 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReRAW: RGB-to-RAW Image Reconstruction via Stratified Sampling for Efficient Object Detection on the Edge
Mar 04, 2025



Edge-based computer vision models running on compact, resource-limited devices benefit greatly from using unprocessed, detail-rich RAW sensor data instead of processed RGB images. Training these models, however, necessitates large labeled RAW datasets, which are costly and often impractical to obtain. Thus, converting existing labeled RGB datasets into sensor-specific RAW images becomes crucial for effective model training. In this paper, we introduce ReRAW, an RGB-to-RAW conversion model that achieves state-of-the-art reconstruction performance across five diverse RAW datasets. This is accomplished through ReRAW's novel multi-head architecture predicting RAW image candidates in gamma space. The performance is further boosted by a stratified sampling-based training data selection heuristic, which helps the model better reconstruct brighter RAW pixels. We finally demonstrate that pretraining compact models on a combination of high-quality synthetic RAW datasets (such as generated by ReRAW) and ground-truth RAW images for downstream tasks like object detection, outperforms both standard RGB pipelines, and RAW fine-tuning of RGB-pretrained models for the same task.
RAW-Diffusion: RGB-Guided Diffusion Models for High-Fidelity RAW Image Generation
Nov 20, 2024



Current deep learning approaches in computer vision primarily focus on RGB data sacrificing information. In contrast, RAW images offer richer representation, which is crucial for precise recognition, particularly in challenging conditions like low-light environments. The resultant demand for comprehensive RAW image datasets contrasts with the labor-intensive process of creating specific datasets for individual sensors. To address this, we propose a novel diffusion-based method for generating RAW images guided by RGB images. Our approach integrates an RGB-guidance module for feature extraction from RGB inputs, then incorporates these features into the reverse diffusion process with RGB-guided residual blocks across various resolutions. This approach yields high-fidelity RAW images, enabling the creation of camera-specific RAW datasets. Our RGB2RAW experiments on four DSLR datasets demonstrate state-of-the-art performance. Moreover, RAW-Diffusion demonstrates exceptional data efficiency, achieving remarkable performance with as few as 25 training samples or even fewer. We extend our method to create BDD100K-RAW and Cityscapes-RAW datasets, revealing its effectiveness for object detection in RAW imagery, significantly reducing the amount of required RAW images.
A Structured Dictionary Perspective on Implicit Neural Representations
Dec 03, 2021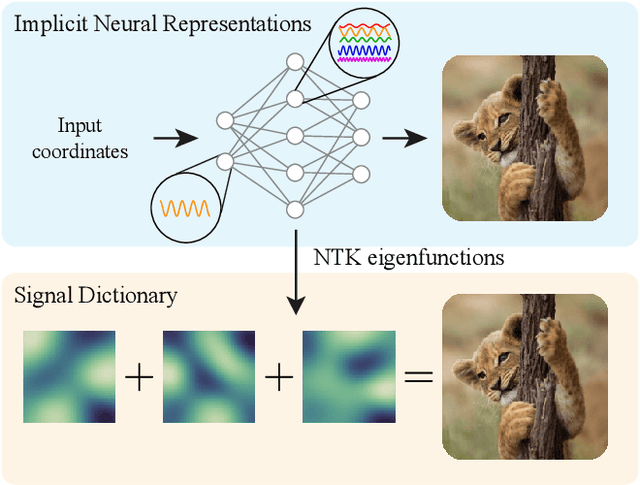
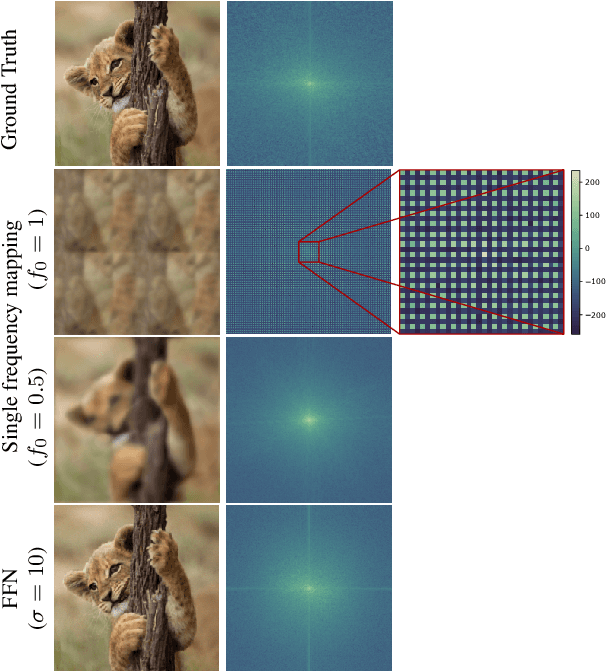
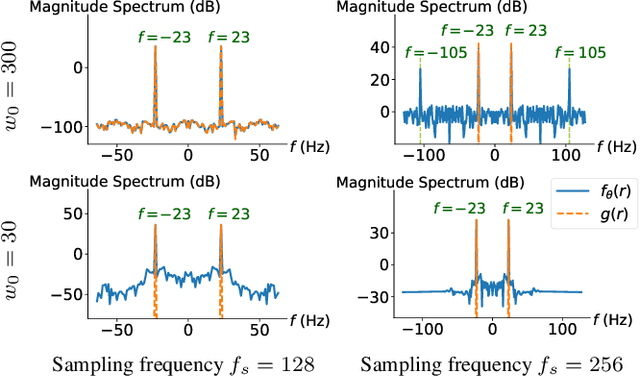
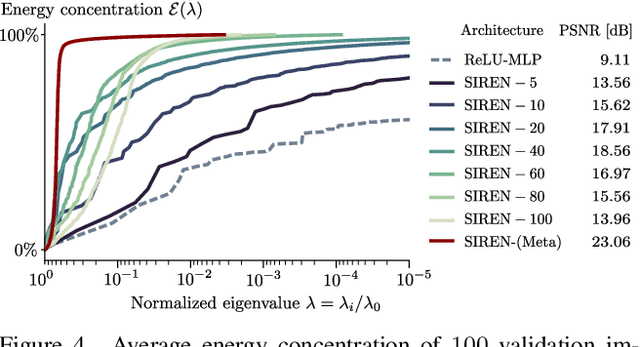
Propelled by new designs that permit to circumvent the spectral bias, implicit neural representations (INRs) have recently emerged as a promising alternative to classical discretized representations of signals. Nevertheless, despite their practical success, we still lack a proper theoretical characterization of how INRs represent signals. In this work, we aim to fill this gap, and we propose a novel unified perspective to theoretically analyse INRs. Leveraging results from harmonic analysis and deep learning theory, we show that most INR families are analogous to structured signal dictionaries whose atoms are integer harmonics of the set of initial mapping frequencies. This structure allows INRs to express signals with an exponentially increasing frequency support using a number of parameters that only grows linearly with depth. Afterwards, we explore the inductive bias of INRs exploiting recent results about the empirical neural tangent kernel (NTK). Specifically, we show that the eigenfunctions of the NTK can be seen as dictionary atoms whose inner product with the target signal determines the final performance of their reconstruction. In this regard, we reveal that meta-learning the initialization has a reshaping effect of the NTK analogous to dictionary learning, building dictionary atoms as a combination of the examples seen during meta-training. Our results permit to design and tune novel INR architectures, but can also be of interest for the wider deep learning theory community.
Self-Supervision by Prediction for Object Discovery in Videos
Mar 09, 2021



Despite their irresistible success, deep learning algorithms still heavily rely on annotated data. On the other hand, unsupervised settings pose many challenges, especially about determining the right inductive bias in diverse scenarios. One scalable solution is to make the model generate the supervision for itself by leveraging some part of the input data, which is known as self-supervised learning. In this paper, we use the prediction task as self-supervision and build a novel object-centric model for image sequence representation. In addition to disentangling the notion of objects and the motion dynamics, our compositional structure explicitly handles occlusion and inpaints inferred objects and background for the composition of the predicted frame. With the aid of auxiliary loss functions that promote spatially and temporally consistent object representations, our self-supervised framework can be trained without the help of any manual annotation or pretrained network. Initial experiments confirm that the proposed pipeline is a promising step towards object-centric video prediction.