep learning based methods have been widely used in industrial recommendation systems (RSs). Previous works adopt an Embedding&MLP paradigm: raw features are embedded into low-dimensional vectors, which are then fed on to MLP for final recommendations. However, most of these works just concatenate different features, ignoring the sequential nature of users' behaviors. In this paper, we propose to use the powerful Transformer model to capture the sequential signals underlying users' behavior sequences for recommendation in Alibaba. Experimental results demonstrate the superiority of the proposed model, which is then deployed online at Taobao and obtain significant improvements in online Click-Through-Rate (CTR) comparing to two baselines.