 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReRAW: RGB-to-RAW Image Reconstruction via Stratified Sampling for Efficient Object Detection on the Edge
Mar 04, 2025



Edge-based computer vision models running on compact, resource-limited devices benefit greatly from using unprocessed, detail-rich RAW sensor data instead of processed RGB images. Training these models, however, necessitates large labeled RAW datasets, which are costly and often impractical to obtain. Thus, converting existing labeled RGB datasets into sensor-specific RAW images becomes crucial for effective model training. In this paper, we introduce ReRAW, an RGB-to-RAW conversion model that achieves state-of-the-art reconstruction performance across five diverse RAW datasets. This is accomplished through ReRAW's novel multi-head architecture predicting RAW image candidates in gamma space. The performance is further boosted by a stratified sampling-based training data selection heuristic, which helps the model better reconstruct brighter RAW pixels. We finally demonstrate that pretraining compact models on a combination of high-quality synthetic RAW datasets (such as generated by ReRAW) and ground-truth RAW images for downstream tasks like object detection, outperforms both standard RGB pipelines, and RAW fine-tuning of RGB-pretrained models for the same task.
HydraMix: Multi-Image Feature Mixing for Small Data Image Classification
Jan 16, 2025



Training deep neural networks requires datasets with a large number of annotated examples. The collection and annotation of these datasets is not only extremely expensive but also faces legal and privacy problems. These factors are a significant limitation for many real-world applications. To address this, we introduce HydraMix, a novel architecture that generates new image compositions by mixing multiple different images from the same class. HydraMix learns the fusion of the content of various images guided by a segmentation-based mixing mask in feature space and is optimized via a combination of unsupervised and adversarial training. Our data augmentation scheme allows the creation of models trained from scratch on very small datasets. We conduct extensive experiments on ciFAIR-10, STL-10, and ciFAIR-100. Additionally, we introduce a novel text-image metric to assess the generality of the augmented datasets. Our results show that HydraMix outperforms existing state-of-the-art methods for image classification on small datasets.
RAW-Diffusion: RGB-Guided Diffusion Models for High-Fidelity RAW Image Generation
Nov 20, 2024



Current deep learning approaches in computer vision primarily focus on RGB data sacrificing information. In contrast, RAW images offer richer representation, which is crucial for precise recognition, particularly in challenging conditions like low-light environments. The resultant demand for comprehensive RAW image datasets contrasts with the labor-intensive process of creating specific datasets for individual sensors. To address this, we propose a novel diffusion-based method for generating RAW images guided by RGB images. Our approach integrates an RGB-guidance module for feature extraction from RGB inputs, then incorporates these features into the reverse diffusion process with RGB-guided residual blocks across various resolutions. This approach yields high-fidelity RAW images, enabling the creation of camera-specific RAW datasets. Our RGB2RAW experiments on four DSLR datasets demonstrate state-of-the-art performance. Moreover, RAW-Diffusion demonstrates exceptional data efficiency, achieving remarkable performance with as few as 25 training samples or even fewer. We extend our method to create BDD100K-RAW and Cityscapes-RAW datasets, revealing its effectiveness for object detection in RAW imagery, significantly reducing the amount of required RAW images.
Compensation Learning in Semantic Segmentation
Apr 26, 2023Label noise and ambiguities between similar classes are challenging problems in developing new models and annotating new data for semantic segmentation. In this paper, we propose Compensation Learning in Semantic Segmentation, a framework to identify and compensate ambiguities as well as label noise. More specifically, we add a ground truth depending and globally learned bias to the classification logits and introduce a novel uncertainty branch for neural networks to induce the compensation bias only to relevant regions. Our method is employed into state-of-the-art segmentation frameworks and several experiments demonstrate that our proposed compensation learns inter-class relations that allow global identification of challenging ambiguities as well as the exact localization of subsequent label noise. Additionally, it enlarges robustness against label noise during training and allows target-oriented manipulation during inference. We evaluate the proposed method on %the widely used datasets Cityscapes, KITTI-STEP, ADE20k, and COCO-stuff10k.
Blind Knowledge Distillation for Robust Image Classification
Nov 21, 2022Optimizing neural networks with noisy labels is a challenging task, especially if the label set contains real-world noise. Networks tend to generalize to reasonable patterns in the early training stages and overfit to specific details of noisy samples in the latter ones. We introduce Blind Knowledge Distillation - a novel teacher-student approach for learning with noisy labels by masking the ground truth related teacher output to filter out potentially corrupted knowledge and to estimate the tipping point from generalizing to overfitting. Based on this, we enable the estimation of noise in the training data with Otsus algorithm. With this estimation, we train the network with a modified weighted cross-entropy loss function. We show in our experiments that Blind Knowledge Distillation detects overfitting effectively during training and improves the detection of clean and noisy labels on the recently published CIFAR-N dataset. Code is available at GitHub.
Image Classification on Small Datasets via Masked Feature Mixing
Feb 23, 2022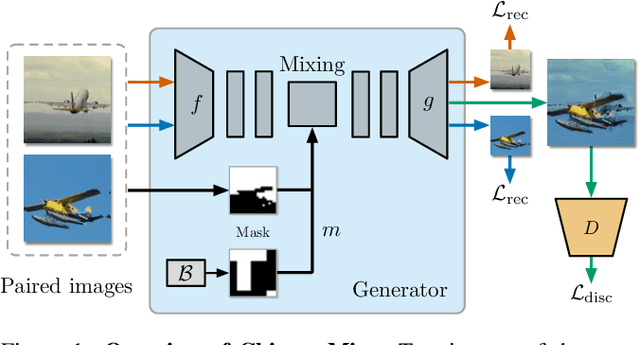
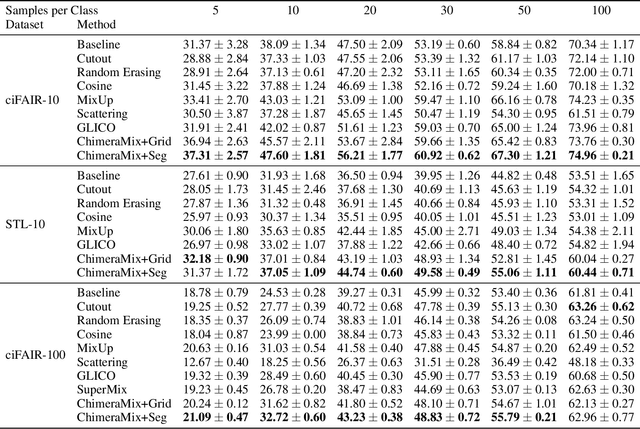

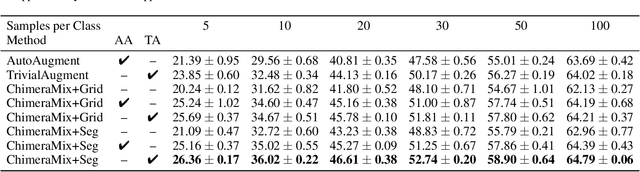
Deep convolutional neural networks require large amounts of labeled data samples. For many real-world applications, this is a major limitation which is commonly treated by augmentation methods. In this work, we address the problem of learning deep neural networks on small datasets. Our proposed architecture called ChimeraMix learns a data augmentation by generating compositions of instances. The generative model encodes images in pairs, combines the features guided by a mask, and creates new samples. For evaluation, all methods are trained from scratch without any additional data. Several experiments on benchmark datasets, e.g. ciFAIR-10, STL-10, and ciFAIR-100, demonstrate the superior performance of ChimeraMix compared to current state-of-the-art methods for classification on small datasets.
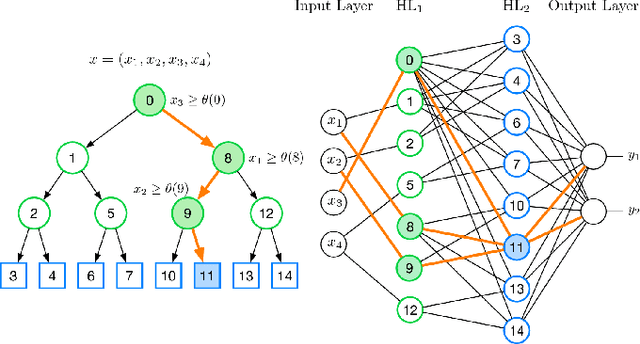
Neural Random Forest Imitation
Nov 25, 2019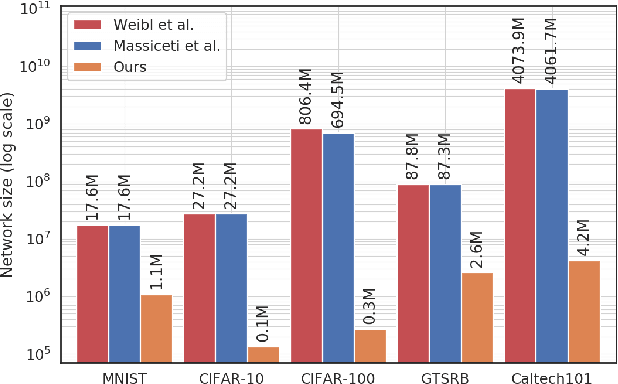

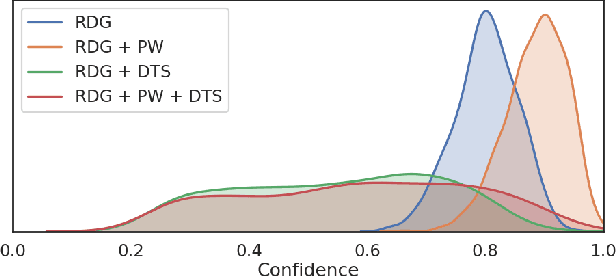
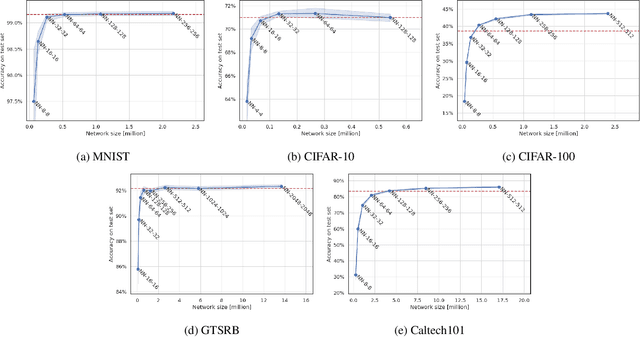
We present Neural Random Forest Imitation - a novel approach for transforming random forests into neural networks. Existing methods produce very inefficient architectures and do not scale. In this paper, we introduce a new method for generating data from a random forest and learning a neural network that imitates it. Without any additional training data, this transformation creates very efficient neural networks that learn the decision boundaries of a random forest. The generated model is fully differentiable and can be combined with the feature extraction in a single pipeline enabling further end-to-end processing. Experiments on several real-world benchmark datasets demonstrate outstanding performance in terms of scalability, accuracy, and learning with very few training examples. Compared to state-of-the-art mappings, we significantly reduce the network size while achieving the same or even improved accuracy due to better generalization.
Object Recognition from very few Training Examples for Enhancing Bicycle Maps
May 28, 2018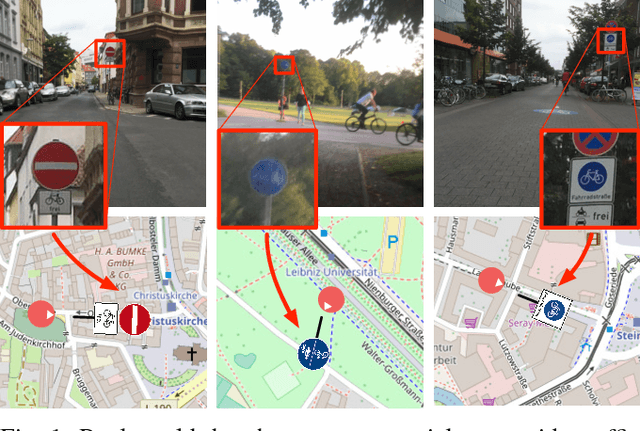
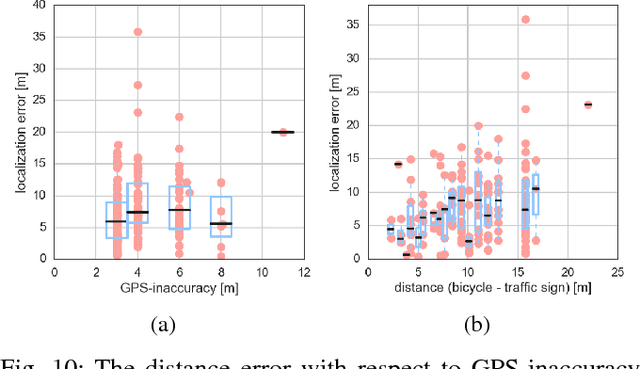

In recent years, data-driven methods have shown great success for extracting information about the infrastructure in urban areas. These algorithms are usually trained on large datasets consisting of thousands or millions of labeled training examples. While large datasets have been published regarding cars, for cyclists very few labeled data is available although appearance, point of view, and positioning of even relevant objects differ. Unfortunately, labeling data is costly and requires a huge amount of work. In this paper, we thus address the problem of learning with very few labels. The aim is to recognize particular traffic signs in crowdsourced data to collect information which is of interest to cyclists. We propose a system for object recognition that is trained with only 15 examples per class on average. To achieve this, we combine the advantages of convolutional neural networks and random forests to learn a patch-wise classifier. In the next step, we map the random forest to a neural network and transform the classifier to a fully convolutional network. Thereby, the processing of full images is significantly accelerated and bounding boxes can be predicted. Finally, we integrate data of the Global Positioning System (GPS) to localize the predictions on the map. In comparison to Faster R-CNN and other networks for object recognition or algorithms for transfer learning, we considerably reduce the required amount of labeled data. We demonstrate good performance on the recognition of traffic signs for cyclists as well as their localization in maps.