 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroBind: Towards Unified Multimodal Representations for Neural Signals
Jul 19, 2024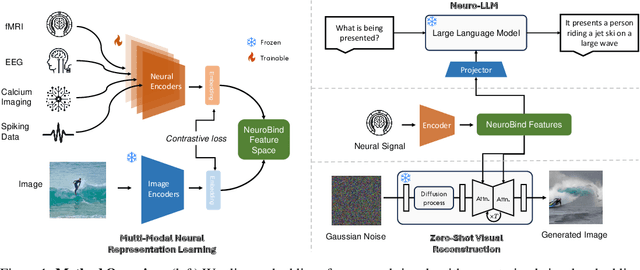
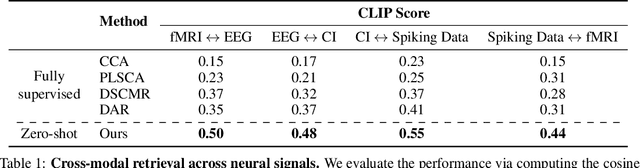

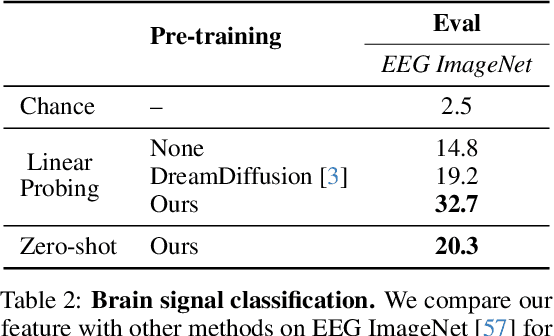
Understanding neural activity and information representation is crucial for advancing knowledge of brain function and cognition. Neural activity, measured through techniques like electrophysiology and neuroimaging, reflects various aspects of information processing. Recent advances in deep neural networks offer new approaches to analyzing these signals using pre-trained models. However, challenges arise due to discrepancies between different neural signal modalities and the limited scale of high-quality neural data. To address these challenges, we present NeuroBind, a general representation that unifies multiple brain signal types, including EEG, fMRI, calcium imaging, and spiking data. To achieve this, we align neural signals in these image-paired neural datasets to pre-trained vision-language embeddings. Neurobind is the first model that studies different neural modalities interconnectedly and is able to leverage high-resource modality models for various neuroscience tasks. We also showed that by combining information from different neural signal modalities, NeuroBind enhances downstream performance, demonstrating the effectiveness of the complementary strengths of different neural modalities. As a result, we can leverage multiple types of neural signals mapped to the same space to improve downstream tasks, and demonstrate the complementary strengths of different neural modalities. This approach holds significant potential for advancing neuroscience research, improving AI systems, and developing neuroprosthetics and brain-computer interfaces.
Incremental Learning and Self-Attention Mechanisms Improve Neural System Identification
Jun 12, 2024



Convolutional neural networks (CNNs) have been shown to be the state-of-the-art approach for modeling the transfer functions of visual cortical neurons. Cortical neurons in the primary visual cortex are are sensitive to contextual information mediated by extensive horizontal and feedback connections. Standard CNNs can integrate global spatial image information to model such contextual modulation via two mechanisms: successive rounds of convolutions and a fully connected readout layer. In this paper, we find that non-local networks or self-attention (SA) mechanisms, theoretically related to context-dependent flexible gating mechanisms observed in the primary visual cortex, improve neural response predictions over parameter-matched CNNs in two key metrics: tuning curve correlation and tuning peak. We factorize networks to determine the relative contribution of each context mechanism. This reveals that information in the local receptive field is most important for modeling the overall tuning curve, but surround information is critically necessary for characterizing the tuning peak. We find that self-attention can replace subsequent spatial-integration convolutions when learned in an incremental manner, and is further enhanced in the presence of a fully connected readout layer, suggesting that the two context mechanisms are complementary. Finally, we find that learning a receptive-field-centric model with self-attention, before incrementally learning a fully connected readout, yields a more biologically realistic model in terms of center-surround contributions.
Optimized Path Planning for USVs under Ocean Currents
Jul 07, 2023



The proposed work focuses on the path planning for Unmanned Surface Vehicles (USVs) in the ocean enviroment, taking into account various spatiotemporal factors such as ocean currents and other energy consumption factors. The paper proposes the use of Gaussian Process Motion Planning (GPMP2), a Bayesian optimization method that has shown promising results in continuous and nonlinear path planning algorithms. The proposed work improves GPMP2 by incorporating a new spatiotemporal factor for tracking and predicting ocean currents using a spatiotemporal Bayesian inference. The algorithm is applied to the USV path planning and is shown to optimize for smoothness, obstacle avoidance, and ocean currents in a challenging environment. The work is relevant for practical applications in ocean scenarios where an optimal path planning for USVs is essential for minimizing costs and optimizing performance.
A calcium imaging large dataset reveals novel functional organization in macaque V4
Jul 03, 2023The topological organization and feature preferences of primate visual area V4 have been primarily studied using artificial stimuli. Here, we combined large-scale calcium imaging with deep learning methods to characterize and understand how V4 processes natural images. By fitting a deep learning model to an unprecedentedly large dataset of columnar scale cortical responses to tens of thousands of natural stimuli and using the model to identify the images preferred by each cortical pixel, we obtained a detailed V4 topographical map of natural stimulus preference. The map contains distinct functional domains preferring a variety of natural image features, ranging from surface-related features such as color and texture to shape-related features such as edge, curvature, and facial features. These predicted domains were verified by additional widefield calcium imaging and single-cell resolution two-photon imaging. Our study reveals the systematic topological organization of V4 for encoding image features in natural scenes.
Distributed Localization without Direct Communication Inspired by Statistical Mechanics
Jun 04, 2020



Distributed localization is essential in many robotic collective tasks such as shape formation and self-assembly.Inspired by the statistical mechanics of energy transition, this paper presents a fully distributed localization algorithm named as virtual particle exchange (VPE) localization algorithm, where each robot repetitively exchanges virtual particles (VPs) with neighbors and eventually obtains its relative position from the virtual particle (VP) amount it owns. Using custom-designed hardware and protocol, VPE localization algorithm allows robots to achieve localization using sensor readings only, avoiding direct communication with neighbors and keeping anonymity. Moreover, VPE localization algorithm determines the swarm center automatically, thereby eliminating the requirement of fixed beacons to embody the origin of coordinates. Theoretical analysis proves that the VPE localization algorithm can always converge to the same result regardless of initial state and has low asymptotic time and memory complexity. Extensive localization simulations with up to 10000 robots and experiments with 52 lowcost robots are carried out, which verify that VPE localization algorithm is scalable, accurate and robust to sensor noises. Based on the VPE localization algorithm, shape formations are further achieved in both simulations and experiments with 52 robots, illustrating that the algorithm can be directly applied to support swarm collaborative tasks.