 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Independently Recurrent Neural Network (IndRNN)
Oct 21, 2019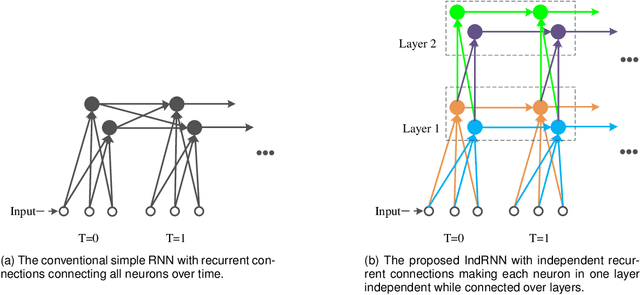

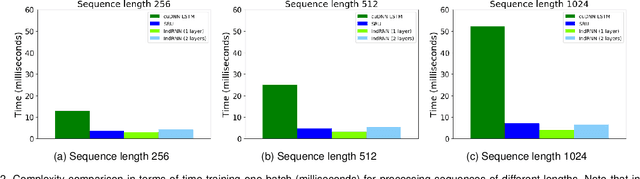
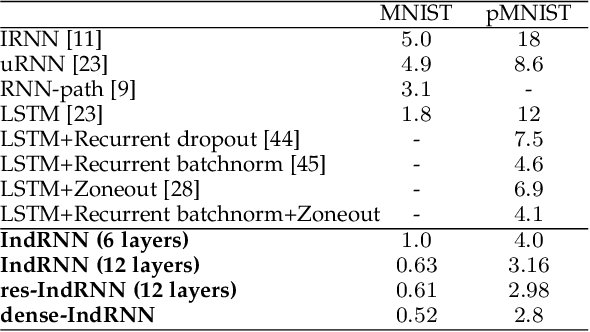
Recurrent neural networks (RNNs) are known to be difficult to train due to the gradient vanishing and exploding problems and thus difficult to learn long-term patterns. Long short-term memory (LSTM) was developed to address these problems, but the use of hyperbolic tangent and the sigmoid activation functions results in gradient decay over layers. Consequently, construction of an efficiently trainable deep RNN is challenging. Moreover, training of LSTM is very compute-intensive as the recurrent connection using matrix product is conducted at every time step. To address these problems, this paper proposes a new type of RNNs with the recurrent connection formulated as Hadamard product, referred to as independently recurrent neural network (IndRNN), where neurons in the same layer are independent of each other and connected across layers. The gradient vanishing and exploding problems are solved in IndRNN by simply regulating the recurrent weights, and thus long-term dependencies can be learned. Moreover, an IndRNN can work with non-saturated activation functions such as ReLU and be still trained robustly. Different deeper IndRNN architectures, including the basic stacked IndRNN, residual IndRNN and densely connected IndRNN, have been investigated, all of which can be much deeper than the existing RNNs. Furthermore, IndRNN reduces the computation at each time step and can be over 10 times faster than the LSTM. The code is made publicly available at https://github.com/Sunnydreamrain/IndRNN_pytorch. Experimental results have shown that the proposed IndRNN is able to process very long sequences (over 5000 time steps), can be used to construct very deep networks (the 21 layers residual IndRNN and deep densely connected IndRNN used in the experiment for example). Better performances have been achieved on various tasks with IndRNNs compared with the traditional RNN and LSTM.
Independently Recurrent Neural Network (IndRNN): Building A Longer and Deeper RNN
May 22, 2018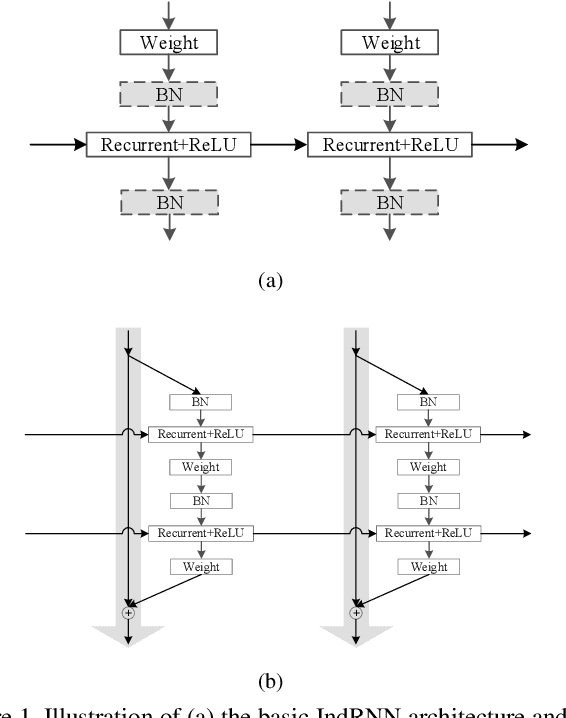
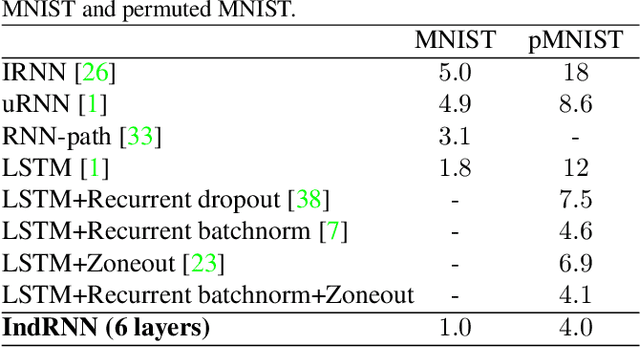
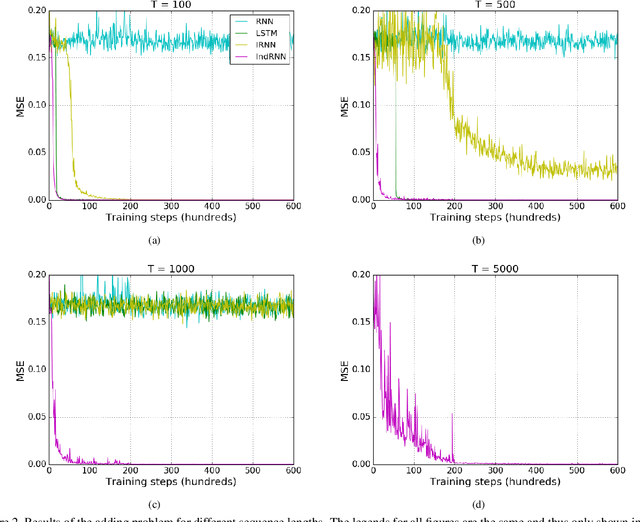
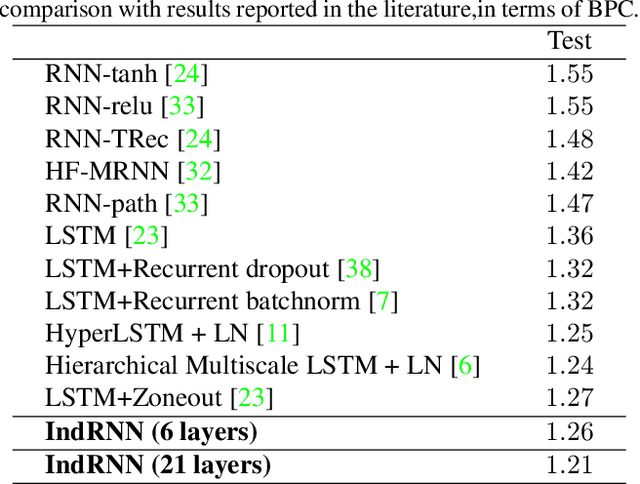
Recurrent neural networks (RNNs) have been widely used for processing sequential data. However, RNNs are commonly difficult to train due to the well-known gradient vanishing and exploding problems and hard to learn long-term patterns. Long short-term memory (LSTM) and gated recurrent unit (GRU) were developed to address these problems, but the use of hyperbolic tangent and the sigmoid action functions results in gradient decay over layers. Consequently, construction of an efficiently trainable deep network is challenging. In addition, all the neurons in an RNN layer are entangled together and their behaviour is hard to interpret. To address these problems, a new type of RNN, referred to as independently recurrent neural network (IndRNN), is proposed in this paper, where neurons in the same layer are independent of each other and they are connected across layers. We have shown that an IndRNN can be easily regulated to prevent the gradient exploding and vanishing problems while allowing the network to learn long-term dependencies. Moreover, an IndRNN can work with non-saturated activation functions such as relu (rectified linear unit) and be still trained robustly. Multiple IndRNNs can be stacked to construct a network that is deeper than the existing RNNs. Experimental results have shown that the proposed IndRNN is able to process very long sequences (over 5000 time steps), can be used to construct very deep networks (21 layers used in the experiment) and still be trained robustly. Better performances have been achieved on various tasks by using IndRNNs compared with the traditional RNN and LSTM. The code is available at https://github.com/Sunnydreamrain/IndRNN_Theano_Lasagne.
A Fusion Framework for Camouflaged Moving Foreground Detection in the Wavelet Domain
Apr 16, 2018


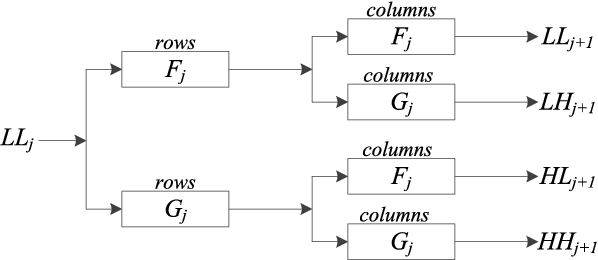
Detecting camouflaged moving foreground objects has been known to be difficult due to the similarity between the foreground objects and the background. Conventional methods cannot distinguish the foreground from background due to the small differences between them and thus suffer from under-detection of the camouflaged foreground objects. In this paper, we present a fusion framework to address this problem in the wavelet domain. We first show that the small differences in the image domain can be highlighted in certain wavelet bands. Then the likelihood of each wavelet coefficient being foreground is estimated by formulating foreground and background models for each wavelet band. The proposed framework effectively aggregates the likelihoods from different wavelet bands based on the characteristics of the wavelet transform. Experimental results demonstrated that the proposed method significantly outperformed existing methods in detecting camouflaged foreground objects. Specifically, the average F-measure for the proposed algorithm was 0.87, compared to 0.71 to 0.8 for the other state-of-the-art methods.
Foreground Detection in Camouflaged Scenes
Jul 11, 2017
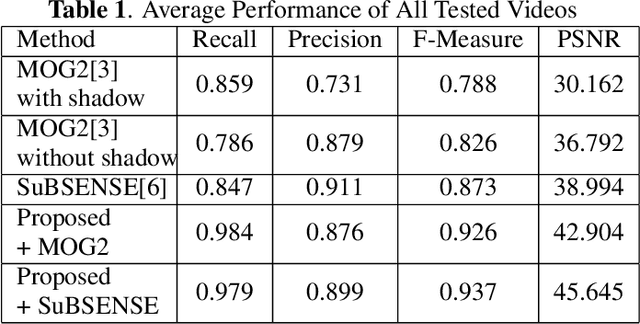

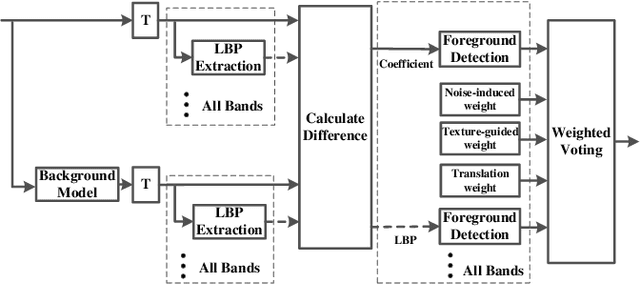
Foreground detection has been widely studied for decades due to its importance in many practical applications. Most of the existing methods assume foreground and background show visually distinct characteristics and thus the foreground can be detected once a good background model is obtained. However, there are many situations where this is not the case. Of particular interest in video surveillance is the camouflage case. For example, an active attacker camouflages by intentionally wearing clothes that are visually similar to the background. In such cases, even given a decent background model, it is not trivial to detect foreground objects. This paper proposes a texture guided weighted voting (TGWV) method which can efficiently detect foreground objects in camouflaged scenes. The proposed method employs the stationary wavelet transform to decompose the image into frequency bands. We show that the small and hardly noticeable differences between foreground and background in the image domain can be effectively captured in certain wavelet frequency bands. To make the final foreground decision, a weighted voting scheme is developed based on intensity and texture of all the wavelet bands with weights carefully designed. Experimental results demonstrate that the proposed method achieves superior performance compared to the current state-of-the-art results.
A Fully Trainable Network with RNN-based Pooling
Jun 16, 2017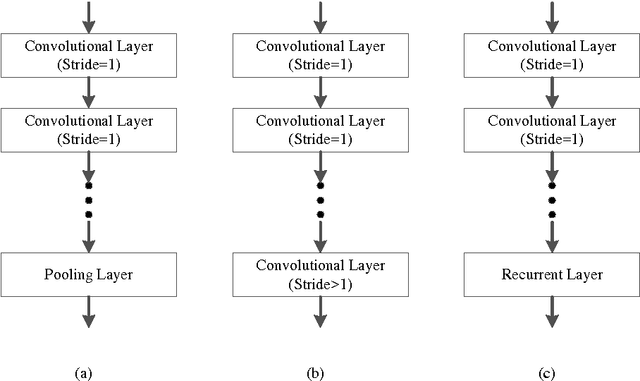
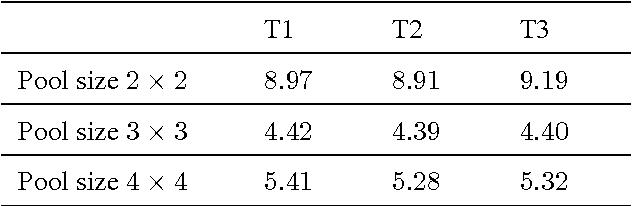
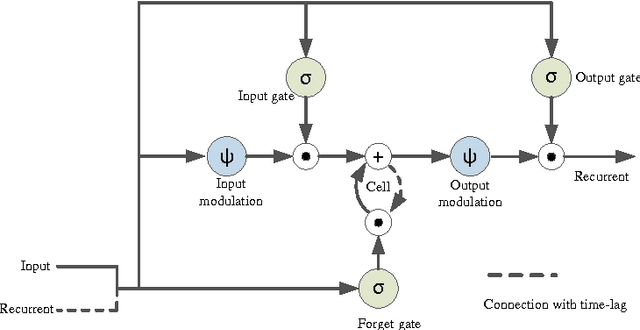
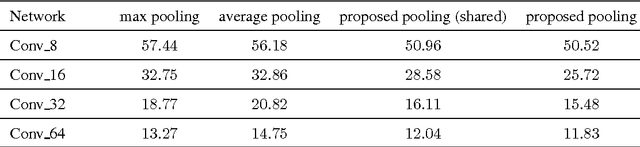
Pooling is an important component in convolutional neural networks (CNNs) for aggregating features and reducing computational burden. Compared with other components such as convolutional layers and fully connected layers which are completely learned from data, the pooling component is still handcrafted such as max pooling and average pooling. This paper proposes a learnable pooling function using recurrent neural networks (RNN) so that the pooling can be fully adapted to data and other components of the network, leading to an improved performance. Such a network with learnable pooling function is referred to as a fully trainable network (FTN). Experimental results have demonstrated that the proposed RNN-based pooling can well approximate the existing pooling functions and improve the performance of the network. Especially for small networks, the proposed FTN can improve the performance by seven percentage points in terms of error rate on the CIFAR-10 dataset compared with the traditional CNN.