 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning Under Attack: Exposing Vulnerabilities through Data Poisoning Attacks in Computer Networks
Mar 05, 2024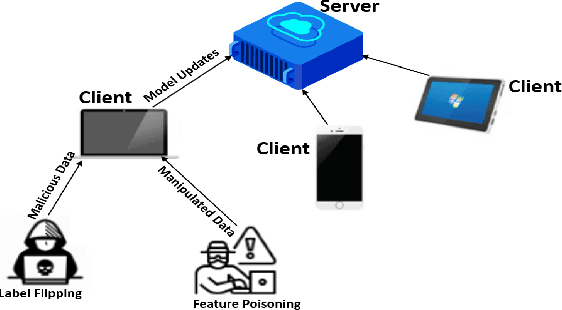
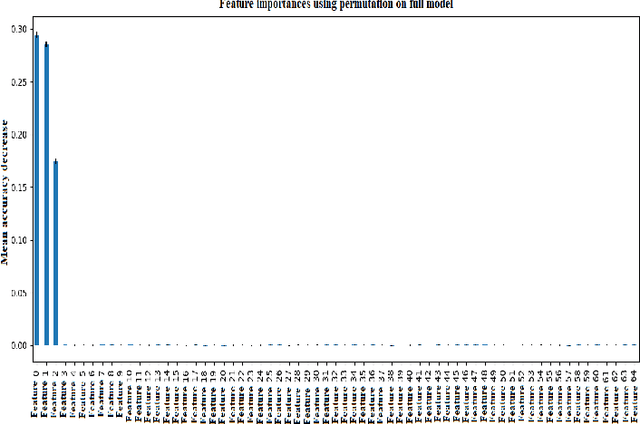

Federated Learning (FL) is a machine learning (ML) approach that enables multiple decentralized devices or edge servers to collaboratively train a shared model without exchanging raw data. During the training and sharing of model updates between clients and servers, data and models are susceptible to different data-poisoning attacks. In this study, our motivation is to explore the severity of data poisoning attacks in the computer network domain because they are easy to implement but difficult to detect. We considered two types of data-poisoning attacks, label flipping (LF) and feature poisoning (FP), and applied them with a novel approach. In LF, we randomly flipped the labels of benign data and trained the model on the manipulated data. For FP, we randomly manipulated the highly contributing features determined using the Random Forest algorithm. The datasets used in this experiment were CIC and UNSW related to computer networks. We generated adversarial samples using the two attacks mentioned above, which were applied to a small percentage of datasets. Subsequently, we trained and tested the accuracy of the model on adversarial datasets. We recorded the results for both benign and manipulated datasets and observed significant differences between the accuracy of the models on different datasets. From the experimental results, it is evident that the LF attack failed, whereas the FP attack showed effective results, which proved its significance in fooling a server. With a 1% LF attack on the CIC, the accuracy was approximately 0.0428 and the ASR was 0.9564; hence, the attack is easily detectable, while with a 1% FP attack, the accuracy and ASR were both approximately 0.9600, hence, FP attacks are difficult to detect. We repeated the experiment with different poisoning percentages.
UNBUS: Uncertainty-aware Deep Botnet Detection System in Presence of Perturbed Samples
Apr 28, 2022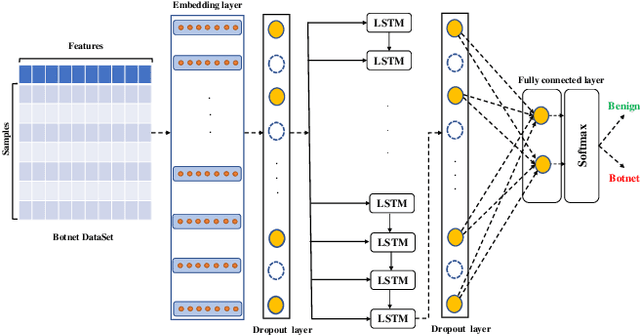
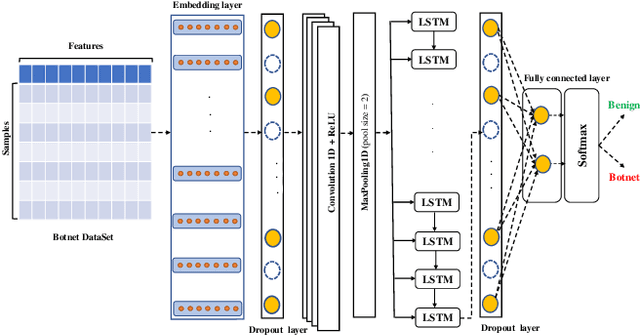
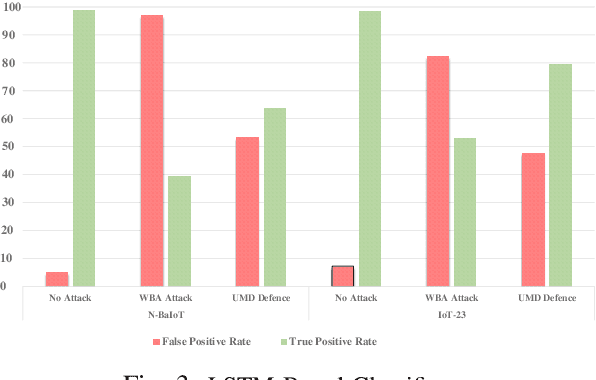
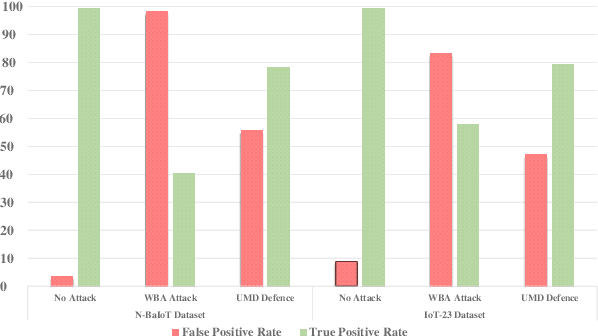
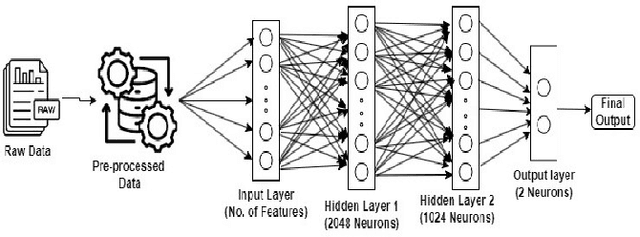
A rising number of botnet families have been successfully detected using deep learning architectures. While the variety of attacks increases, these architectures should become more robust against attacks. They have been proven to be very sensitive to small but well constructed perturbations in the input. Botnet detection requires extremely low false-positive rates (FPR), which are not commonly attainable in contemporary deep learning. Attackers try to increase the FPRs by making poisoned samples. The majority of recent research has focused on the use of model loss functions to build adversarial examples and robust models. In this paper, two LSTM-based classification algorithms for botnet classification with an accuracy higher than 98% are presented. Then, the adversarial attack is proposed, which reduces the accuracy to about 30%. Then, by examining the methods for computing the uncertainty, the defense method is proposed to increase the accuracy to about 70%. By using the deep ensemble and stochastic weight averaging quantification methods it has been investigated the uncertainty of the accuracy in the proposed methods.
SETTI: A Self-supervised Adversarial Malware Detection Architecture in an IoT Environment
Apr 16, 2022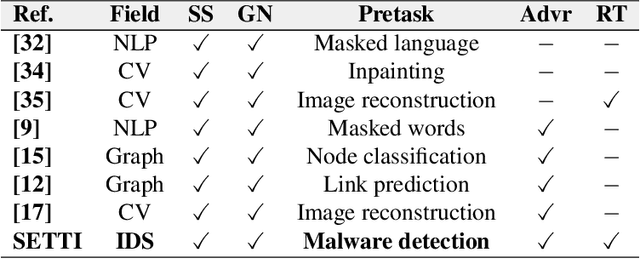
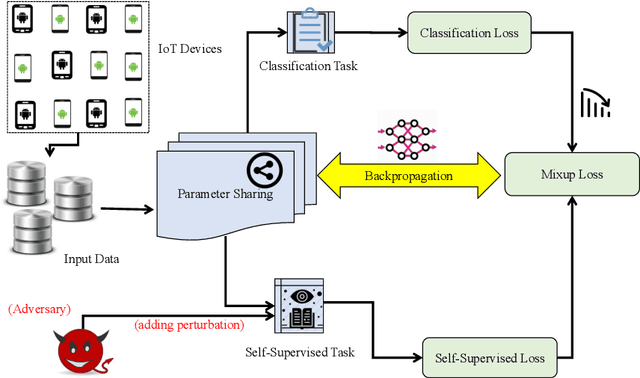
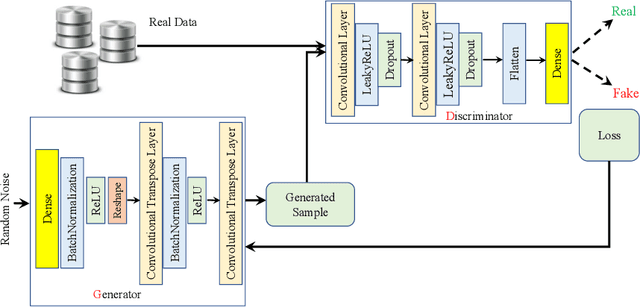
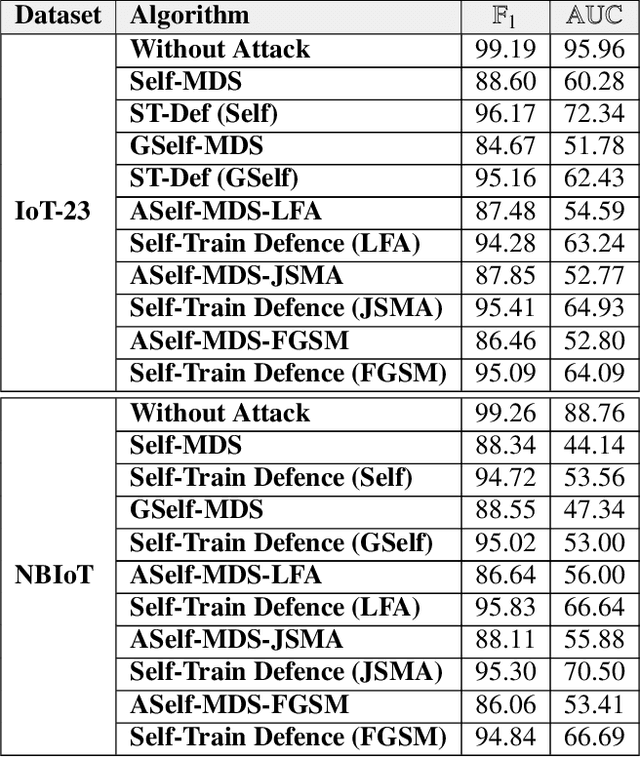
In recent years, malware detection has become an active research topic in the area of Internet of Things (IoT) security. The principle is to exploit knowledge from large quantities of continuously generated malware. Existing algorithms practice available malware features for IoT devices and lack real-time prediction behaviors. More research is thus required on malware detection to cope with real-time misclassification of the input IoT data. Motivated by this, in this paper we propose an adversarial self-supervised architecture for detecting malware in IoT networks, SETTI, considering samples of IoT network traffic that may not be labeled. In the SETTI architecture, we design three self-supervised attack techniques, namely Self-MDS, GSelf-MDS and ASelf-MDS. The Self-MDS method considers the IoT input data and the adversarial sample generation in real-time. The GSelf-MDS builds a generative adversarial network model to generate adversarial samples in the self-supervised structure. Finally, ASelf-MDS utilizes three well-known perturbation sample techniques to develop adversarial malware and inject it over the self-supervised architecture. Also, we apply a defence method to mitigate these attacks, namely adversarial self-supervised training to protect the malware detection architecture against injecting the malicious samples. To validate the attack and defence algorithms, we conduct experiments on two recent IoT datasets: IoT23 and NBIoT. Comparison of the results shows that in the IoT23 dataset, the Self-MDS method has the most damaging consequences from the attacker's point of view by reducing the accuracy rate from 98% to 74%. In the NBIoT dataset, the ASelf-MDS method is the most devastating algorithm that can plunge the accuracy rate from 98% to 77%.
Deep Image: A precious image based deep learning method for online malware detection in IoT Environment
Apr 04, 2022
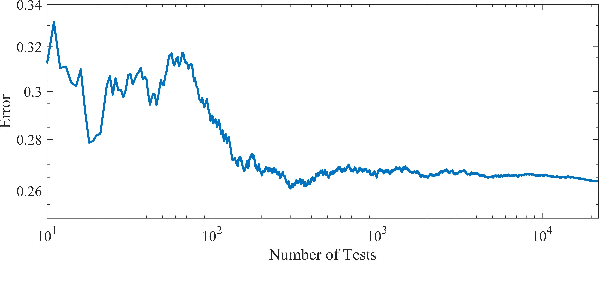
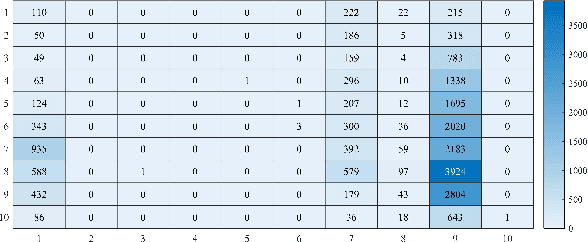
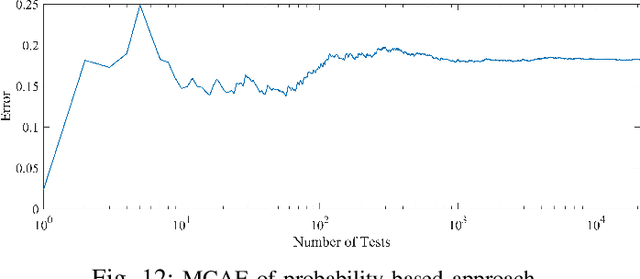
The volume of malware and the number of attacks in IoT devices are rising everyday, which encourages security professionals to continually enhance their malware analysis tools. Researchers in the field of cyber security have extensively explored the usage of sophisticated analytics and the efficiency of malware detection. With the introduction of new malware kinds and attack routes, security experts confront considerable challenges in developing efficient malware detection and analysis solutions. In this paper, a different view of malware analysis is considered and the risk level of each sample feature is computed, and based on that the risk level of that sample is calculated. In this way, a criterion is introduced that is used together with accuracy and FPR criteria for malware analysis in IoT environment. In this paper, three malware detection methods based on visualization techniques called the clustering approach, the probabilistic approach, and the deep learning approach are proposed. Then, in addition to the usual machine learning criteria namely accuracy and FPR, a proposed criterion based on the risk of samples has also been used for comparison, with the results showing that the deep learning approach performed better in detecting malware
Similarity-based Android Malware Detection Using Hamming Distance of Static Binary Features
Aug 13, 2019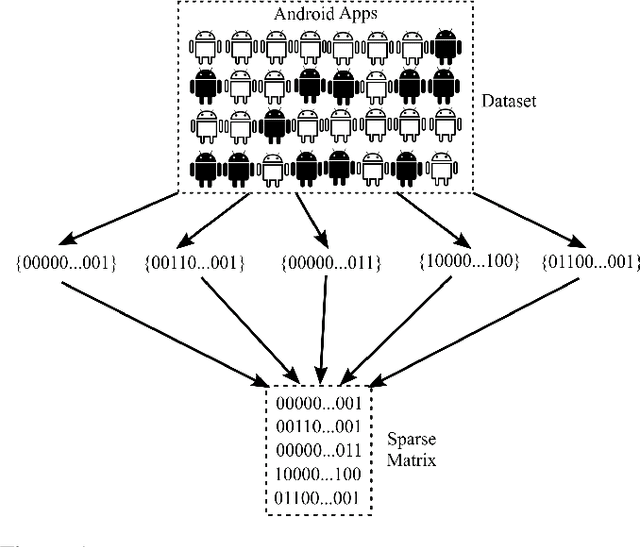
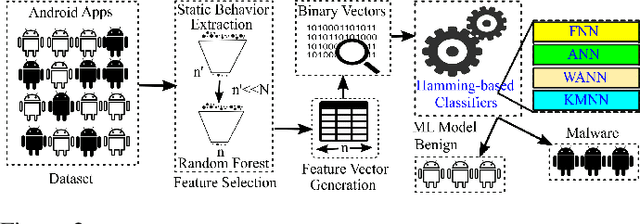
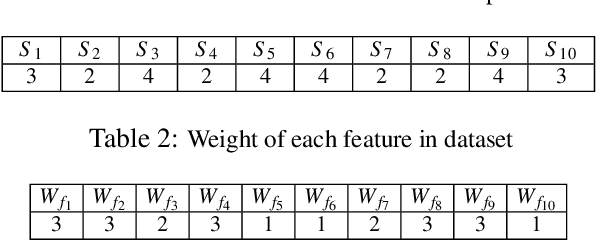
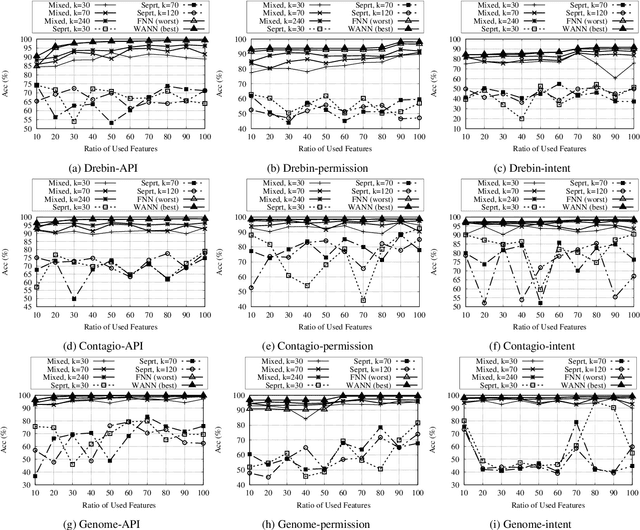
In this paper, we develop four malware detection methods using Hamming distance to find similarity between samples which are first nearest neighbors (FNN), all nearest neighbors (ANN), weighted all nearest neighbors (WANN), and k-medoid based nearest neighbors (KMNN). In our proposed methods, we can trigger the alarm if we detect an Android app is malicious. Hence, our solutions help us to avoid the spread of detected malware on a broader scale. We provide a detailed description of the proposed detection methods and related algorithms. We include an extensive analysis to asses the suitability of our proposed similarity-based detection methods. In this way, we perform our experiments on three datasets, including benign and malware Android apps like Drebin, Contagio, and Genome. Thus, to corroborate the actual effectiveness of our classifier, we carry out performance comparisons with some state-of-the-art classification and malware detection algorithms, namely Mixed and Separated solutions, the program dissimilarity measure based on entropy (PDME) and the FalDroid algorithms. We test our experiments in a different type of features: API, intent, and permission features on these three datasets. The results confirm that accuracy rates of proposed algorithms are more than 90% and in some cases (i.e., considering API features) are more than 99%, and are comparable with existing state-of-the-art solutions.
On Defending Against Label Flipping Attacks on Malware Detection Systems
Aug 13, 2019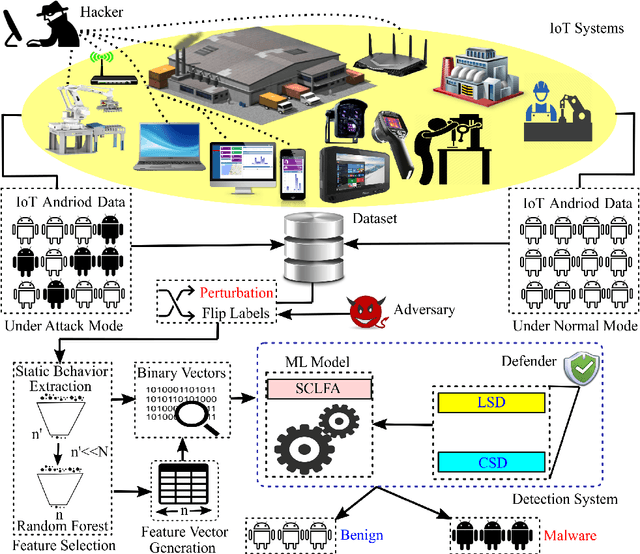
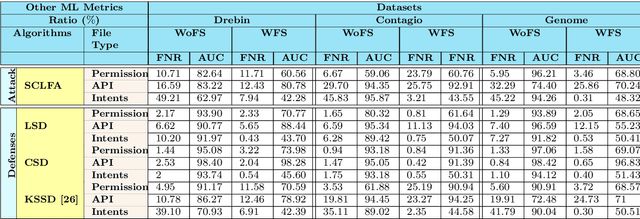

Label manipulation attacks are a subclass of data poisoning attacks in adversarial machine learning used against different applications, such as malware detection. These types of attacks represent a serious threat to detection systems in environments having high noise rate or uncertainty, such as complex networks and Internet of Thing (IoT). Recent work in the literature has suggested using the $K$-Nearest Neighboring (KNN) algorithm to defend against such attacks. However, such an approach can suffer from low to wrong detection accuracy. In this paper, we design an architecture to tackle the Android malware detection problem in IoT systems. We develop an attack mechanism based on Silhouette clustering method, modified for mobile Android platforms. We proposed two Convolutional Neural Network (CNN)-type deep learning algorithms against this \emph{Silhouette Clustering-based Label Flipping Attack (SCLFA)}. We show the effectiveness of these two defense algorithms - \emph{Label-based Semi-supervised Defense (LSD)} and \emph{clustering-based Semi-supervised Defense (CSD)} - in correcting labels being attacked. We evaluate the performance of the proposed algorithms by varying the various machine learning parameters on three Android datasets: Drebin, Contagio, and Genome and three types of features: API, intent, and permission. Our evaluation shows that using random forest feature selection and varying ratios of features can result in an improvement of up to 19\% accuracy when compared with the state-of-the-art method in the literature.
Can Machine Learning Model with Static Features be Fooled: an Adversarial Machine Learning Approach
Apr 20, 2019



The widespread adoption of smartphones dramatically increases the risk of attacks and the spread of mobile malware, especially on the Android platform. Machine learning based solutions have been already used as a tool to supersede signature based anti-malware systems. However, malware authors leverage attributes from malicious and legitimate samples to estimate statistical difference in-order to create adversarial examples. Hence, to evaluate the vulnerability of machine learning algorithms in malware detection, we propose five different attack scenarios to perturb malicious applications (apps). By doing this, the classification algorithm inappropriately fits discriminant function on the set of data points, eventually yielding a higher misclassification rate. Further, to distinguish the adversarial examples from benign samples, we propose two defense mechanisms to counter attacks. To validate our attacks and solutions, we test our model on three different benchmark datasets. We also test our methods using various classifier algorithms and compare them with the state-of-the-art data poisoning method using the Jacobian matrix. Promising results show that generated adversarial samples can evade detection with a very high probability. Additionally, evasive variants generated by our attacks models when used to harden the developed anti-malware system improves the detection rate.