 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiF-VLA: Hindsight, Insight and Foresight through Motion Representation for Vision-Language-Action Models
Dec 10, 2025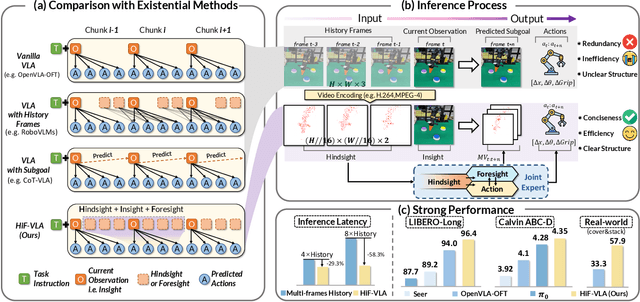
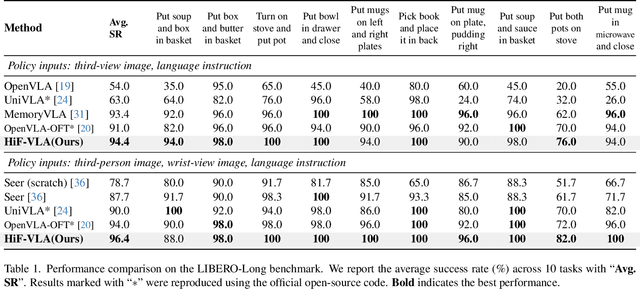
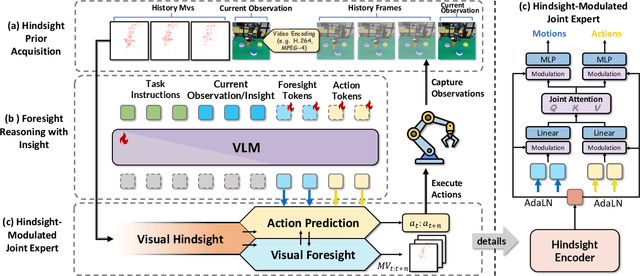
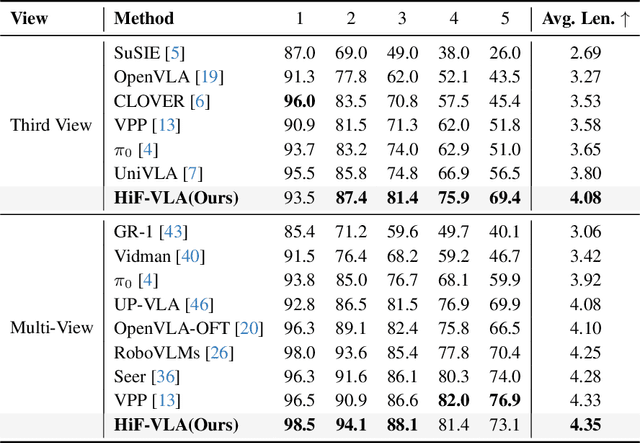
Vision-Language-Action (VLA) models have recently enabled robotic manipulation by grounding visual and linguistic cues into actions. However, most VLAs assume the Markov property, relying only on the current observation and thus suffering from temporal myopia that degrades long-horizon coherence. In this work, we view motion as a more compact and informative representation of temporal context and world dynamics, capturing inter-state changes while filtering static pixel-level noise. Building on this idea, we propose HiF-VLA (Hindsight, Insight, and Foresight for VLAs), a unified framework that leverages motion for bidirectional temporal reasoning. HiF-VLA encodes past dynamics through hindsight priors, anticipates future motion via foresight reasoning, and integrates both through a hindsight-modulated joint expert to enable a ''think-while-acting'' paradigm for long-horizon manipulation. As a result, HiF-VLA surpasses strong baselines on LIBERO-Long and CALVIN ABC-D benchmarks, while incurring negligible additional inference latency. Furthermore, HiF-VLA achieves substantial improvements in real-world long-horizon manipulation tasks, demonstrating its broad effectiveness in practical robotic settings.
DMPT: Decoupled Modality-aware Prompt Tuning for Multi-modal Object Re-identification
Apr 15, 2025Current multi-modal object re-identification approaches based on large-scale pre-trained backbones (i.e., ViT) have displayed remarkable progress and achieved excellent performance. However, these methods usually adopt the standard full fine-tuning paradigm, which requires the optimization of considerable backbone parameters, causing extensive computational and storage requirements. In this work, we propose an efficient prompt-tuning framework tailored for multi-modal object re-identification, dubbed DMPT, which freezes the main backbone and only optimizes several newly added decoupled modality-aware parameters. Specifically, we explicitly decouple the visual prompts into modality-specific prompts which leverage prior modality knowledge from a powerful text encoder and modality-independent semantic prompts which extract semantic information from multi-modal inputs, such as visible, near-infrared, and thermal-infrared. Built upon the extracted features, we further design a Prompt Inverse Bind (PromptIBind) strategy that employs bind prompts as a medium to connect the semantic prompt tokens of different modalities and facilitates the exchange of complementary multi-modal information, boosting final re-identification results. Experimental results on multiple common benchmarks demonstrate that our DMPT can achieve competitive results to existing state-of-the-art methods while requiring only 6.5% fine-tuning of the backbone parameters.
Exploring the Evolution of Physics Cognition in Video Generation: A Survey
Mar 27, 2025Recent advancements in video generation have witnessed significant progress, especially with the rapid advancement of diffusion models. Despite this, their deficiencies in physical cognition have gradually received widespread attention - generated content often violates the fundamental laws of physics, falling into the dilemma of ''visual realism but physical absurdity". Researchers began to increasingly recognize the importance of physical fidelity in video generation and attempted to integrate heuristic physical cognition such as motion representations and physical knowledge into generative systems to simulate real-world dynamic scenarios. Considering the lack of a systematic overview in this field, this survey aims to provide a comprehensive summary of architecture designs and their applications to fill this gap. Specifically, we discuss and organize the evolutionary process of physical cognition in video generation from a cognitive science perspective, while proposing a three-tier taxonomy: 1) basic schema perception for generation, 2) passive cognition of physical knowledge for generation, and 3) active cognition for world simulation, encompassing state-of-the-art methods, classical paradigms, and benchmarks. Subsequently, we emphasize the inherent key challenges in this domain and delineate potential pathways for future research, contributing to advancing the frontiers of discussion in both academia and industry. Through structured review and interdisciplinary analysis, this survey aims to provide directional guidance for developing interpretable, controllable, and physically consistent video generation paradigms, thereby propelling generative models from the stage of ''visual mimicry'' towards a new phase of ''human-like physical comprehension''.