Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Graph-RNNs for Action Detection of Multiple Activities
Paper and Code
Jan 21, 2021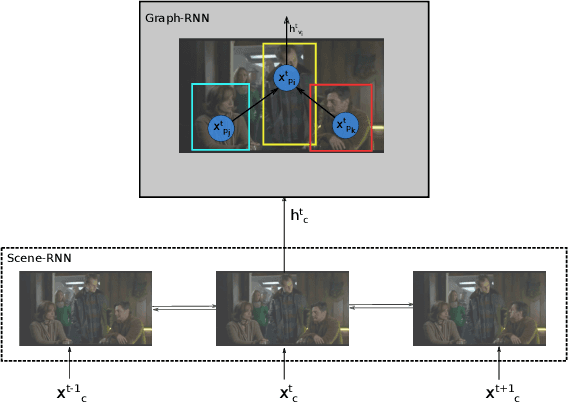



In this paper, we propose an approach that spatially localizes the activities in a video frame where each person can perform multiple activities at the same time. Our approach takes the temporal scene context as well as the relations of the actions of detected persons into account. While the temporal context is modeled by a temporal recurrent neural network (RNN), the relations of the actions are modeled by a graph RNN. Both networks are trained together and the proposed approach achieves state of the art results on the AVA dataset.
* Accepted at ICIP 2019
View paper on