 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning Under Attack: Exposing Vulnerabilities through Data Poisoning Attacks in Computer Networks
Mar 05, 2024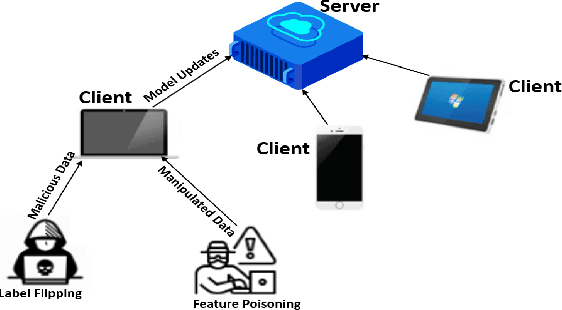
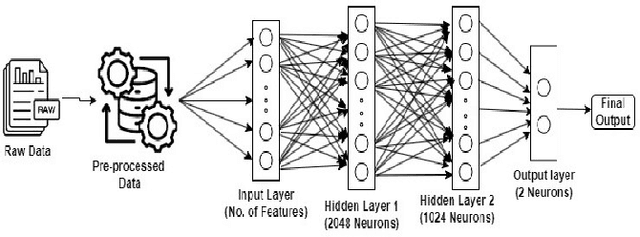
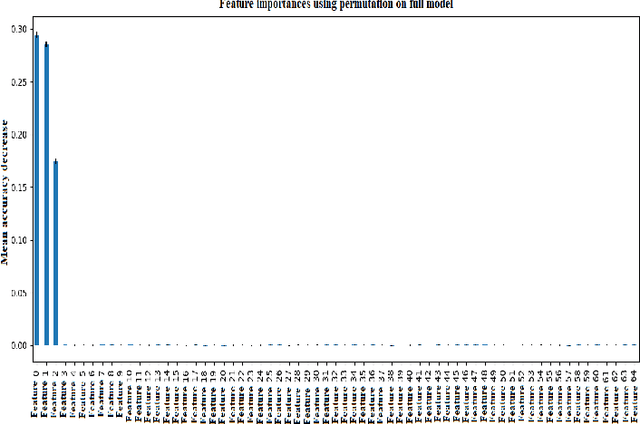

Federated Learning (FL) is a machine learning (ML) approach that enables multiple decentralized devices or edge servers to collaboratively train a shared model without exchanging raw data. During the training and sharing of model updates between clients and servers, data and models are susceptible to different data-poisoning attacks. In this study, our motivation is to explore the severity of data poisoning attacks in the computer network domain because they are easy to implement but difficult to detect. We considered two types of data-poisoning attacks, label flipping (LF) and feature poisoning (FP), and applied them with a novel approach. In LF, we randomly flipped the labels of benign data and trained the model on the manipulated data. For FP, we randomly manipulated the highly contributing features determined using the Random Forest algorithm. The datasets used in this experiment were CIC and UNSW related to computer networks. We generated adversarial samples using the two attacks mentioned above, which were applied to a small percentage of datasets. Subsequently, we trained and tested the accuracy of the model on adversarial datasets. We recorded the results for both benign and manipulated datasets and observed significant differences between the accuracy of the models on different datasets. From the experimental results, it is evident that the LF attack failed, whereas the FP attack showed effective results, which proved its significance in fooling a server. With a 1% LF attack on the CIC, the accuracy was approximately 0.0428 and the ASR was 0.9564; hence, the attack is easily detectable, while with a 1% FP attack, the accuracy and ASR were both approximately 0.9600, hence, FP attacks are difficult to detect. We repeated the experiment with different poisoning percentages.
Unscrambling the Rectification of Adversarial Attacks Transferability across Computer Networks
Oct 26, 2023Convolutional neural networks (CNNs) models play a vital role in achieving state-of-the-art performances in various technological fields. CNNs are not limited to Natural Language Processing (NLP) or Computer Vision (CV) but also have substantial applications in other technological domains, particularly in cybersecurity. The reliability of CNN's models can be compromised because of their susceptibility to adversarial attacks, which can be generated effortlessly, easily applied, and transferred in real-world scenarios. In this paper, we present a novel and comprehensive method to improve the strength of attacks and assess the transferability of adversarial examples in CNNs when such strength changes, as well as whether the transferability property issue exists in computer network applications. In the context of our study, we initially examined six distinct modes of attack: the Carlini and Wagner (C&W), Fast Gradient Sign Method (FGSM), Iterative Fast Gradient Sign Method (I-FGSM), Jacobian-based Saliency Map (JSMA), Limited-memory Broyden fletcher Goldfarb Shanno (L-BFGS), and Projected Gradient Descent (PGD) attack. We applied these attack techniques on two popular datasets: the CIC and UNSW datasets. The outcomes of our experiment demonstrate that an improvement in transferability occurs in the targeted scenarios for FGSM, JSMA, LBFGS, and other attacks. Our findings further indicate that the threats to security posed by adversarial examples, even in computer network applications, necessitate the development of novel defense mechanisms to enhance the security of DL-based techniques.