 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVirPro: Visual-referred Probabilistic Prompt Learning for Weakly-Supervised Monocular 3D Detection
Mar 18, 2026Monocular 3D object detection typically relies on pseudo-labeling techniques to reduce dependency on real-world annotations. Recent advances demonstrate that deterministic linguistic cues can serve as effective auxiliary weak supervision signals, providing complementary semantic context. However, hand-crafted textual descriptions struggle to capture the inherent visual diversity of individuals across scenes, limiting the model's ability to learn scene-aware representations. To address this challenge, we propose Visual-referred Probabilistic Prompt Learning (VirPro), an adaptive multi-modal pretraining paradigm that can be seamlessly integrated into diverse weakly supervised monocular 3D detection frameworks. Specifically, we generate a diverse set of learnable, instance-conditioned prompts across scenes and store them in an Adaptive Prompt Bank (APB). Subsequently, we introduce Multi-Gaussian Prompt Modeling (MGPM), which incorporates scene-based visual features into the corresponding textual embeddings, allowing the text prompts to express visual uncertainties. Then, from the fused vision-language embeddings, we decode a prompt-targeted Gaussian, from which we derive a unified object-level prompt embedding for each instance. RoI-level contrastive matching is employed to enforce modality alignment, bringing embeddings of co-occurring objects within the same scene closer in the latent space, thus enhancing semantic coherence. Extensive experiments on the KITTI benchmark demonstrate that integrating our pretraining paradigm consistently yields substantial performance gains, achieving up to a 4.8% average precision improvement than the baseline.
Where Not to Learn: Prior-Aligned Training with Subset-based Attribution Constraints for Reliable Decision-Making
Jan 30, 2026Reliable models should not only predict correctly, but also justify decisions with acceptable evidence. Yet conventional supervised learning typically provides only class-level labels, allowing models to achieve high accuracy through shortcut correlations rather than the intended evidence. Human priors can help constrain such behavior, but aligning models to these priors remains challenging because learned representations often diverge from human perception. To address this challenge, we propose an attribution-based human prior alignment method. We encode human priors as input regions that the model is expected to rely on (e.g., bounding boxes), and leverage a highly faithful subset-selection-based attribution approach to expose the model's decision evidence during training. When the attribution region deviates substantially from the prior regions, we penalize reliance on off-prior evidence, encouraging the model to shift its attribution toward the intended regions. This is achieved through a training objective that imposes attribution constraints induced by the human prior. We validate our method on both image classification and click decision tasks in MLLM-based GUI agent models. Across conventional classification and autoregressive generation settings, human prior alignment consistently improves task accuracy while also enhancing the model's decision reasonability.
A Survey of Scientific Large Language Models: From Data Foundations to Agent Frontiers
Aug 28, 2025



Scientific Large Language Models (Sci-LLMs) are transforming how knowledge is represented, integrated, and applied in scientific research, yet their progress is shaped by the complex nature of scientific data. This survey presents a comprehensive, data-centric synthesis that reframes the development of Sci-LLMs as a co-evolution between models and their underlying data substrate. We formulate a unified taxonomy of scientific data and a hierarchical model of scientific knowledge, emphasizing the multimodal, cross-scale, and domain-specific challenges that differentiate scientific corpora from general natural language processing datasets. We systematically review recent Sci-LLMs, from general-purpose foundations to specialized models across diverse scientific disciplines, alongside an extensive analysis of over 270 pre-/post-training datasets, showing why Sci-LLMs pose distinct demands -- heterogeneous, multi-scale, uncertainty-laden corpora that require representations preserving domain invariance and enabling cross-modal reasoning. On evaluation, we examine over 190 benchmark datasets and trace a shift from static exams toward process- and discovery-oriented assessments with advanced evaluation protocols. These data-centric analyses highlight persistent issues in scientific data development and discuss emerging solutions involving semi-automated annotation pipelines and expert validation. Finally, we outline a paradigm shift toward closed-loop systems where autonomous agents based on Sci-LLMs actively experiment, validate, and contribute to a living, evolving knowledge base. Collectively, this work provides a roadmap for building trustworthy, continually evolving artificial intelligence (AI) systems that function as a true partner in accelerating scientific discovery.
Semi-Supervised State-Space Model with Dynamic Stacking Filter for Real-World Video Deraining
May 22, 2025

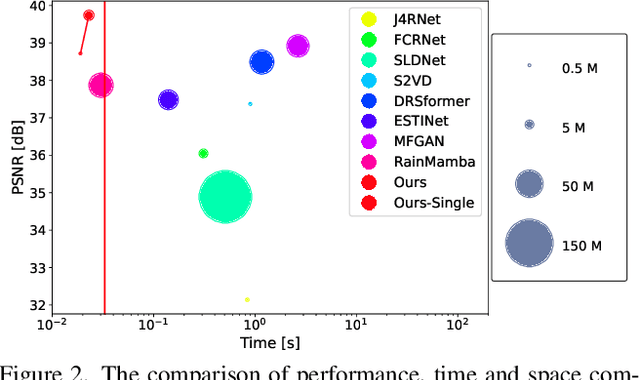

Significant progress has been made in video restoration under rainy conditions over the past decade, largely propelled by advancements in deep learning. Nevertheless, existing methods that depend on paired data struggle to generalize effectively to real-world scenarios, primarily due to the disparity between synthetic and authentic rain effects. To address these limitations, we propose a dual-branch spatio-temporal state-space model to enhance rain streak removal in video sequences. Specifically, we design spatial and temporal state-space model layers to extract spatial features and incorporate temporal dependencies across frames, respectively. To improve multi-frame feature fusion, we derive a dynamic stacking filter, which adaptively approximates statistical filters for superior pixel-wise feature refinement. Moreover, we develop a median stacking loss to enable semi-supervised learning by generating pseudo-clean patches based on the sparsity prior of rain. To further explore the capacity of deraining models in supporting other vision-based tasks in rainy environments, we introduce a novel real-world benchmark focused on object detection and tracking in rainy conditions. Our method is extensively evaluated across multiple benchmarks containing numerous synthetic and real-world rainy videos, consistently demonstrating its superiority in quantitative metrics, visual quality, efficiency, and its utility for downstream tasks.
EnsIR: An Ensemble Algorithm for Image Restoration via Gaussian Mixture Models
Oct 30, 2024


Image restoration has experienced significant advancements due to the development of deep learning. Nevertheless, it encounters challenges related to ill-posed problems, resulting in deviations between single model predictions and ground-truths. Ensemble learning, as a powerful machine learning technique, aims to address these deviations by combining the predictions of multiple base models. Most existing works adopt ensemble learning during the design of restoration models, while only limited research focuses on the inference-stage ensemble of pre-trained restoration models. Regression-based methods fail to enable efficient inference, leading researchers in academia and industry to prefer averaging as their choice for post-training ensemble. To address this, we reformulate the ensemble problem of image restoration into Gaussian mixture models (GMMs) and employ an expectation maximization (EM)-based algorithm to estimate ensemble weights for aggregating prediction candidates. We estimate the range-wise ensemble weights on a reference set and store them in a lookup table (LUT) for efficient ensemble inference on the test set. Our algorithm is model-agnostic and training-free, allowing seamless integration and enhancement of various pre-trained image restoration models. It consistently outperforms regression based methods and averaging ensemble approaches on 14 benchmarks across 3 image restoration tasks, including super-resolution, deblurring and deraining. The codes and all estimated weights have been released in Github.
A Hybrid Transformer-Mamba Network for Single Image Deraining
Aug 31, 2024



Existing deraining Transformers employ self-attention mechanisms with fixed-range windows or along channel dimensions, limiting the exploitation of non-local receptive fields. In response to this issue, we introduce a novel dual-branch hybrid Transformer-Mamba network, denoted as TransMamba, aimed at effectively capturing long-range rain-related dependencies. Based on the prior of distinct spectral-domain features of rain degradation and background, we design a spectral-banded Transformer blocks on the first branch. Self-attention is executed within the combination of the spectral-domain channel dimension to improve the ability of modeling long-range dependencies. To enhance frequency-specific information, we present a spectral enhanced feed-forward module that aggregates features in the spectral domain. In the second branch, Mamba layers are equipped with cascaded bidirectional state space model modules to additionally capture the modeling of both local and global information. At each stage of both the encoder and decoder, we perform channel-wise concatenation of dual-branch features and achieve feature fusion through channel reduction, enabling more effective integration of the multi-scale information from the Transformer and Mamba branches. To better reconstruct innate signal-level relations within clean images, we also develop a spectral coherence loss. Extensive experiments on diverse datasets and real-world images demonstrate the superiority of our method compared against the state-of-the-art approaches.
Restoring Images in Adverse Weather Conditions via Histogram Transformer
Jul 14, 2024Transformer-based image restoration methods in adverse weather have achieved significant progress. Most of them use self-attention along the channel dimension or within spatially fixed-range blocks to reduce computational load. However, such a compromise results in limitations in capturing long-range spatial features. Inspired by the observation that the weather-induced degradation factors mainly cause similar occlusion and brightness, in this work, we propose an efficient Histogram Transformer (Histoformer) for restoring images affected by adverse weather. It is powered by a mechanism dubbed histogram self-attention, which sorts and segments spatial features into intensity-based bins. Self-attention is then applied across bins or within each bin to selectively focus on spatial features of dynamic range and process similar degraded pixels of the long range together. To boost histogram self-attention, we present a dynamic-range convolution enabling conventional convolution to conduct operation over similar pixels rather than neighbor pixels. We also observe that the common pixel-wise losses neglect linear association and correlation between output and ground-truth. Thus, we propose to leverage the Pearson correlation coefficient as a loss function to enforce the recovered pixels following the identical order as ground-truth. Extensive experiments demonstrate the efficacy and superiority of our proposed method. We have released the codes in Github.
DI-Retinex: Digital-Imaging Retinex Theory for Low-Light Image Enhancement
Apr 04, 2024



Many existing methods for low-light image enhancement (LLIE) based on Retinex theory ignore important factors that affect the validity of this theory in digital imaging, such as noise, quantization error, non-linearity, and dynamic range overflow. In this paper, we propose a new expression called Digital-Imaging Retinex theory (DI-Retinex) through theoretical and experimental analysis of Retinex theory in digital imaging. Our new expression includes an offset term in the enhancement model, which allows for pixel-wise brightness contrast adjustment with a non-linear mapping function. In addition, to solve the lowlight enhancement problem in an unsupervised manner, we propose an image-adaptive masked reverse degradation loss in Gamma space. We also design a variance suppression loss for regulating the additional offset term. Extensive experiments show that our proposed method outperforms all existing unsupervised methods in terms of visual quality, model size, and speed. Our algorithm can also assist downstream face detectors in low-light, as it shows the most performance gain after the low-light enhancement compared to other methods.
Logit Standardization in Knowledge Distillation
Mar 03, 2024



Knowledge distillation involves transferring soft labels from a teacher to a student using a shared temperature-based softmax function. However, the assumption of a shared temperature between teacher and student implies a mandatory exact match between their logits in terms of logit range and variance. This side-effect limits the performance of student, considering the capacity discrepancy between them and the finding that the innate logit relations of teacher are sufficient for student to learn. To address this issue, we propose setting the temperature as the weighted standard deviation of logit and performing a plug-and-play Z-score pre-process of logit standardization before applying softmax and Kullback-Leibler divergence. Our pre-process enables student to focus on essential logit relations from teacher rather than requiring a magnitude match, and can improve the performance of existing logit-based distillation methods. We also show a typical case where the conventional setting of sharing temperature between teacher and student cannot reliably yield the authentic distillation evaluation; nonetheless, this challenge is successfully alleviated by our Z-score. We extensively evaluate our method for various student and teacher models on CIFAR-100 and ImageNet, showing its significant superiority. The vanilla knowledge distillation powered by our pre-process can achieve favorable performance against state-of-the-art methods, and other distillation variants can obtain considerable gain with the assistance of our pre-process.