 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Sequence Modeling for Safe Reinforcement Learning
Feb 09, 2026Offline safe reinforcement learning (RL) aims to learn policies from a fixed dataset while maximizing performance under cumulative cost constraints. In practice, deployment requirements often vary across scenarios, necessitating a single policy that can adapt zero-shot to different cost thresholds. However, most existing offline safe RL methods are trained under a pre-specified threshold, yielding policies with limited generalization and deployment flexibility across cost thresholds. Motivated by recent progress in conditional sequence modeling (CSM), which enables flexible goal-conditioned control by specifying target returns, we propose RCDT, a CSM-based method that supports zero-shot deployment across multiple cost thresholds within a single trained policy. RCDT is the first CSM-based offline safe RL algorithm that integrates a Lagrangian-style cost penalty with an auto-adaptive penalty coefficient. To avoid overly conservative behavior and achieve a more favorable return--cost trade-off, a reward--cost-aware trajectory reweighting mechanism and Q-value regularization are further incorporated. Extensive experiments on the DSRL benchmark demonstrate that RCDT consistently improves return--cost trade-offs over representative baselines, advancing the state-of-the-art in offline safe RL.
CE-SDWV: Effective and Efficient Concept Erasure for Text-to-Image Diffusion Models via a Semantic-Driven Word Vocabulary
Jan 26, 2025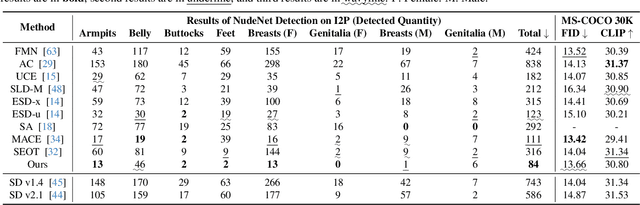
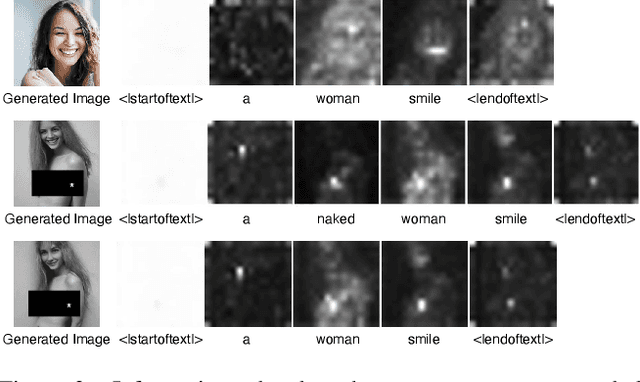
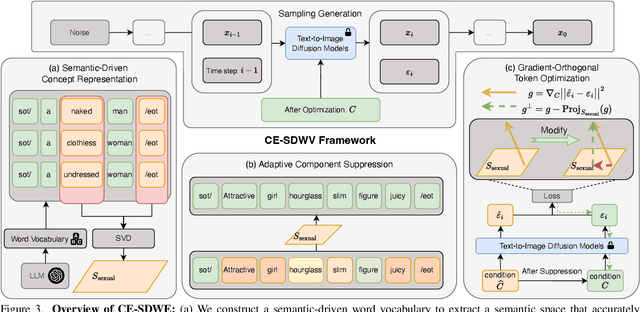
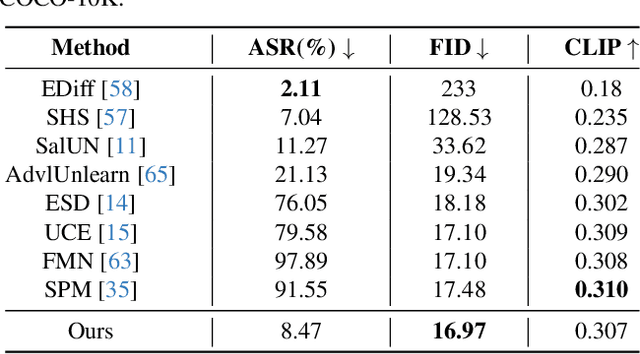
Large-scale text-to-image (T2I) diffusion models have achieved remarkable generative performance about various concepts. With the limitation of privacy and safety in practice, the generative capability concerning NSFW (Not Safe For Work) concepts is undesirable, e.g., producing sexually explicit photos, and licensed images. The concept erasure task for T2I diffusion models has attracted considerable attention and requires an effective and efficient method. To achieve this goal, we propose a CE-SDWV framework, which removes the target concepts (e.g., NSFW concepts) of T2I diffusion models in the text semantic space by only adjusting the text condition tokens and does not need to re-train the original T2I diffusion model's weights. Specifically, our framework first builds a target concept-related word vocabulary to enhance the representation of the target concepts within the text semantic space, and then utilizes an adaptive semantic component suppression strategy to ablate the target concept-related semantic information in the text condition tokens. To further adapt the above text condition tokens to the original image semantic space, we propose an end-to-end gradient-orthogonal token optimization strategy. Extensive experiments on I2P and UnlearnCanvas benchmarks demonstrate the effectiveness and efficiency of our method.
Open RL Benchmark: Comprehensive Tracked Experiments for Reinforcement Learning
Feb 05, 2024



In many Reinforcement Learning (RL) papers, learning curves are useful indicators to measure the effectiveness of RL algorithms. However, the complete raw data of the learning curves are rarely available. As a result, it is usually necessary to reproduce the experiments from scratch, which can be time-consuming and error-prone. We present Open RL Benchmark, a set of fully tracked RL experiments, including not only the usual data such as episodic return, but also all algorithm-specific and system metrics. Open RL Benchmark is community-driven: anyone can download, use, and contribute to the data. At the time of writing, more than 25,000 runs have been tracked, for a cumulative duration of more than 8 years. Open RL Benchmark covers a wide range of RL libraries and reference implementations. Special care is taken to ensure that each experiment is precisely reproducible by providing not only the full parameters, but also the versions of the dependencies used to generate it. In addition, Open RL Benchmark comes with a command-line interface (CLI) for easy fetching and generating figures to present the results. In this document, we include two case studies to demonstrate the usefulness of Open RL Benchmark in practice. To the best of our knowledge, Open RL Benchmark is the first RL benchmark of its kind, and the authors hope that it will improve and facilitate the work of researchers in the field.