 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Representations from Temporally Smooth Data
Paper and Code
Dec 12, 2020
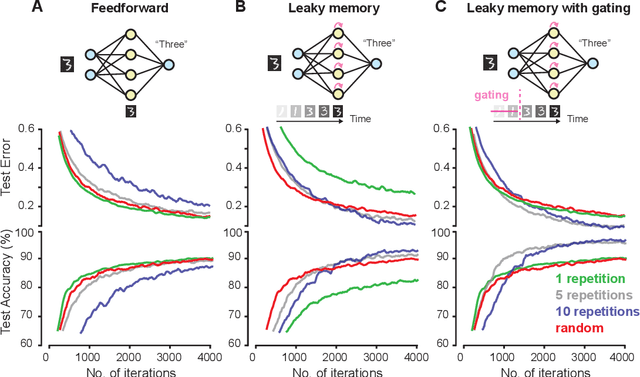
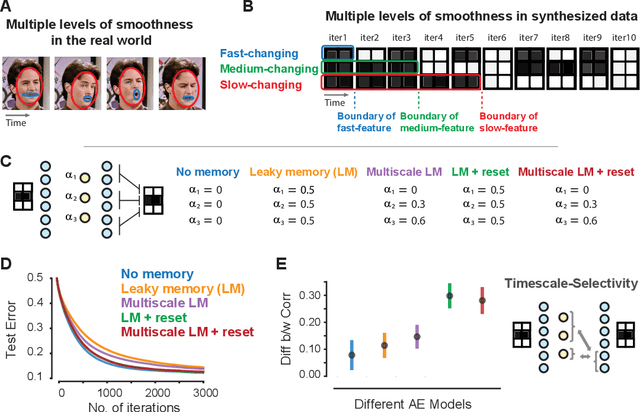
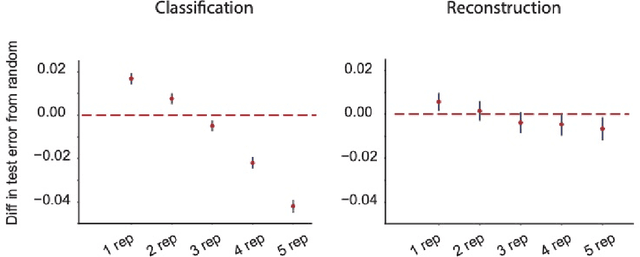
Events in the real world are correlated across nearby points in time, and we must learn from this temporally smooth data. However, when neural networks are trained to categorize or reconstruct single items, the common practice is to randomize the order of training items. What are the effects of temporally smooth training data on the efficiency of learning? We first tested the effects of smoothness in training data on incremental learning in feedforward nets and found that smoother data slowed learning. Moreover, sampling so as to minimize temporal smoothness produced more efficient learning than sampling randomly. If smoothness generally impairs incremental learning, then how can networks be modified to benefit from smoothness in the training data? We hypothesized that two simple brain-inspired mechanisms, leaky memory in activation units and memory-gating, could enable networks to rapidly extract useful representations from smooth data. Across all levels of data smoothness, these brain-inspired architectures achieved more efficient category learning than feedforward networks. This advantage persisted, even when leaky memory networks with gating were trained on smooth data and tested on randomly-ordered data. Finally, we investigated how these brain-inspired mechanisms altered the internal representations learned by the networks. We found that networks with multi-scale leaky memory and memory-gating could learn internal representations that un-mixed data sources which vary on fast and slow timescales across training samples. Altogether, we identified simple mechanisms enabling neural networks to learn more quickly from temporally smooth data, and to generate internal representations that separate timescales in the training signal.