 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainSAM: Fast and Efficient Uncertainty Quantification of the Segment Anything Model
May 08, 2025The introduction of the Segment Anything Model (SAM) has paved the way for numerous semantic segmentation applications. For several tasks, quantifying the uncertainty of SAM is of particular interest. However, the ambiguous nature of the class-agnostic foundation model SAM challenges current uncertainty quantification (UQ) approaches. This paper presents a theoretically motivated uncertainty quantification model based on a Bayesian entropy formulation jointly respecting aleatoric, epistemic, and the newly introduced task uncertainty. We use this formulation to train USAM, a lightweight post-hoc UQ method. Our model traces the root of uncertainty back to under-parameterised models, insufficient prompts or image ambiguities. Our proposed deterministic USAM demonstrates superior predictive capabilities on the SA-V, MOSE, ADE20k, DAVIS, and COCO datasets, offering a computationally cheap and easy-to-use UQ alternative that can support user-prompting, enhance semi-supervised pipelines, or balance the tradeoff between accuracy and cost efficiency.
QPM: Discrete Optimization for Globally Interpretable Image Classification
Feb 27, 2025

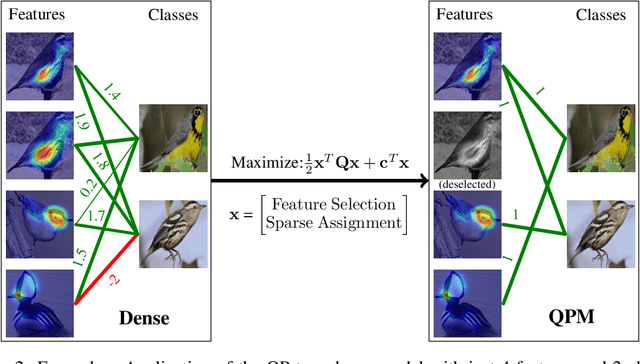
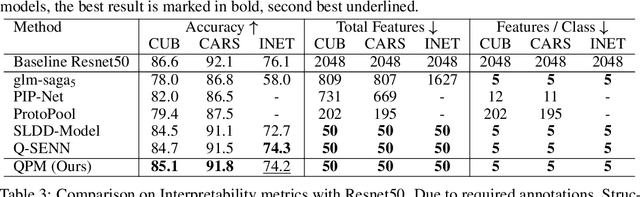
Understanding the classifications of deep neural networks, e.g. used in safety-critical situations, is becoming increasingly important. While recent models can locally explain a single decision, to provide a faithful global explanation about an accurate model's general behavior is a more challenging open task. Towards that goal, we introduce the Quadratic Programming Enhanced Model (QPM), which learns globally interpretable class representations. QPM represents every class with a binary assignment of very few, typically 5, features, that are also assigned to other classes, ensuring easily comparable contrastive class representations. This compact binary assignment is found using discrete optimization based on predefined similarity measures and interpretability constraints. The resulting optimal assignment is used to fine-tune the diverse features, so that each of them becomes the shared general concept between the assigned classes. Extensive evaluations show that QPM delivers unprecedented global interpretability across small and large-scale datasets while setting the state of the art for the accuracy of interpretable models.
CHOTA: A Higher Order Accuracy Metric for Cell Tracking
Aug 21, 2024



The evaluation of cell tracking results steers the development of tracking methods, significantly impacting biomedical research. This is quantitatively achieved by means of evaluation metrics. Unfortunately, current metrics favor local correctness and weakly reward global coherence, impeding high-level biological analysis. To also foster global coherence, we propose the CHOTA metric (Cell-specific Higher Order Tracking Accuracy) which unifies the evaluation of all relevant aspects of cell tracking: cell detections and local associations, global coherence, and lineage tracking. We achieve this by introducing a new definition of the term 'trajectory' that includes the entire cell lineage and by including this into the well-established HOTA metric from general multiple object tracking. Furthermore, we provide a detailed survey of contemporary cell tracking metrics to compare our novel CHOTA metric and to show its advantages. All metrics are extensively evaluated on state-of-the-art real-data cell tracking results and synthetic results that simulate specific tracking errors. We show that CHOTA is sensitive to all tracking errors and gives a good indication of the biologically relevant capability of a method to reconstruct the full lineage of cells. It introduces a robust and comprehensive alternative to the currently used metrics in cell tracking. Python code is available at https://github.com/CellTrackingChallenge/py-ctcmetrics .
Cell Tracking according to Biological Needs -- Strong Mitosis-aware Random-finite Sets Tracker with Aleatoric Uncertainty
Mar 25, 2024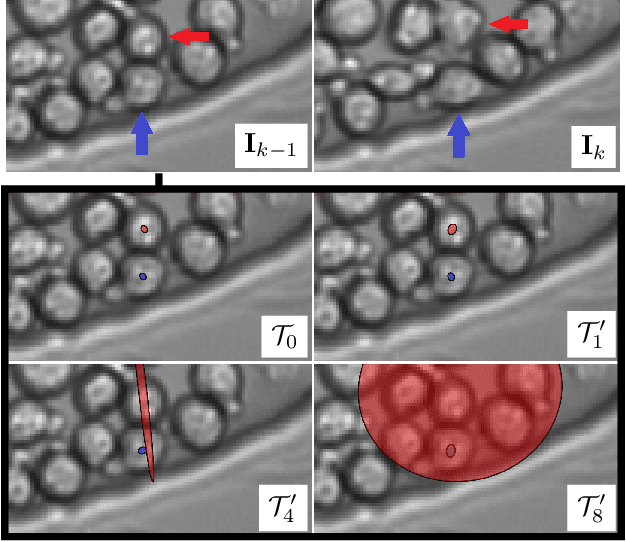
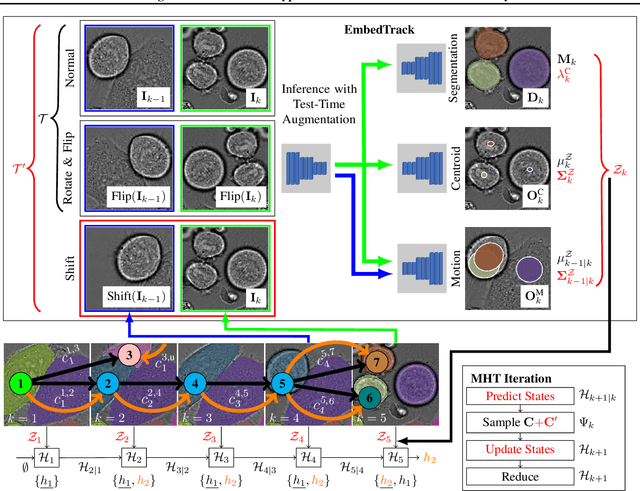
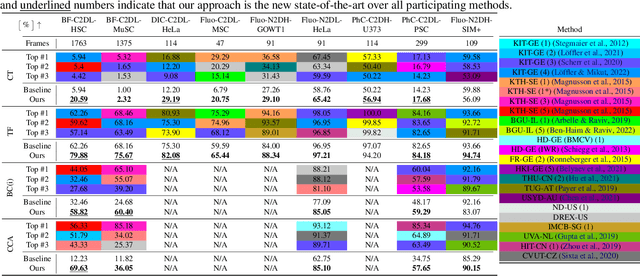
Cell tracking and segmentation assist biologists in extracting insights from large-scale microscopy time-lapse data. Driven by local accuracy metrics, current tracking approaches often suffer from a lack of long-term consistency. To address this issue, we introduce an uncertainty estimation technique for neural tracking-by-regression frameworks and incorporate it into our novel extended Poisson multi-Bernoulli mixture tracker. Our uncertainty estimation identifies uncertain associations within high-performing tracking-by-regression methods using problem-specific test-time augmentations. Leveraging this uncertainty, along with a novel mitosis-aware assignment problem formulation, our tracker resolves false associations and mitosis detections stemming from long-term conflicts. We evaluate our approach on nine competitive datasets and demonstrate that it outperforms the current state-of-the-art on biologically relevant metrics substantially, achieving improvements by a factor of approximately $5.75$. Furthermore, we uncover new insights into the behavior of tracking-by-regression uncertainty.
HyperSparse Neural Networks: Shifting Exploration to Exploitation through Adaptive Regularization
Aug 16, 2023


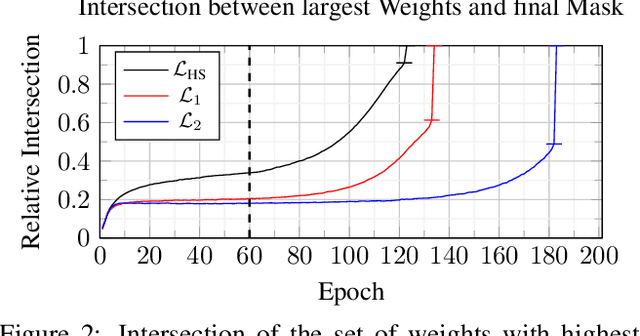
Sparse neural networks are a key factor in developing resource-efficient machine learning applications. We propose the novel and powerful sparse learning method Adaptive Regularized Training (ART) to compress dense into sparse networks. Instead of the commonly used binary mask during training to reduce the number of model weights, we inherently shrink weights close to zero in an iterative manner with increasing weight regularization. Our method compresses the pre-trained model knowledge into the weights of highest magnitude. Therefore, we introduce a novel regularization loss named HyperSparse that exploits the highest weights while conserving the ability of weight exploration. Extensive experiments on CIFAR and TinyImageNet show that our method leads to notable performance gains compared to other sparsification methods, especially in extremely high sparsity regimes up to 99.8 percent model sparsity. Additional investigations provide new insights into the patterns that are encoded in weights with high magnitudes.
Compensation Learning in Semantic Segmentation
Apr 26, 2023Label noise and ambiguities between similar classes are challenging problems in developing new models and annotating new data for semantic segmentation. In this paper, we propose Compensation Learning in Semantic Segmentation, a framework to identify and compensate ambiguities as well as label noise. More specifically, we add a ground truth depending and globally learned bias to the classification logits and introduce a novel uncertainty branch for neural networks to induce the compensation bias only to relevant regions. Our method is employed into state-of-the-art segmentation frameworks and several experiments demonstrate that our proposed compensation learns inter-class relations that allow global identification of challenging ambiguities as well as the exact localization of subsequent label noise. Additionally, it enlarges robustness against label noise during training and allows target-oriented manipulation during inference. We evaluate the proposed method on %the widely used datasets Cityscapes, KITTI-STEP, ADE20k, and COCO-stuff10k.
Blind Knowledge Distillation for Robust Image Classification
Nov 21, 2022Optimizing neural networks with noisy labels is a challenging task, especially if the label set contains real-world noise. Networks tend to generalize to reasonable patterns in the early training stages and overfit to specific details of noisy samples in the latter ones. We introduce Blind Knowledge Distillation - a novel teacher-student approach for learning with noisy labels by masking the ground truth related teacher output to filter out potentially corrupted knowledge and to estimate the tipping point from generalizing to overfitting. Based on this, we enable the estimation of noise in the training data with Otsus algorithm. With this estimation, we train the network with a modified weighted cross-entropy loss function. We show in our experiments that Blind Knowledge Distillation detects overfitting effectively during training and improves the detection of clean and noisy labels on the recently published CIFAR-N dataset. Code is available at GitHub.
Making Higher Order MOT Scalable: An Efficient Approximate Solver for Lifted Disjoint Paths
Aug 24, 2021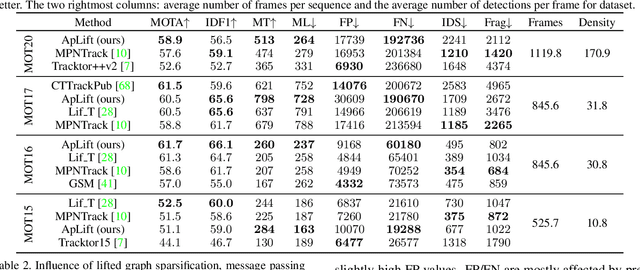
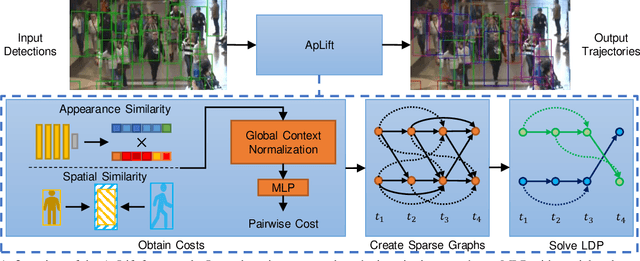
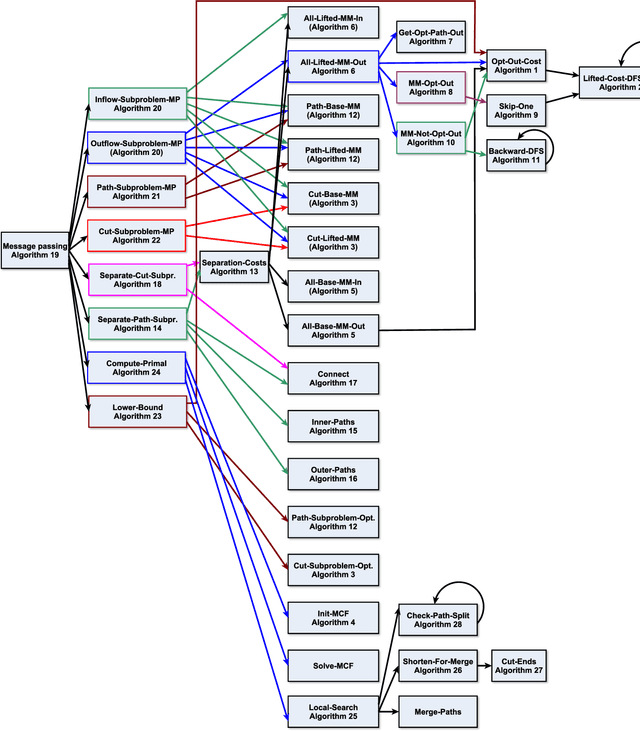
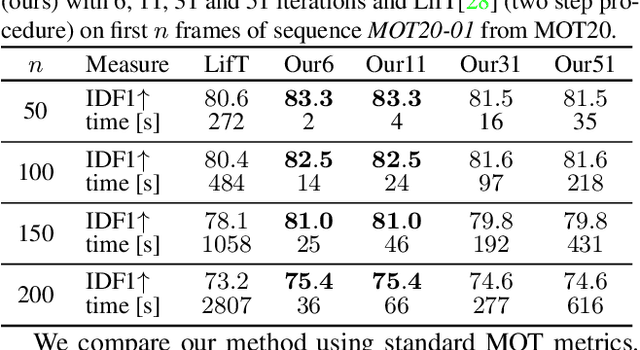
We present an efficient approximate message passing solver for the lifted disjoint paths problem (LDP), a natural but NP-hard model for multiple object tracking (MOT). Our tracker scales to very large instances that come from long and crowded MOT sequences. Our approximate solver enables us to process the MOT15/16/17 benchmarks without sacrificing solution quality and allows for solving MOT20, which has been out of reach up to now for LDP solvers due to its size and complexity. On all these four standard MOT benchmarks we achieve performance comparable or better than current state-of-the-art methods including a tracker based on an optimal LDP solver.