 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeleton-based Action Recognition Using LSTM and CNN
Paper and Code
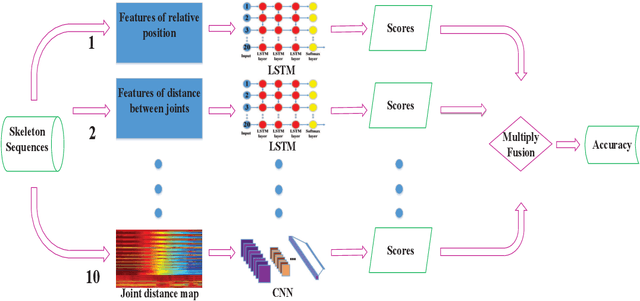
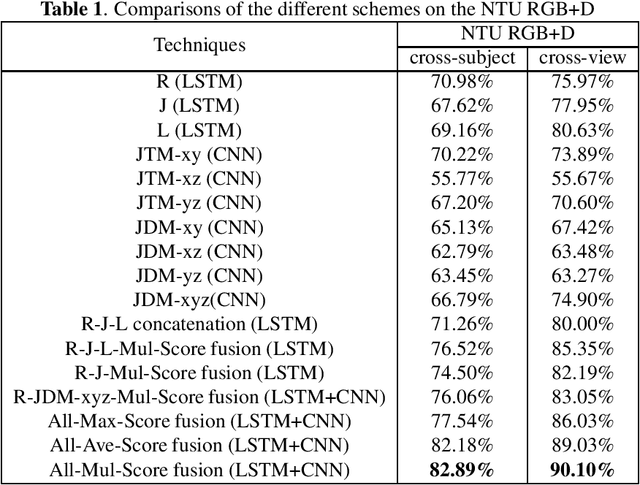
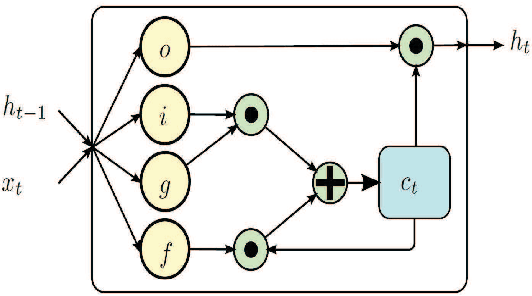
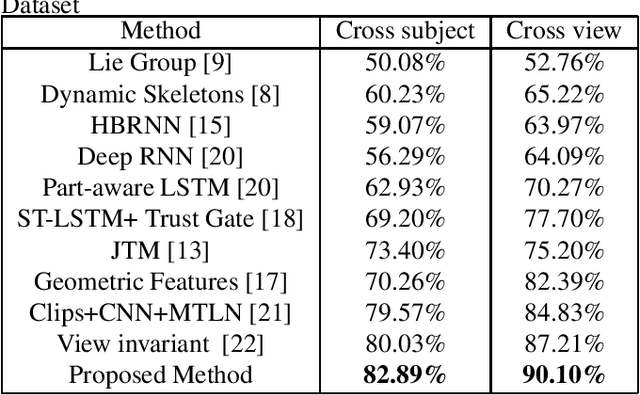
Recent methods based on 3D skeleton data have achieved outstanding performance due to its conciseness, robustness, and view-independent representation. With the development of deep learning, Convolutional Neural Networks (CNN) and Long Short Term Memory (LSTM)-based learning methods have achieved promising performance for action recognition. However, for CNN-based methods, it is inevitable to loss temporal information when a sequence is encoded into images. In order to capture as much spatial-temporal information as possible, LSTM and CNN are adopted to conduct effective recognition with later score fusion. In addition, experimental results show that the score fusion between CNN and LSTM performs better than that between LSTM and LSTM for the same feature. Our method achieved state-of-the-art results on NTU RGB+D datasets for 3D human action analysis. The proposed method achieved 87.40% in terms of accuracy and ranked $1^{st}$ place in Large Scale 3D Human Activity Analysis Challenge in Depth Videos.