 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMass Concept Erasure in Diffusion Models with Concept Hierarchy
Jan 06, 2026The success of diffusion models has raised concerns about the generation of unsafe or harmful content, prompting concept erasure approaches that fine-tune modules to suppress specific concepts while preserving general generative capabilities. However, as the number of erased concepts grows, these methods often become inefficient and ineffective, since each concept requires a separate set of fine-tuned parameters and may degrade the overall generation quality. In this work, we propose a supertype-subtype concept hierarchy that organizes erased concepts into a parent-child structure. Each erased concept is treated as a child node, and semantically related concepts (e.g., macaw, and bald eagle) are grouped under a shared parent node, referred to as a supertype concept (e.g., bird). Rather than erasing concepts individually, we introduce an effective and efficient group-wise suppression method, where semantically similar concepts are grouped and erased jointly by sharing a single set of learnable parameters. During the erasure phase, standard diffusion regularization is applied to preserve denoising process in unmasked regions. To mitigate the degradation of supertype generation caused by excessive erasure of semantically related subtypes, we propose a novel method called Supertype-Preserving Low-Rank Adaptation (SuPLoRA), which encodes the supertype concept information in the frozen down-projection matrix and updates only the up-projection matrix during erasure. Theoretical analysis demonstrates the effectiveness of SuPLoRA in mitigating generation performance degradation. We construct a more challenging benchmark that requires simultaneous erasure of concepts across diverse domains, including celebrities, objects, and pornographic content.
CE-SDWV: Effective and Efficient Concept Erasure for Text-to-Image Diffusion Models via a Semantic-Driven Word Vocabulary
Jan 26, 2025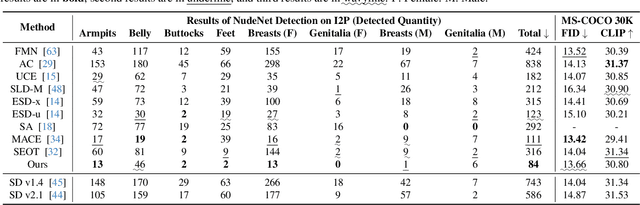
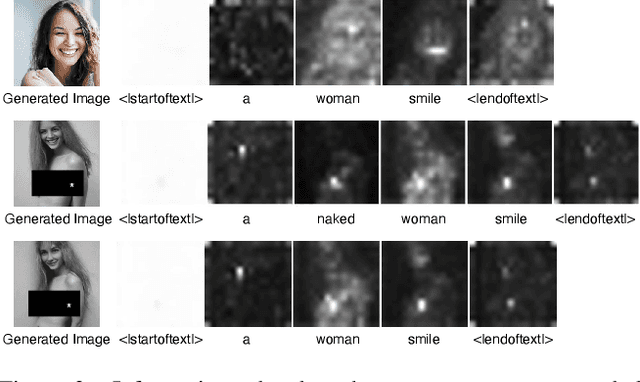
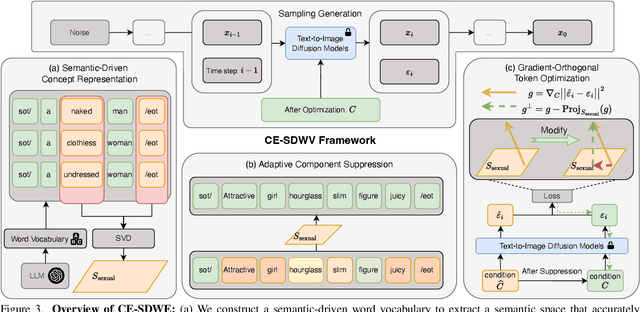
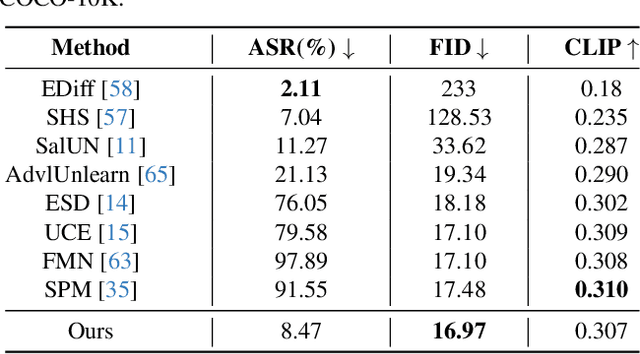
Large-scale text-to-image (T2I) diffusion models have achieved remarkable generative performance about various concepts. With the limitation of privacy and safety in practice, the generative capability concerning NSFW (Not Safe For Work) concepts is undesirable, e.g., producing sexually explicit photos, and licensed images. The concept erasure task for T2I diffusion models has attracted considerable attention and requires an effective and efficient method. To achieve this goal, we propose a CE-SDWV framework, which removes the target concepts (e.g., NSFW concepts) of T2I diffusion models in the text semantic space by only adjusting the text condition tokens and does not need to re-train the original T2I diffusion model's weights. Specifically, our framework first builds a target concept-related word vocabulary to enhance the representation of the target concepts within the text semantic space, and then utilizes an adaptive semantic component suppression strategy to ablate the target concept-related semantic information in the text condition tokens. To further adapt the above text condition tokens to the original image semantic space, we propose an end-to-end gradient-orthogonal token optimization strategy. Extensive experiments on I2P and UnlearnCanvas benchmarks demonstrate the effectiveness and efficiency of our method.
TextToucher: Fine-Grained Text-to-Touch Generation
Sep 09, 2024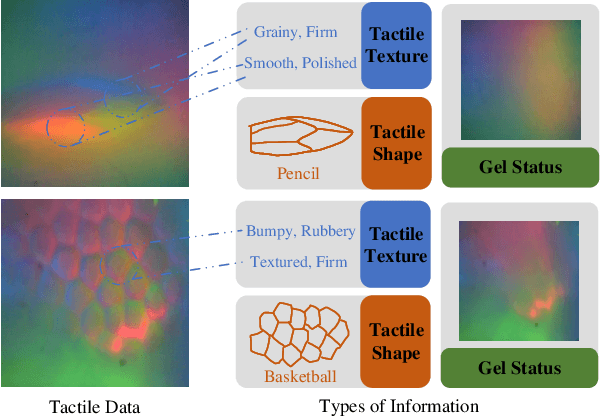

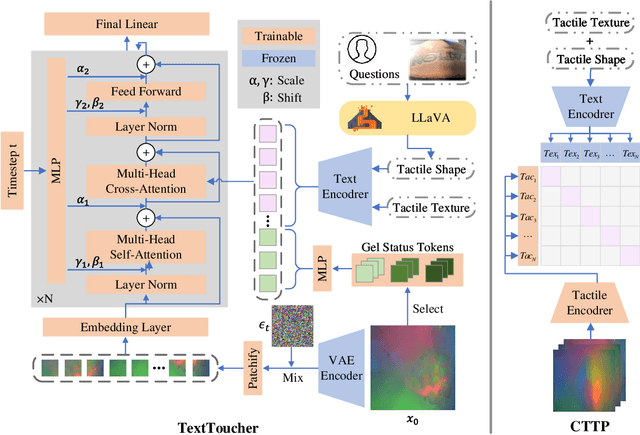
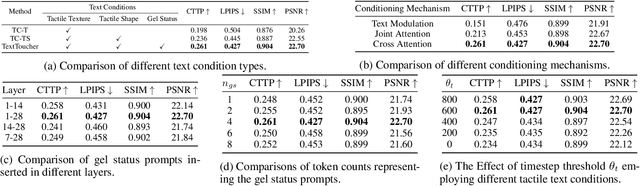
Tactile sensation plays a crucial role in the development of multi-modal large models and embodied intelligence. To collect tactile data with minimal cost as possible, a series of studies have attempted to generate tactile images by vision-to-touch image translation. However, compared to text modality, visual modality-driven tactile generation cannot accurately depict human tactile sensation. In this work, we analyze the characteristics of tactile images in detail from two granularities: object-level (tactile texture, tactile shape), and sensor-level (gel status). We model these granularities of information through text descriptions and propose a fine-grained Text-to-Touch generation method (TextToucher) to generate high-quality tactile samples. Specifically, we introduce a multimodal large language model to build the text sentences about object-level tactile information and employ a set of learnable text prompts to represent the sensor-level tactile information. To better guide the tactile generation process with the built text information, we fuse the dual grains of text information and explore various dual-grain text conditioning methods within the diffusion transformer architecture. Furthermore, we propose a Contrastive Text-Touch Pre-training (CTTP) metric to precisely evaluate the quality of text-driven generated tactile data. Extensive experiments demonstrate the superiority of our TextToucher method. The source codes will be available at \url{https://github.com/TtuHamg/TextToucher}.
DriveDiTFit: Fine-tuning Diffusion Transformers for Autonomous Driving
Jul 22, 2024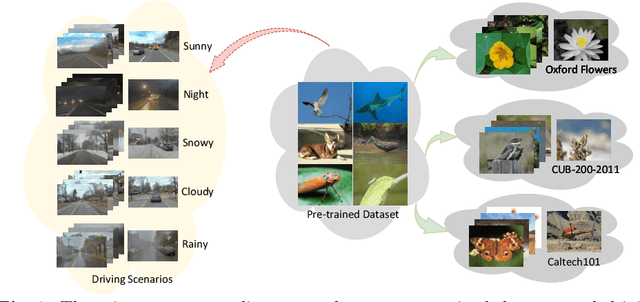

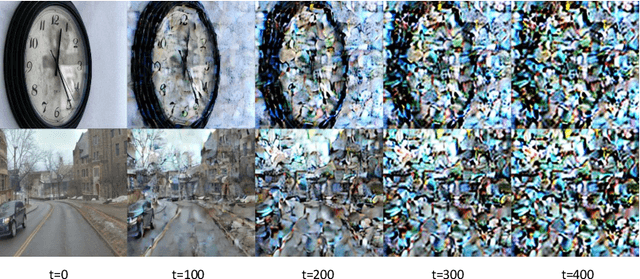

In autonomous driving, deep models have shown remarkable performance across various visual perception tasks with the demand of high-quality and huge-diversity training datasets. Such datasets are expected to cover various driving scenarios with adverse weather, lighting conditions and diverse moving objects. However, manually collecting these data presents huge challenges and expensive cost. With the rapid development of large generative models, we propose DriveDiTFit, a novel method for efficiently generating autonomous Driving data by Fine-tuning pre-trained Diffusion Transformers (DiTs). Specifically, DriveDiTFit utilizes a gap-driven modulation technique to carefully select and efficiently fine-tune a few parameters in DiTs according to the discrepancy between the pre-trained source data and the target driving data. Additionally, DriveDiTFit develops an effective weather and lighting condition embedding module to ensure diversity in the generated data, which is initialized by a nearest-semantic-similarity initialization approach. Through progressive tuning scheme to refined the process of detail generation in early diffusion process and enlarging the weights corresponding to small objects in training loss, DriveDiTFit ensures high-quality generation of small moving objects in the generated data. Extensive experiments conducted on driving datasets confirm that our method could efficiently produce diverse real driving data. The source codes will be available at https://github.com/TtuHamg/DriveDiTFit.