 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAMTRL: Teacher-Aligned Reward Reshaping for Multi-Turn Reinforcement Learning in Long-Context Compression
Mar 23, 2026The rapid progress of large language models (LLMs) has led to remarkable performance gains across a wide range of tasks. However, when handling long documents that exceed the model's context window limit, the entire context cannot be processed in a single pass, making chunk-wise processing necessary. This requires multiple turns to read different chunks and update memory. However, supervision is typically provided only by the final outcome, which makes it difficult to evaluate the quality of memory updates at each turn in the multi-turn training setting. This introduces a temporal credit assignment challenge. Existing approaches, such as LLM-as-a-judge or process reward models, incur substantial computational overhead and suffer from estimation noise. To better address the credit assignment problem in multi-turn memory training, we propose Teacher-Aligned Reward Reshaping for Multi-Turn Reinforcement Learning (TAMTRL). TAMTRL leverages relevant documents as teacher signals by aligning them with each turn of model input and assigns rewards through normalized probabilities in a self-supervised manner. This provides fine-grained learning signals for each memory update and improves long-context processing. Experiments with multiple models of varying scales across seven long-context benchmarks show that TAMTRL consistently outperforms strong baselines, demonstrating its effectiveness. Our code is available at https://anonymous.4open.science/r/TAMTRL-F1F8.
Identifying Cause-and-Effect Relationships of Manufacturing Errors using Sequence-to-Sequence Learning
May 05, 2022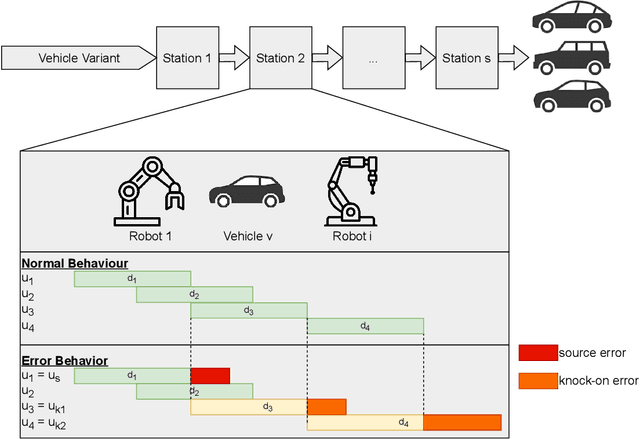
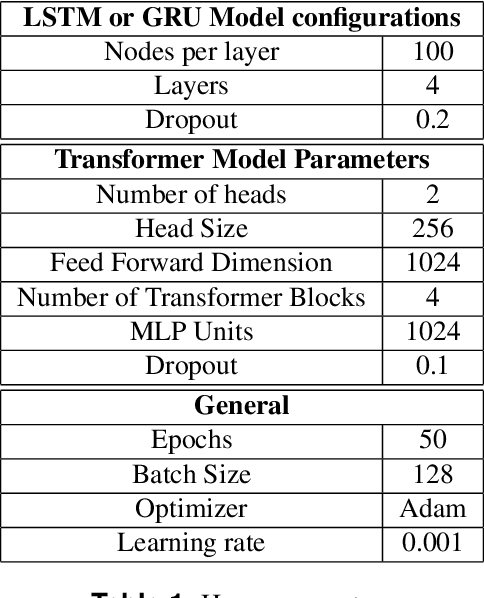
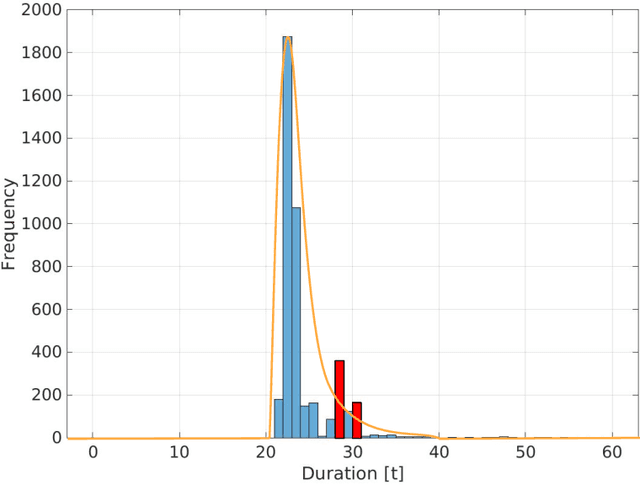
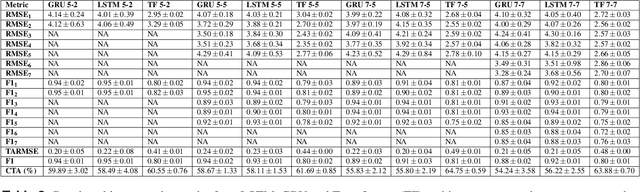
In car-body production the pre-formed sheet metal parts of the body are assembled on fully-automated production lines. The body passes through multiple stations in succession, and is processed according to the order requirements. The timely completion of orders depends on the individual station-based operations concluding within their scheduled cycle times. If an error occurs in one station, it can have a knock-on effect, resulting in delays on the downstream stations. To the best of our knowledge, there exist no methods for automatically distinguishing between source and knock-on errors in this setting, as well as establishing a causal relation between them. Utilizing real-time information about conditions collected by a production data acquisition system, we propose a novel vehicle manufacturing analysis system, which uses deep learning to establish a link between source and knock-on errors. We benchmark three sequence-to-sequence models, and introduce a novel composite time-weighted action metric for evaluating models in this context. We evaluate our framework on a real-world car production dataset recorded by Volkswagen Commercial Vehicles. Surprisingly we find that 71.68% of sequences contain either a source or knock-on error. With respect to seq2seq model training, we find that the Transformer demonstrates a better performance compared to LSTM and GRU in this domain, in particular when the prediction range with respect to the durations of future actions is increased.
Distributed Localization without Direct Communication Inspired by Statistical Mechanics
Jun 04, 2020



Distributed localization is essential in many robotic collective tasks such as shape formation and self-assembly.Inspired by the statistical mechanics of energy transition, this paper presents a fully distributed localization algorithm named as virtual particle exchange (VPE) localization algorithm, where each robot repetitively exchanges virtual particles (VPs) with neighbors and eventually obtains its relative position from the virtual particle (VP) amount it owns. Using custom-designed hardware and protocol, VPE localization algorithm allows robots to achieve localization using sensor readings only, avoiding direct communication with neighbors and keeping anonymity. Moreover, VPE localization algorithm determines the swarm center automatically, thereby eliminating the requirement of fixed beacons to embody the origin of coordinates. Theoretical analysis proves that the VPE localization algorithm can always converge to the same result regardless of initial state and has low asymptotic time and memory complexity. Extensive localization simulations with up to 10000 robots and experiments with 52 lowcost robots are carried out, which verify that VPE localization algorithm is scalable, accurate and robust to sensor noises. Based on the VPE localization algorithm, shape formations are further achieved in both simulations and experiments with 52 robots, illustrating that the algorithm can be directly applied to support swarm collaborative tasks.
GaDei: On Scale-up Training As A Service For Deep Learning
Oct 03, 2017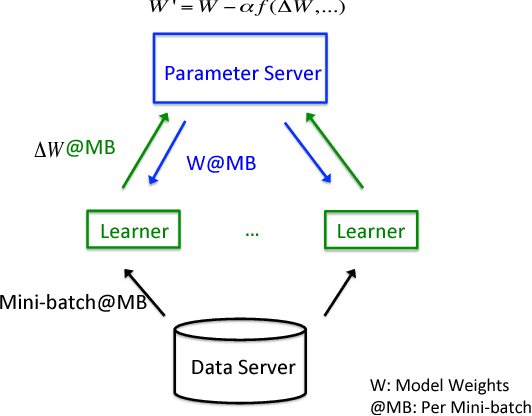
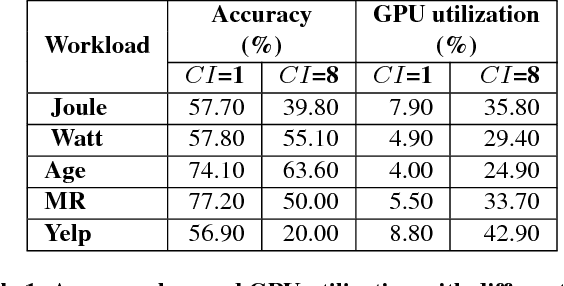
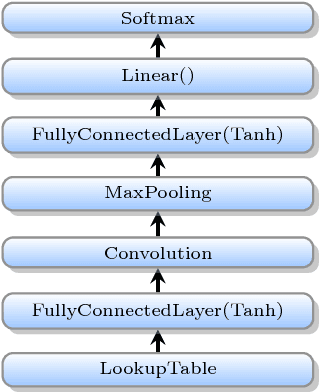
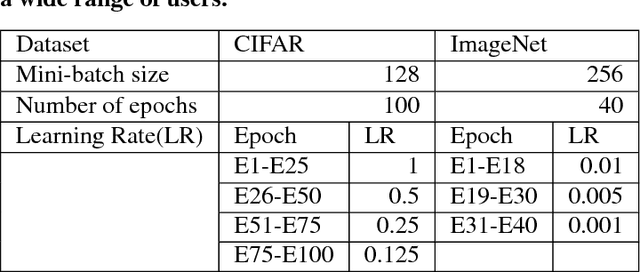
Deep learning (DL) training-as-a-service (TaaS) is an important emerging industrial workload. The unique challenge of TaaS is that it must satisfy a wide range of customers who have no experience and resources to tune DL hyper-parameters, and meticulous tuning for each user's dataset is prohibitively expensive. Therefore, TaaS hyper-parameters must be fixed with values that are applicable to all users. IBM Watson Natural Language Classifier (NLC) service, the most popular IBM cognitive service used by thousands of enterprise-level clients around the globe, is a typical TaaS service. By evaluating the NLC workloads, we show that only the conservative hyper-parameter setup (e.g., small mini-batch size and small learning rate) can guarantee acceptable model accuracy for a wide range of customers. We further justify theoretically why such a setup guarantees better model convergence in general. Unfortunately, the small mini-batch size causes a high volume of communication traffic in a parameter-server based system. We characterize the high communication bandwidth requirement of TaaS using representative industrial deep learning workloads and demonstrate that none of the state-of-the-art scale-up or scale-out solutions can satisfy such a requirement. We then present GaDei, an optimized shared-memory based scale-up parameter server design. We prove that the designed protocol is deadlock-free and it processes each gradient exactly once. Our implementation is evaluated on both commercial benchmarks and public benchmarks to demonstrate that it significantly outperforms the state-of-the-art parameter-server based implementation while maintaining the required accuracy and our implementation reaches near the best possible runtime performance, constrained only by the hardware limitation. Furthermore, to the best of our knowledge, GaDei is the only scale-up DL system that provides fault-tolerance.