 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINO-QPM: Adapting Visual Foundation Models for Globally Interpretable Image Classification
Apr 08, 2026Although visual foundation models like DINOv2 provide state-of-the-art performance as feature extractors, their complex, high-dimensional representations create substantial hurdles for interpretability. This work proposes DINO-QPM, which converts these powerful but entangled features into contrastive, class-independent representations that are interpretable by humans. DINO-QPM is a lightweight interpretability adapter that pursues globally interpretable image classification, adapting the Quadratic Programming Enhanced Model (QPM) to operate on strictly frozen DINO backbones. While classification with visual foundation models typically relies on the \texttt{CLS} token, we deliberately diverge from this standard. By leveraging average-pooling, we directly connect the patch embeddings to the model's features and therefore enable spatial localisation of DINO-QPM's globally interpretable features within the input space. Furthermore, we apply a sparsity loss to minimise spatial scatter and background noise, ensuring that explanations are grounded in relevant object parts. With DINO-QPM we make the level of interpretability of QPM available as an adapter while exceeding the accuracy of DINOv2 linear probe. Evaluated through an introduced Plausibility metric and other interpretability metrics, extensive experiments demonstrate that DINO-QPM is superior to other applicable methods for frozen visual foundation models in both classification accuracy and explanation quality.
Video Patch Pruning: Efficient Video Instance Segmentation via Early Token Reduction
Apr 01, 2026Vision Transformers (ViTs) have demonstrated state-ofthe-art performance in several benchmarks, yet their high computational costs hinders their practical deployment. Patch Pruning offers significant savings, but existing approaches restrict token reduction to deeper layers, leaving early-stage compression unexplored. This limits their potential for holistic efficiency. In this work, we present a novel Video Patch Pruning framework (VPP) that integrates temporal prior knowledge to enable efficient sparsity within early ViT layers. Our approach is motivated by the observation that prior features extracted from deeper layers exhibit strong foreground selectivity. Therefore we propose a fully differentiable module for temporal mapping to accurately select the most relevant patches in early network stages. Notably, the proposed method enables a patch reduction of up to 60% in dense prediction tasks, exceeding the capabilities of conventional image-based patch pruning, which typically operate around a 30% patch sparsity. VPP excels the high-sparsity regime, sustaining remarkable performance even when patch usage is reduced below 55%. Specifically, it preserves stable results with a maximal performance drop of 0.6% on the Youtube-VIS 2021 dataset.
UncertainSAM: Fast and Efficient Uncertainty Quantification of the Segment Anything Model
May 08, 2025The introduction of the Segment Anything Model (SAM) has paved the way for numerous semantic segmentation applications. For several tasks, quantifying the uncertainty of SAM is of particular interest. However, the ambiguous nature of the class-agnostic foundation model SAM challenges current uncertainty quantification (UQ) approaches. This paper presents a theoretically motivated uncertainty quantification model based on a Bayesian entropy formulation jointly respecting aleatoric, epistemic, and the newly introduced task uncertainty. We use this formulation to train USAM, a lightweight post-hoc UQ method. Our model traces the root of uncertainty back to under-parameterised models, insufficient prompts or image ambiguities. Our proposed deterministic USAM demonstrates superior predictive capabilities on the SA-V, MOSE, ADE20k, DAVIS, and COCO datasets, offering a computationally cheap and easy-to-use UQ alternative that can support user-prompting, enhance semi-supervised pipelines, or balance the tradeoff between accuracy and cost efficiency.
QPM: Discrete Optimization for Globally Interpretable Image Classification
Feb 27, 2025

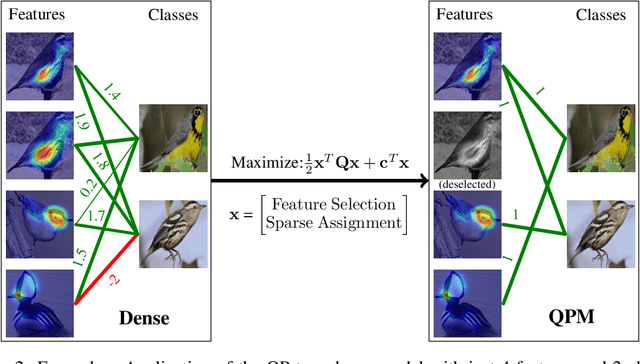
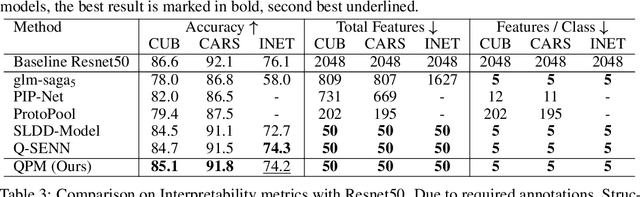
Understanding the classifications of deep neural networks, e.g. used in safety-critical situations, is becoming increasingly important. While recent models can locally explain a single decision, to provide a faithful global explanation about an accurate model's general behavior is a more challenging open task. Towards that goal, we introduce the Quadratic Programming Enhanced Model (QPM), which learns globally interpretable class representations. QPM represents every class with a binary assignment of very few, typically 5, features, that are also assigned to other classes, ensuring easily comparable contrastive class representations. This compact binary assignment is found using discrete optimization based on predefined similarity measures and interpretability constraints. The resulting optimal assignment is used to fine-tune the diverse features, so that each of them becomes the shared general concept between the assigned classes. Extensive evaluations show that QPM delivers unprecedented global interpretability across small and large-scale datasets while setting the state of the art for the accuracy of interpretable models.
Q-SENN: Quantized Self-Explaining Neural Networks
Dec 21, 2023Explanations in Computer Vision are often desired, but most Deep Neural Networks can only provide saliency maps with questionable faithfulness. Self-Explaining Neural Networks (SENN) extract interpretable concepts with fidelity, diversity, and grounding to combine them linearly for decision-making. While they can explain what was recognized, initial realizations lack accuracy and general applicability. We propose the Quantized-Self-Explaining Neural Network Q-SENN. Q-SENN satisfies or exceeds the desiderata of SENN while being applicable to more complex datasets and maintaining most or all of the accuracy of an uninterpretable baseline model, out-performing previous work in all considered metrics. Q-SENN describes the relationship between every class and feature as either positive, negative or neutral instead of an arbitrary number of possible relations, enforcing more binary human-friendly features. Since every class is assigned just 5 interpretable features on average, Q-SENN shows convincing local and global interpretability. Additionally, we propose a feature alignment method, capable of aligning learned features with human language-based concepts without additional supervision. Thus, what is learned can be more easily verbalized. The code is published: https://github.com/ThomasNorr/Q-SENN
Take 5: Interpretable Image Classification with a Handful of Features
Mar 23, 2023



Deep Neural Networks use thousands of mostly incomprehensible features to identify a single class, a decision no human can follow. We propose an interpretable sparse and low dimensional final decision layer in a deep neural network with measurable aspects of interpretability and demonstrate it on fine-grained image classification. We argue that a human can only understand the decision of a machine learning model, if the features are interpretable and only very few of them are used for a single decision. For that matter, the final layer has to be sparse and, to make interpreting the features feasible, low dimensional. We call a model with a Sparse Low-Dimensional Decision SLDD-Model. We show that a SLDD-Model is easier to interpret locally and globally than a dense high-dimensional decision layer while being able to maintain competitive accuracy. Additionally, we propose a loss function that improves a model's feature diversity and accuracy. Our more interpretable SLDD-Model only uses 5 out of just 50 features per class, while maintaining 97% to 100% of the accuracy on four common benchmark datasets compared to the baseline model with 2048 features.