 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-Marathon: Can Agents Autonomously Complete Ultra-Long-Horizon Software Work?
Jun 05, 2026AI agents are increasingly expected to complete long-horizon workflows that require sustained progress over hours, millions of tokens, and complex environments. Yet current agent benchmarks largely evaluate short-form tasks, such as single pull requests, small tickets, or 5-10 minute exercises, limiting our ability to measure agents' capabilities in planning, long-context understanding, and memory use. We introduce SWE-Marathon, a benchmark of 20 long-horizon tasks spanning software engineering and adjacent technical domains. Each task consists of a unique executable environment, a human-written reference solution, and a multi-layer verification suite. Logged agent attempts average 27.2M total tokens, making SWE-Marathon substantially longer-horizon than existing SWE and command-line agent benchmarks. Current frontier coding agents solve fewer than 30% of tasks. Failures often arise from poor self-verification, self-reported infeasibility, and premature termination. We also observe reward-hacking behavior in 13.8% of rollouts, where agents attempt to exploit the environment or verifier to bypass the intended workflow. SWE-Marathon includes adversarial review of test suites and execution environments, as well as multi-layer checks designed to prevent shortcut solutions. We release SWE-Marathon, evaluation code, and agent trajectories at https://swe-marathon.org/.
Beyond ReinMax: Low-Variance Gradient Estimators for Discrete Latent Variables
Mar 09, 2026Machine learning models involving discrete latent variables require gradient estimators to facilitate backpropagation in a computationally efficient manner. The most recent addition to the Straight-Through family of estimators, ReinMax, can be viewed from a numerical ODE perspective as incorporating an approximation via Heun's method to reduce bias, but at the cost of high variance. In this work, we introduce the ReinMax-Rao and ReinMax-CV estimators which incorporate Rao-Blackwellisation and control variate techniques into ReinMax to reduce its variance. Our estimators demonstrate superior performance on training variational autoencoders with discrete latent spaces. Furthermore, we investigate the possibility of leveraging alternative numerical methods for constructing more accurate gradient approximations and present an alternative view of ReinMax from a simpler numerical integration perspective.
A Microservice-Based Platform for Sustainable and Intelligent SLO Fulfilment and Service Management
Feb 13, 2026The Microservices Architecture (MSA) design pattern has become a staple for modern applications, allowing functionalities to be divided across fine-grained microservices, fostering reusability, distribution, and interoperability. As MSA-based applications are deployed to the Computing Continuum (CC), meeting their Service Level Objectives (SLOs) becomes a challenge. Trading off performance and sustainability SLOs is especially challenging. This challenge can be addressed with intelligent decision systems, able to reconfigure the services during runtime to meet the SLOs. However, developing these agents while adhering to the MSA pattern is complex, especially because CC providers, who have key know-how and information to fulfill these SLOs, must comply with the privacy requirements of application developers. This work presents the Carbon-Aware SLO and Control plAtform (CASCA), an open-source MSA-based platform that allows CC providers to reconfigure services and fulfill their SLOs while maintaining the privacy of developers. CASCA is architected to be highly reusable, distributable, and easy to use, extend, and modify. CASCA has been evaluated in a real CC testbed for a media streaming service, where decision systems implemented in Bash, Rust, and Python successfully reconfigured the service, unaffected by upholding privacy.
ODE-GS: Latent ODEs for Dynamic Scene Extrapolation with 3D Gaussian Splatting
Jun 05, 2025We present ODE-GS, a novel method that unifies 3D Gaussian Splatting with latent neural ordinary differential equations (ODEs) to forecast dynamic 3D scenes far beyond the time span seen during training. Existing neural rendering systems - whether NeRF- or 3DGS-based - embed time directly in a deformation network and therefore excel at interpolation but collapse when asked to predict the future, where timestamps are strictly out-of-distribution. ODE-GS eliminates this dependency: after learning a high-fidelity, time-conditioned deformation model for the training window, we freeze it and train a Transformer encoder that summarizes past Gaussian trajectories into a latent state whose continuous evolution is governed by a neural ODE. Numerical integration of this latent flow yields smooth, physically plausible Gaussian trajectories that can be queried at any future instant and rendered in real time. Coupled with a variational objective and a lightweight second-derivative regularizer, ODE-GS attains state-of-the-art extrapolation on D-NeRF and NVFI benchmarks, improving PSNR by up to 10 dB and halving perceptual error (LPIPS) relative to the strongest baselines. Our results demonstrate that continuous-time latent dynamics are a powerful, practical route to photorealistic prediction of complex 3D scenes.
Efficient Interactive 3D Multi-Object Removal
Jan 30, 2025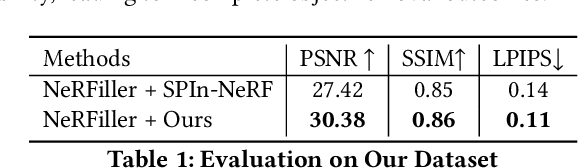
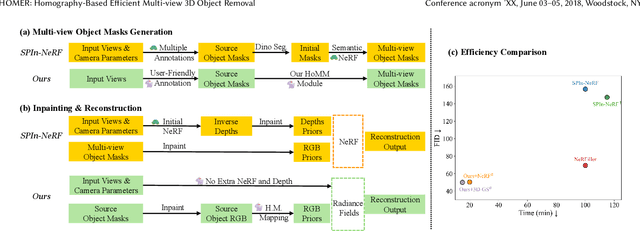
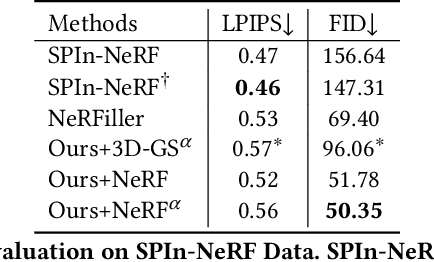
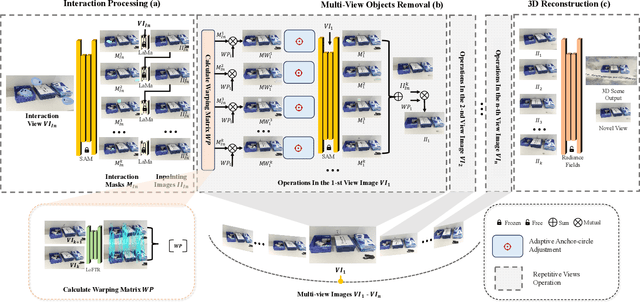
Object removal is of great significance to 3D scene understanding, essential for applications in content filtering and scene editing. Current mainstream methods primarily focus on removing individual objects, with a few methods dedicated to eliminating an entire area or all objects of a certain category. They however confront the challenge of insufficient granularity and flexibility for real-world applications, where users demand tailored excision and preservation of objects within defined zones. In addition, most of the current methods require kinds of priors when addressing multi-view inpainting, which is time-consuming. To address these limitations, we propose an efficient and user-friendly pipeline for 3D multi-object removal, enabling users to flexibly select areas and define objects for removal or preservation. Concretely, to ensure object consistency and correspondence across multiple views, we propose a novel mask matching and refinement module, which integrates homography-based warping with high-confidence anchor points for segmentation. By leveraging the IoU joint shape context distance loss, we enhance the accuracy of warped masks and improve subsequent inpainting processes. Considering the current immaturity of 3D multi-object removal, we provide a new evaluation dataset to bridge the developmental void. Experimental results demonstrate that our method significantly reduces computational costs, achieving processing speeds more than 80% faster than state-of-the-art methods while maintaining equivalent or higher reconstruction quality.
PriorDiffusion: Leverage Language Prior in Diffusion Models for Monocular Depth Estimation
Nov 24, 2024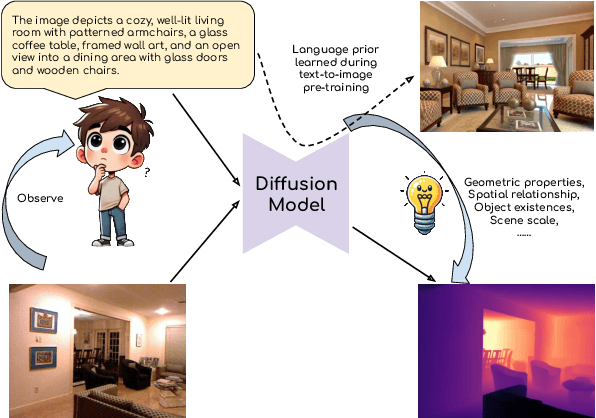
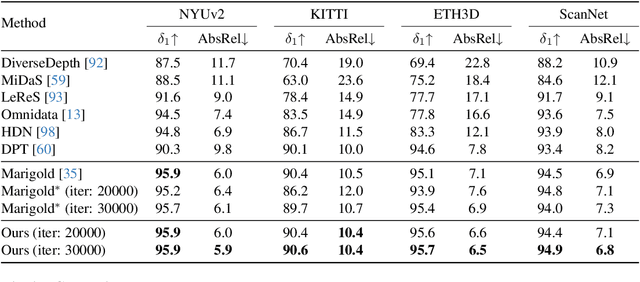
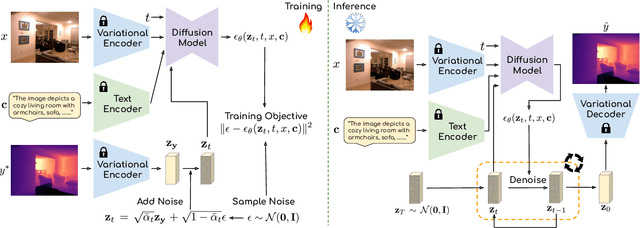
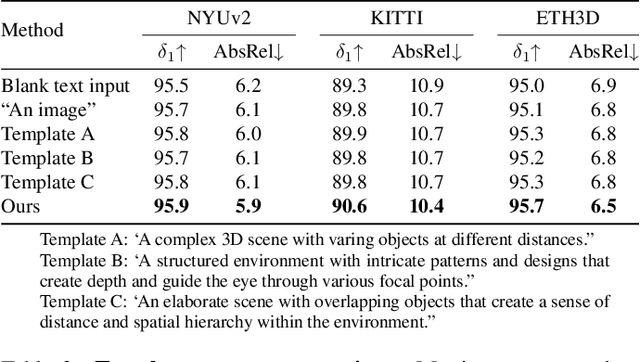
This paper explores the potential of leveraging language priors learned by text-to-image diffusion models to address ambiguity and visual nuisance in monocular depth estimation. Particularly, traditional monocular depth estimation suffers from inherent ambiguity due to the absence of stereo or multi-view depth cues, and nuisance due to lack of robustness of vision. We argue that language prior in diffusion models can enhance monocular depth estimation by leveraging the geometric prior aligned with the language description, which is learned during text-to-image pre-training. To generate images that reflect the text properly, the model must comprehend the size and shape of specified objects, their spatial relationship, and the scale of the scene. Thus, we propose PriorDiffusion, using a pre-trained text-to-image diffusion model that takes both image and text description that aligned with the scene to infer affine-invariant depth through a denoising process. We also show that language priors can guide the model's attention to specific regions and help it perceive the 3D scene in alignment with user intent. Simultaneously, it acts as a constraint to accelerate the convergence of the diffusion trajectory, since learning 3D properties from a condensed, low-dimensional language feature is more efficient compared with learning from a redundant, high-dimensional image feature. By training on HyperSim and Virtual KITTI, we achieve state-of-the-art zero-shot performance and a faster convergence speed, compared with other diffusion-based depth estimators, across NYUv2, KITTI, ETH3D, and ScanNet.
Comparing Fairness of Generative Mobility Models
Nov 07, 2024This work examines the fairness of generative mobility models, addressing the often overlooked dimension of equity in model performance across geographic regions. Predictive models built on crowd flow data are instrumental in understanding urban structures and movement patterns; however, they risk embedding biases, particularly in spatiotemporal contexts where model performance may reflect and reinforce existing inequities tied to geographic distribution. We propose a novel framework for assessing fairness by measuring the utility and equity of generated traces. Utility is assessed via the Common Part of Commuters (CPC), a similarity metric comparing generated and real mobility flows, while fairness is evaluated using demographic parity. By reformulating demographic parity to reflect the difference in CPC distribution between two groups, our analysis reveals disparities in how various models encode biases present in the underlying data. We utilized four models (Gravity, Radiation, Deep Gravity, and Non-linear Gravity) and our results indicate that traditional gravity and radiation models produce fairer outcomes, although Deep Gravity achieves higher CPC. This disparity underscores a trade-off between model accuracy and equity, with the feature-rich Deep Gravity model amplifying pre-existing biases in community representations. Our findings emphasize the importance of integrating fairness metrics in mobility modeling to avoid perpetuating inequities.
RSA: Resolving Scale Ambiguities in Monocular Depth Estimators through Language Descriptions
Oct 03, 2024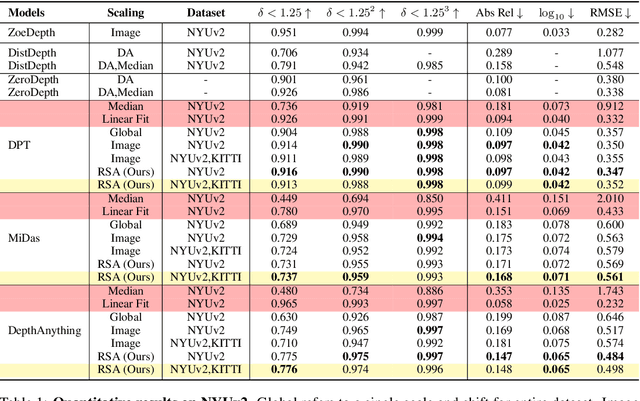
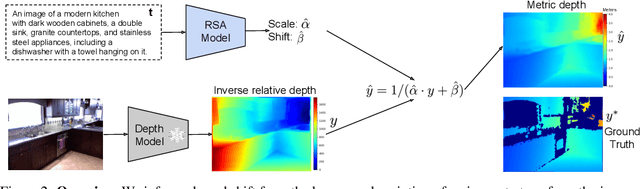
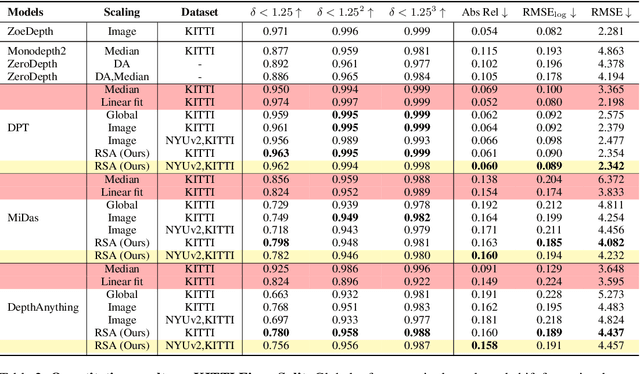

We propose a method for metric-scale monocular depth estimation. Inferring depth from a single image is an ill-posed problem due to the loss of scale from perspective projection during the image formation process. Any scale chosen is a bias, typically stemming from training on a dataset; hence, existing works have instead opted to use relative (normalized, inverse) depth. Our goal is to recover metric-scaled depth maps through a linear transformation. The crux of our method lies in the observation that certain objects (e.g., cars, trees, street signs) are typically found or associated with certain types of scenes (e.g., outdoor). We explore whether language descriptions can be used to transform relative depth predictions to those in metric scale. Our method, RSA, takes as input a text caption describing objects present in an image and outputs the parameters of a linear transformation which can be applied globally to a relative depth map to yield metric-scaled depth predictions. We demonstrate our method on recent general-purpose monocular depth models on indoors (NYUv2) and outdoors (KITTI). When trained on multiple datasets, RSA can serve as a general alignment module in zero-shot settings. Our method improves over common practices in aligning relative to metric depth and results in predictions that are comparable to an upper bound of fitting relative depth to ground truth via a linear transformation.
NeuroBind: Towards Unified Multimodal Representations for Neural Signals
Jul 19, 2024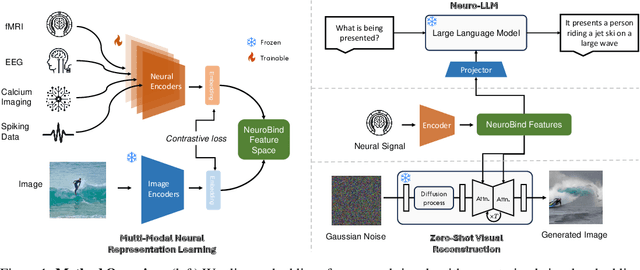
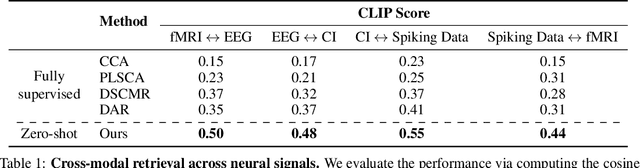

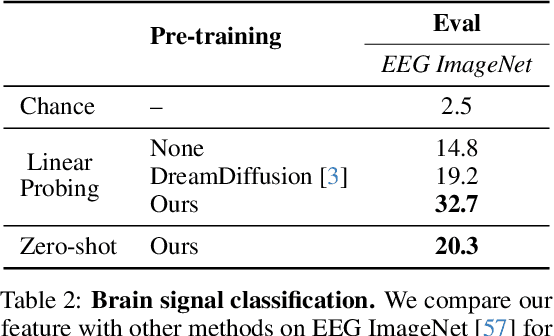
Understanding neural activity and information representation is crucial for advancing knowledge of brain function and cognition. Neural activity, measured through techniques like electrophysiology and neuroimaging, reflects various aspects of information processing. Recent advances in deep neural networks offer new approaches to analyzing these signals using pre-trained models. However, challenges arise due to discrepancies between different neural signal modalities and the limited scale of high-quality neural data. To address these challenges, we present NeuroBind, a general representation that unifies multiple brain signal types, including EEG, fMRI, calcium imaging, and spiking data. To achieve this, we align neural signals in these image-paired neural datasets to pre-trained vision-language embeddings. Neurobind is the first model that studies different neural modalities interconnectedly and is able to leverage high-resource modality models for various neuroscience tasks. We also showed that by combining information from different neural signal modalities, NeuroBind enhances downstream performance, demonstrating the effectiveness of the complementary strengths of different neural modalities. As a result, we can leverage multiple types of neural signals mapped to the same space to improve downstream tasks, and demonstrate the complementary strengths of different neural modalities. This approach holds significant potential for advancing neuroscience research, improving AI systems, and developing neuroprosthetics and brain-computer interfaces.
WorDepth: Variational Language Prior for Monocular Depth Estimation
Apr 05, 2024



Three-dimensional (3D) reconstruction from a single image is an ill-posed problem with inherent ambiguities, i.e. scale. Predicting a 3D scene from text description(s) is similarly ill-posed, i.e. spatial arrangements of objects described. We investigate the question of whether two inherently ambiguous modalities can be used in conjunction to produce metric-scaled reconstructions. To test this, we focus on monocular depth estimation, the problem of predicting a dense depth map from a single image, but with an additional text caption describing the scene. To this end, we begin by encoding the text caption as a mean and standard deviation; using a variational framework, we learn the distribution of the plausible metric reconstructions of 3D scenes corresponding to the text captions as a prior. To "select" a specific reconstruction or depth map, we encode the given image through a conditional sampler that samples from the latent space of the variational text encoder, which is then decoded to the output depth map. Our approach is trained alternatingly between the text and image branches: in one optimization step, we predict the mean and standard deviation from the text description and sample from a standard Gaussian, and in the other, we sample using a (image) conditional sampler. Once trained, we directly predict depth from the encoded text using the conditional sampler. We demonstrate our approach on indoor (NYUv2) and outdoor (KITTI) scenarios, where we show that language can consistently improve performance in both.