 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Theory-of-Mind Performance in Large Language Models via Prompting
Apr 26, 2023



Large language models (LLMs) excel in many tasks in 2023, but they still face challenges in complex reasoning. Theory-of-mind (ToM) tasks, which require understanding agents' beliefs, goals, and mental states, are essential for common-sense reasoning involving humans, making it crucial to enhance LLM performance in this area. This study measures the ToM performance of GPT-4 and three GPT-3.5 variants (Davinci-2, Davinci-3, GPT-3.5-Turbo), and investigates the effectiveness of in-context learning in improving their ToM comprehension. We evaluated prompts featuring two-shot chain of thought reasoning and step-by-step thinking instructions. We found that LLMs trained with Reinforcement Learning from Human Feedback (RLHF) (all models excluding Davinci-2) improved their ToM accuracy via in-context learning. GPT-4 performed best in zero-shot settings, reaching nearly 80% ToM accuracy, but still fell short of the 87% human accuracy on the test set. However, when supplied with prompts for in-context learning, all RLHF-trained LLMs exceeded 80% ToM accuracy, with GPT-4 reaching 100%. These results demonstrate that appropriate prompting enhances LLM ToM reasoning, and they underscore the context-dependent nature of LLM cognitive capacities.
Slower is Better: Revisiting the Forgetting Mechanism in LSTM for Slower Information Decay
May 12, 2021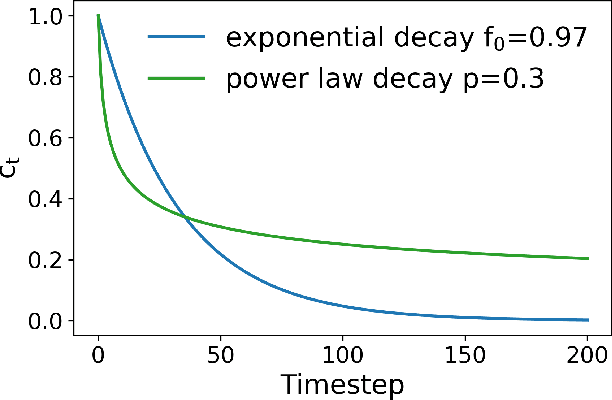
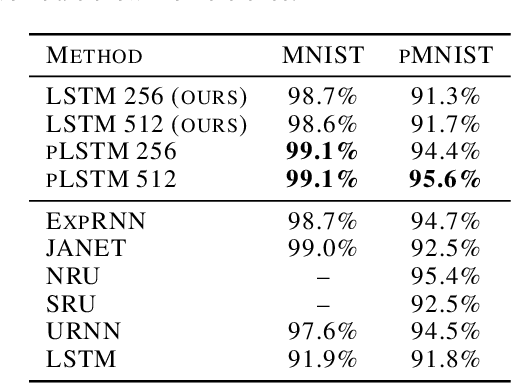
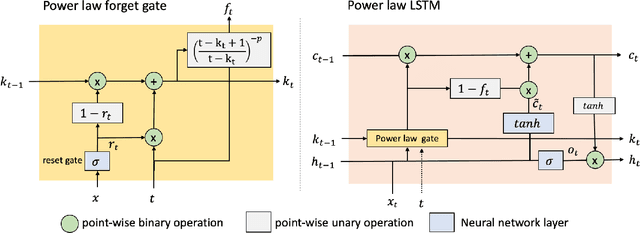
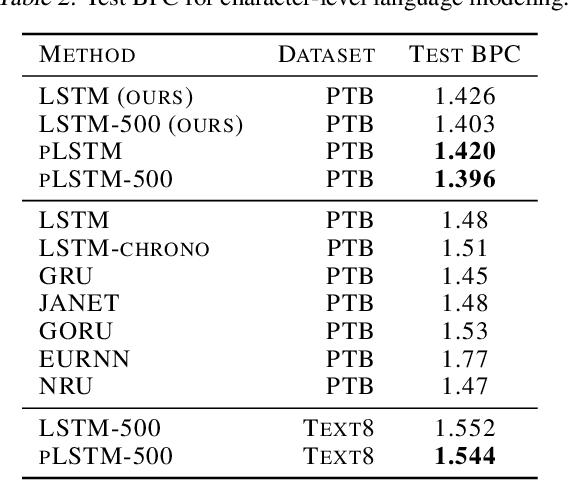
Sequential information contains short- to long-range dependencies; however, learning long-timescale information has been a challenge for recurrent neural networks. Despite improvements in long short-term memory networks (LSTMs), the forgetting mechanism results in the exponential decay of information, limiting their capacity to capture long-timescale information. Here, we propose a power law forget gate, which instead learns to forget information along a slower power law decay function. Specifically, the new gate learns to control the power law decay factor, p, allowing the network to adjust the information decay rate according to task demands. Our experiments show that an LSTM with power law forget gates (pLSTM) can effectively capture long-range dependencies beyond hundreds of elements on image classification, language modeling, and categorization tasks, improving performance over the vanilla LSTM. We also inspected the revised forget gate by varying the initialization of p, setting p to a fixed value, and ablating cells in the pLSTM network. The results show that the information decay can be controlled by the learnable decay factor p, which allows pLSTM to achieve its superior performance. Altogether, we found that LSTM with the proposed forget gate can learn long-term dependencies, outperforming other recurrent networks in multiple domains; such gating mechanism can be integrated into other architectures for improving the learning of long timescale information in recurrent neural networks.
Learning Representations from Temporally Smooth Data
Dec 12, 2020
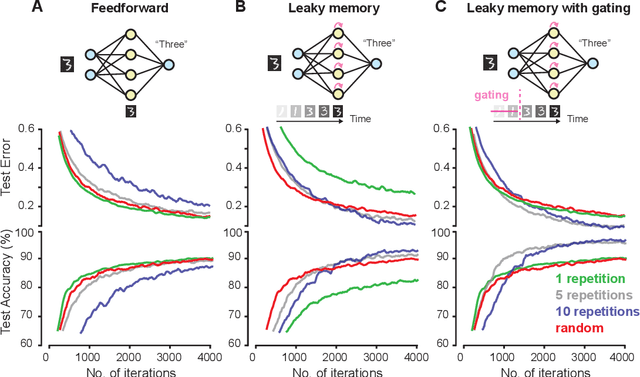
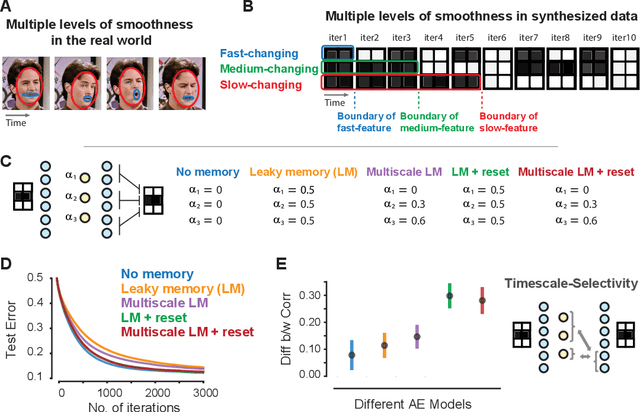
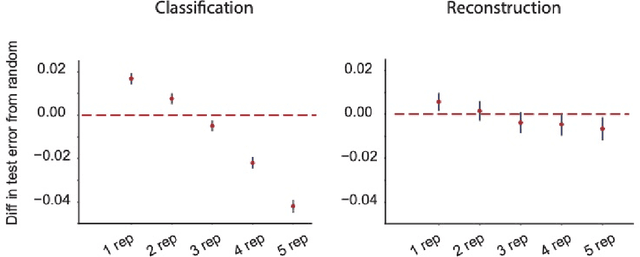
Events in the real world are correlated across nearby points in time, and we must learn from this temporally smooth data. However, when neural networks are trained to categorize or reconstruct single items, the common practice is to randomize the order of training items. What are the effects of temporally smooth training data on the efficiency of learning? We first tested the effects of smoothness in training data on incremental learning in feedforward nets and found that smoother data slowed learning. Moreover, sampling so as to minimize temporal smoothness produced more efficient learning than sampling randomly. If smoothness generally impairs incremental learning, then how can networks be modified to benefit from smoothness in the training data? We hypothesized that two simple brain-inspired mechanisms, leaky memory in activation units and memory-gating, could enable networks to rapidly extract useful representations from smooth data. Across all levels of data smoothness, these brain-inspired architectures achieved more efficient category learning than feedforward networks. This advantage persisted, even when leaky memory networks with gating were trained on smooth data and tested on randomly-ordered data. Finally, we investigated how these brain-inspired mechanisms altered the internal representations learned by the networks. We found that networks with multi-scale leaky memory and memory-gating could learn internal representations that un-mixed data sources which vary on fast and slow timescales across training samples. Altogether, we identified simple mechanisms enabling neural networks to learn more quickly from temporally smooth data, and to generate internal representations that separate timescales in the training signal.