 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Security Vulnerabilities: A Metric-Driven Security Analysis of Gaps in Current AI Standards
Feb 12, 2025As AI systems integrate into critical infrastructure, security gaps in AI compliance frameworks demand urgent attention. This paper audits and quantifies security risks in three major AI governance standards: NIST AI RMF 1.0, UK's AI and Data Protection Risk Toolkit, and the EU's ALTAI. Using a novel risk assessment methodology, we develop four key metrics: Risk Severity Index (RSI), Attack Potential Index (AVPI), Compliance-Security Gap Percentage (CSGP), and Root Cause Vulnerability Score (RCVS). Our analysis identifies 136 concerns across the frameworks, exposing significant gaps. NIST fails to address 69.23 percent of identified risks, ALTAI has the highest attack vector vulnerability (AVPI = 0.51) and the ICO Toolkit has the largest compliance-security gap, with 80.00 percent of high-risk concerns remaining unresolved. Root cause analysis highlights under-defined processes (ALTAI RCVS = 033) and weak implementation guidance (NIST and ICO RCVS = 0.25) as critical weaknesses. These findings emphasize the need for stronger, enforceable security controls in AI compliance. We offer targeted recommendations to enhance security posture and bridge the gap between compliance and real-world AI risks.
Unscrambling the Rectification of Adversarial Attacks Transferability across Computer Networks
Oct 26, 2023



Convolutional neural networks (CNNs) models play a vital role in achieving state-of-the-art performances in various technological fields. CNNs are not limited to Natural Language Processing (NLP) or Computer Vision (CV) but also have substantial applications in other technological domains, particularly in cybersecurity. The reliability of CNN's models can be compromised because of their susceptibility to adversarial attacks, which can be generated effortlessly, easily applied, and transferred in real-world scenarios. In this paper, we present a novel and comprehensive method to improve the strength of attacks and assess the transferability of adversarial examples in CNNs when such strength changes, as well as whether the transferability property issue exists in computer network applications. In the context of our study, we initially examined six distinct modes of attack: the Carlini and Wagner (C&W), Fast Gradient Sign Method (FGSM), Iterative Fast Gradient Sign Method (I-FGSM), Jacobian-based Saliency Map (JSMA), Limited-memory Broyden fletcher Goldfarb Shanno (L-BFGS), and Projected Gradient Descent (PGD) attack. We applied these attack techniques on two popular datasets: the CIC and UNSW datasets. The outcomes of our experiment demonstrate that an improvement in transferability occurs in the targeted scenarios for FGSM, JSMA, LBFGS, and other attacks. Our findings further indicate that the threats to security posed by adversarial examples, even in computer network applications, necessitate the development of novel defense mechanisms to enhance the security of DL-based techniques.
Deep Fake Detection, Deterrence and Response: Challenges and Opportunities
Nov 26, 2022
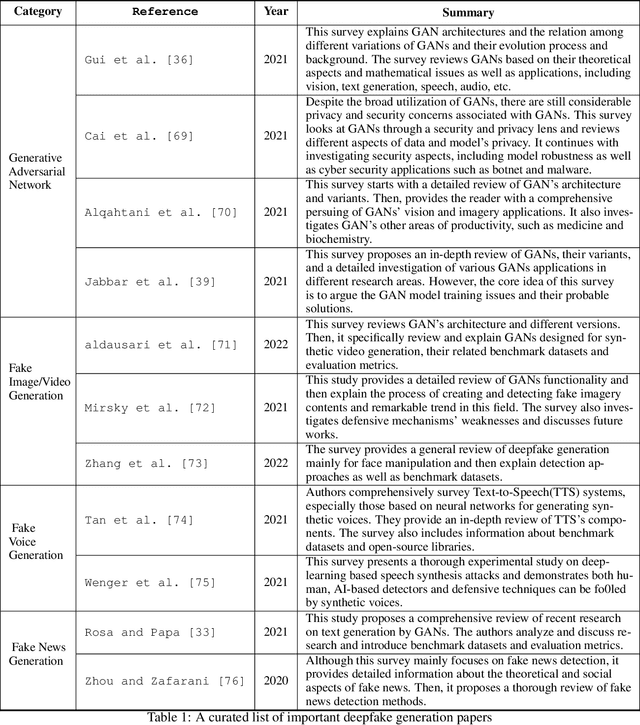


According to the 2020 cyber threat defence report, 78% of Canadian organizations experienced at least one successful cyberattack in 2020. The consequences of such attacks vary from privacy compromises to immersing damage costs for individuals, companies, and countries. Specialists predict that the global loss from cybercrime will reach 10.5 trillion US dollars annually by 2025. Given such alarming statistics, the need to prevent and predict cyberattacks is as high as ever. Our increasing reliance on Machine Learning(ML)-based systems raises serious concerns about the security and safety of these systems. Especially the emergence of powerful ML techniques to generate fake visual, textual, or audio content with a high potential to deceive humans raised serious ethical concerns. These artificially crafted deceiving videos, images, audio, or texts are known as Deepfakes garnered attention for their potential use in creating fake news, hoaxes, revenge porn, and financial fraud. Diversity and the widespread of deepfakes made their timely detection a significant challenge. In this paper, we first offer background information and a review of previous works on the detection and deterrence of deepfakes. Afterward, we offer a solution that is capable of 1) making our AI systems robust against deepfakes during development and deployment phases; 2) detecting video, image, audio, and textual deepfakes; 3) identifying deepfakes that bypass detection (deepfake hunting); 4) leveraging available intelligence for timely identification of deepfake campaigns launched by state-sponsored hacking teams; 5) conducting in-depth forensic analysis of identified deepfake payloads. Our solution would address important elements of the Canada National Cyber Security Action Plan(2019-2024) in increasing the trustworthiness of our critical services.
A Survey of Machine Learning Techniques in Adversarial Image Forensics
Oct 19, 2020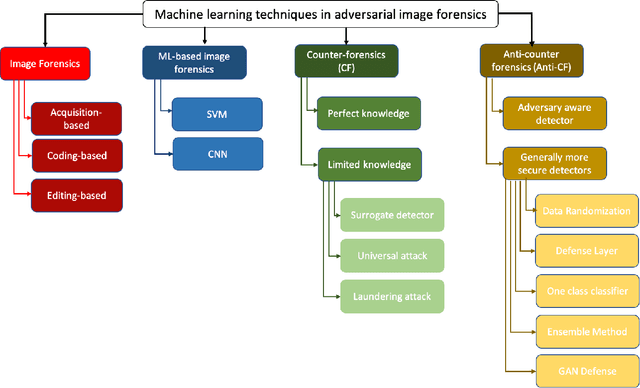


Image forensic plays a crucial role in both criminal investigations (e.g., dissemination of fake images to spread racial hate or false narratives about specific ethnicity groups) and civil litigation (e.g., defamation). Increasingly, machine learning approaches are also utilized in image forensics. However, there are also a number of limitations and vulnerabilities associated with machine learning-based approaches, for example how to detect adversarial (image) examples, with real-world consequences (e.g., inadmissible evidence, or wrongful conviction). Therefore, with a focus on image forensics, this paper surveys techniques that can be used to enhance the robustness of machine learning-based binary manipulation detectors in various adversarial scenarios.
* 37 pages, 24 figures, Accepted to the Journal Computer and Security (Elsevier)
Smart Grid Cyber Attacks Detection using Supervised Learning and Heuristic Feature Selection
Jul 07, 2019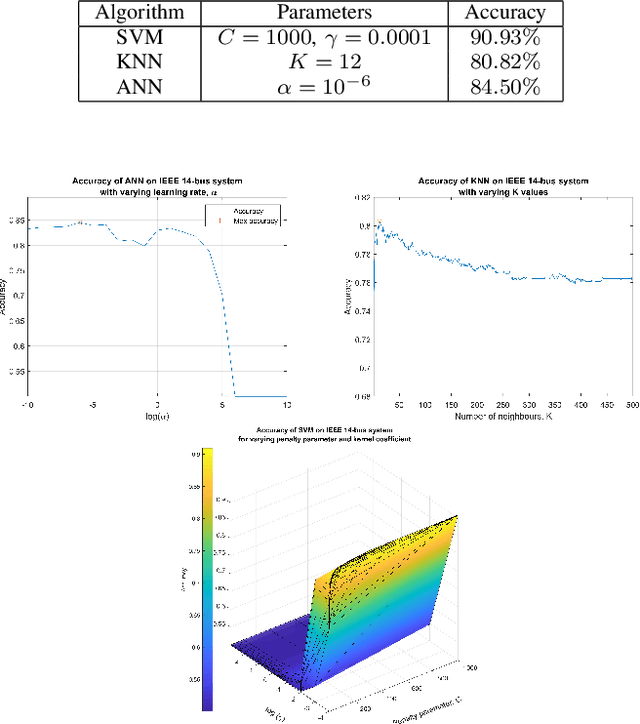

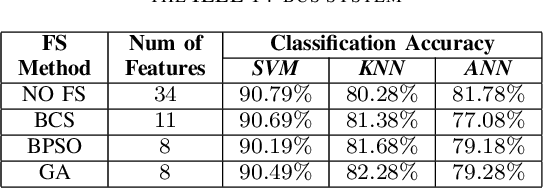
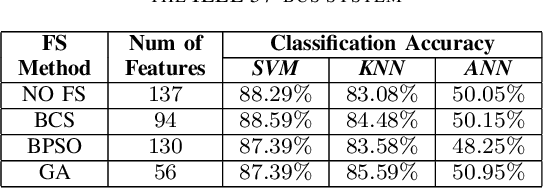
False Data Injection (FDI) attacks are a common form of Cyber-attack targetting smart grids. Detection of stealthy FDI attacks is impossible by the current bad data detection systems. Machine learning is one of the alternative methods proposed to detect FDI attacks. This paper analyzes three various supervised learning techniques, each to be used with three different feature selection (FS) techniques. These methods are tested on the IEEE 14-bus, 57-bus, and 118-bus systems for evaluation of versatility. Accuracy of the classification is used as the main evaluation method for each detection technique. Simulation study clarify the supervised learning combined with heuristic FS methods result in an improved performance of the classification algorithms for FDI attack detection.