 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Uncertainty in 2D Pose Detectors for Probabilistic 3D Human Mesh Recovery
Nov 25, 2024Monocular 3D human pose and shape estimation is an inherently ill-posed problem due to depth ambiguities, occlusions, and truncations. Recent probabilistic approaches learn a distribution over plausible 3D human meshes by maximizing the likelihood of the ground-truth pose given an image. We show that this objective function alone is not sufficient to best capture the full distributions. Instead, we propose to additionally supervise the learned distributions by minimizing the distance to distributions encoded in heatmaps of a 2D pose detector. Moreover, we reveal that current methods often generate incorrect hypotheses for invisible joints which is not detected by the evaluation protocols. We demonstrate that person segmentation masks can be utilized during training to significantly decrease the number of invalid samples and introduce two metrics to evaluate it. Our normalizing flow-based approach predicts plausible 3D human mesh hypotheses that are consistent with the image evidence while maintaining high diversity for ambiguous body parts. Experiments on 3DPW and EMDB show that we outperform other state-of-the-art probabilistic methods. Code is available for research purposes at https://github.com/twehrbein/humr.
SplatPose & Detect: Pose-Agnostic 3D Anomaly Detection
Apr 10, 2024Detecting anomalies in images has become a well-explored problem in both academia and industry. State-of-the-art algorithms are able to detect defects in increasingly difficult settings and data modalities. However, most current methods are not suited to address 3D objects captured from differing poses. While solutions using Neural Radiance Fields (NeRFs) have been proposed, they suffer from excessive computation requirements, which hinder real-world usability. For this reason, we propose the novel 3D Gaussian splatting-based framework SplatPose which, given multi-view images of a 3D object, accurately estimates the pose of unseen views in a differentiable manner, and detects anomalies in them. We achieve state-of-the-art results in both training and inference speed, and detection performance, even when using less training data than competing methods. We thoroughly evaluate our framework using the recently proposed Pose-agnostic Anomaly Detection benchmark and its multi-pose anomaly detection (MAD) data set.
Q-SENN: Quantized Self-Explaining Neural Networks
Dec 21, 2023Explanations in Computer Vision are often desired, but most Deep Neural Networks can only provide saliency maps with questionable faithfulness. Self-Explaining Neural Networks (SENN) extract interpretable concepts with fidelity, diversity, and grounding to combine them linearly for decision-making. While they can explain what was recognized, initial realizations lack accuracy and general applicability. We propose the Quantized-Self-Explaining Neural Network Q-SENN. Q-SENN satisfies or exceeds the desiderata of SENN while being applicable to more complex datasets and maintaining most or all of the accuracy of an uninterpretable baseline model, out-performing previous work in all considered metrics. Q-SENN describes the relationship between every class and feature as either positive, negative or neutral instead of an arbitrary number of possible relations, enforcing more binary human-friendly features. Since every class is assigned just 5 interpretable features on average, Q-SENN shows convincing local and global interpretability. Additionally, we propose a feature alignment method, capable of aligning learned features with human language-based concepts without additional supervision. Thus, what is learned can be more easily verbalized. The code is published: https://github.com/ThomasNorr/Q-SENN
The voraus-AD Dataset for Anomaly Detection in Robot Applications
Nov 08, 2023



During the operation of industrial robots, unusual events may endanger the safety of humans and the quality of production. When collecting data to detect such cases, it is not ensured that data from all potentially occurring errors is included as unforeseeable events may happen over time. Therefore, anomaly detection (AD) delivers a practical solution, using only normal data to learn to detect unusual events. We introduce a dataset that allows training and benchmarking of anomaly detection methods for robotic applications based on machine data which will be made publicly available to the research community. As a typical robot task the dataset includes a pick-and-place application which involves movement, actions of the end effector and interactions with the objects of the environment. Since several of the contained anomalies are not task-specific but general, evaluations on our dataset are transferable to other robotics applications as well. Additionally, we present MVT-Flow (multivariate time-series flow) as a new baseline method for anomaly detection: It relies on deep-learning-based density estimation with normalizing flows, tailored to the data domain by taking its structure into account for the architecture. Our evaluation shows that MVT-Flow outperforms baselines from previous work by a large margin of 6.2% in area under ROC.
Take 5: Interpretable Image Classification with a Handful of Features
Mar 23, 2023



Deep Neural Networks use thousands of mostly incomprehensible features to identify a single class, a decision no human can follow. We propose an interpretable sparse and low dimensional final decision layer in a deep neural network with measurable aspects of interpretability and demonstrate it on fine-grained image classification. We argue that a human can only understand the decision of a machine learning model, if the features are interpretable and only very few of them are used for a single decision. For that matter, the final layer has to be sparse and, to make interpreting the features feasible, low dimensional. We call a model with a Sparse Low-Dimensional Decision SLDD-Model. We show that a SLDD-Model is easier to interpret locally and globally than a dense high-dimensional decision layer while being able to maintain competitive accuracy. Additionally, we propose a loss function that improves a model's feature diversity and accuracy. Our more interpretable SLDD-Model only uses 5 out of just 50 features per class, while maintaining 97% to 100% of the accuracy on four common benchmark datasets compared to the baseline model with 2048 features.
Semantic Segmentation for Fully Automated Macrofouling Analysis on Coatings after Field Exposure
Nov 21, 2022Biofouling is a major challenge for sustainable shipping, filter membranes, heat exchangers, and medical devices. The development of fouling-resistant coatings requires the evaluation of their effectiveness. Such an evaluation is usually based on the assessment of fouling progression after different exposure times to the target medium (e.g., salt water). The manual assessment of macrofouling requires expert knowledge about local fouling communities due to high variances in phenotypical appearance, has single-image sampling inaccuracies for certain species, and lacks spatial information. Here we present an approach for automatic image-based macrofouling analysis. We created a dataset with dense labels prepared from field panel images and propose a convolutional network (adapted U-Net) for the semantic segmentation of different macrofouling classes. The establishment of macrofouling localization allows for the generation of a successional model which enables the determination of direct surface attachment and in-depth epibiotic studies.
Asymmetric Student-Teacher Networks for Industrial Anomaly Detection
Oct 18, 2022
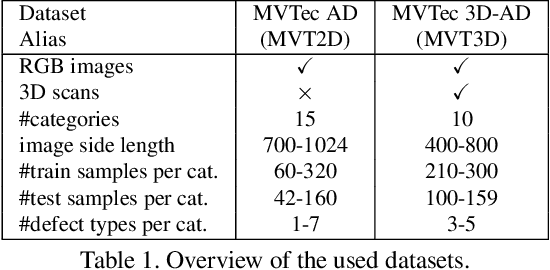

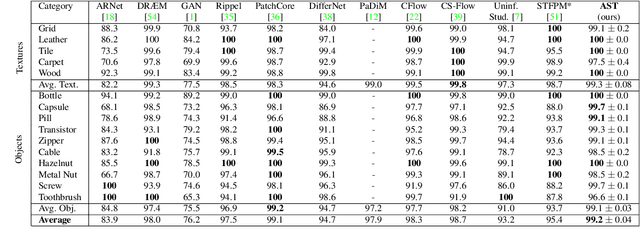
Industrial defect detection is commonly addressed with anomaly detection (AD) methods where no or only incomplete data of potentially occurring defects is available. This work discovers previously unknown problems of student-teacher approaches for AD and proposes a solution, where two neural networks are trained to produce the same output for the defect-free training examples. The core assumption of student-teacher networks is that the distance between the outputs of both networks is larger for anomalies since they are absent in training. However, previous methods suffer from the similarity of student and teacher architecture, such that the distance is undesirably small for anomalies. For this reason, we propose asymmetric student-teacher networks (AST). We train a normalizing flow for density estimation as a teacher and a conventional feed-forward network as a student to trigger large distances for anomalies: The bijectivity of the normalizing flow enforces a divergence of teacher outputs for anomalies compared to normal data. Outside the training distribution the student cannot imitate this divergence due to its fundamentally different architecture. Our AST network compensates for wrongly estimated likelihoods by a normalizing flow, which was alternatively used for anomaly detection in previous work. We show that our method produces state-of-the-art results on the two currently most relevant defect detection datasets MVTec AD and MVTec 3D-AD regarding image-level anomaly detection on RGB and 3D data.
Fully Convolutional Cross-Scale-Flows for Image-based Defect Detection
Oct 06, 2021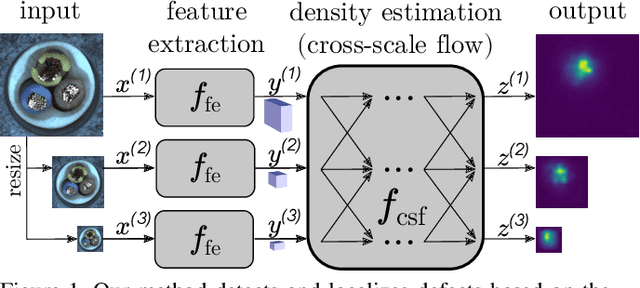
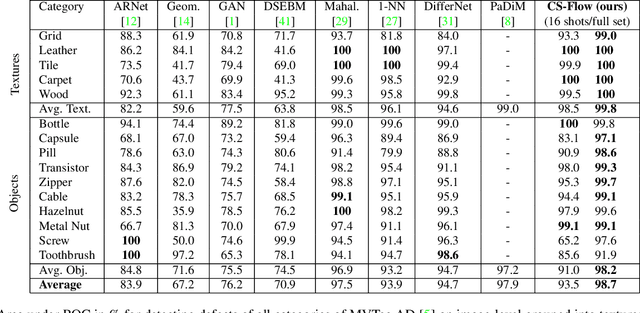
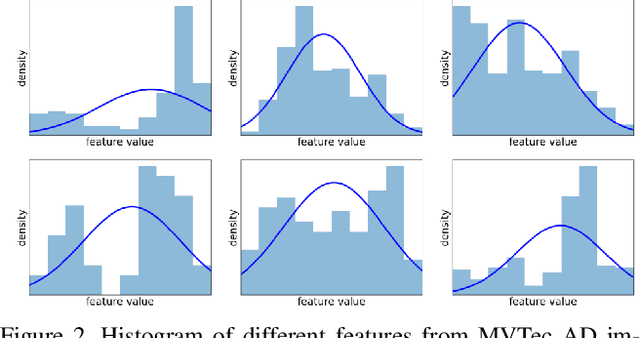
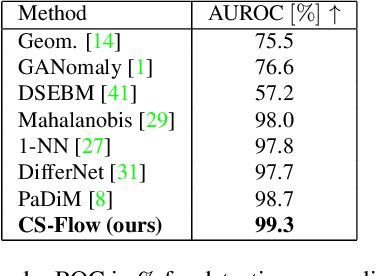
In industrial manufacturing processes, errors frequently occur at unpredictable times and in unknown manifestations. We tackle the problem of automatic defect detection without requiring any image samples of defective parts. Recent works model the distribution of defect-free image data, using either strong statistical priors or overly simplified data representations. In contrast, our approach handles fine-grained representations incorporating the global and local image context while flexibly estimating the density. To this end, we propose a novel fully convolutional cross-scale normalizing flow (CS-Flow) that jointly processes multiple feature maps of different scales. Using normalizing flows to assign meaningful likelihoods to input samples allows for efficient defect detection on image-level. Moreover, due to the preserved spatial arrangement the latent space of the normalizing flow is interpretable which enables to localize defective regions in the image. Our work sets a new state-of-the-art in image-level defect detection on the benchmark datasets Magnetic Tile Defects and MVTec AD showing a 100% AUROC on 4 out of 15 classes.
Probabilistic Monocular 3D Human Pose Estimation with Normalizing Flows
Aug 02, 2021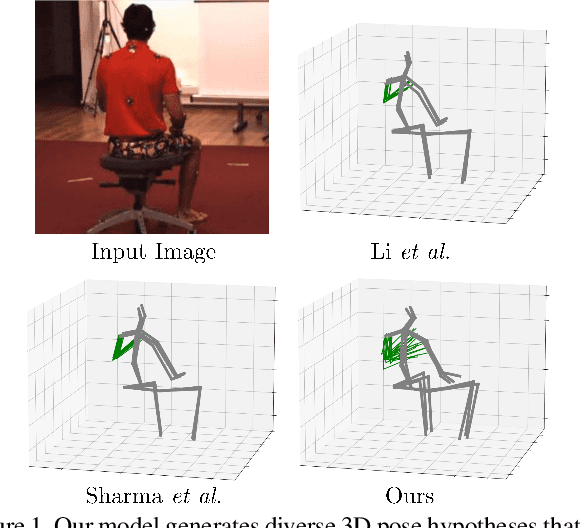
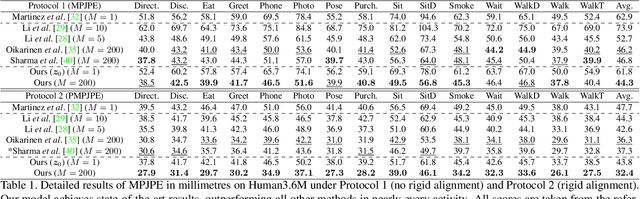
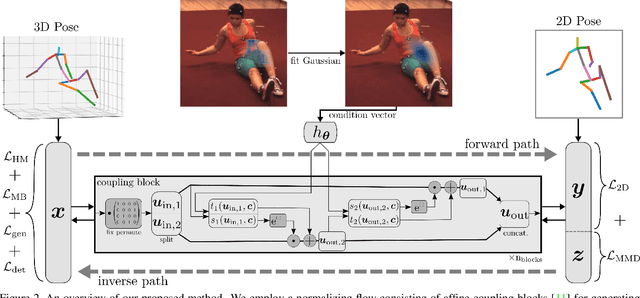

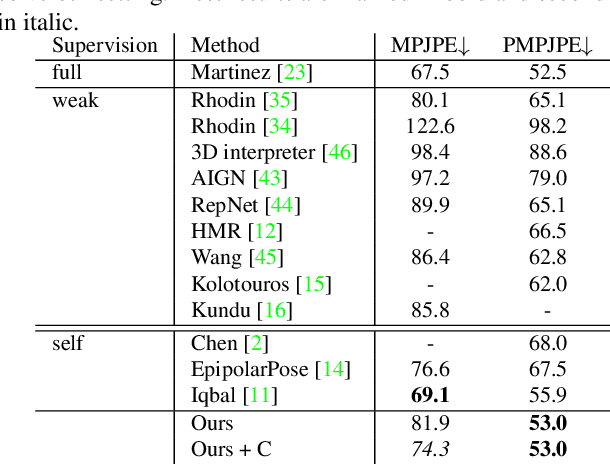
3D human pose estimation from monocular images is a highly ill-posed problem due to depth ambiguities and occlusions. Nonetheless, most existing works ignore these ambiguities and only estimate a single solution. In contrast, we generate a diverse set of hypotheses that represents the full posterior distribution of feasible 3D poses. To this end, we propose a normalizing flow based method that exploits the deterministic 3D-to-2D mapping to solve the ambiguous inverse 2D-to-3D problem. Additionally, uncertain detections and occlusions are effectively modeled by incorporating uncertainty information of the 2D detector as condition. Further keys to success are a learned 3D pose prior and a generalization of the best-of-M loss. We evaluate our approach on the two benchmark datasets Human3.6M and MPI-INF-3DHP, outperforming all comparable methods in most metrics. The implementation is available on GitHub.
CanonPose: Self-Supervised Monocular 3D Human Pose Estimation in the Wild
Nov 30, 2020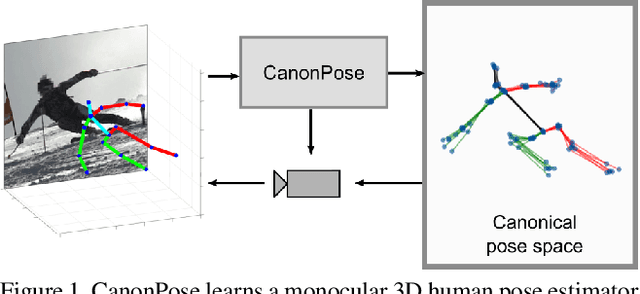
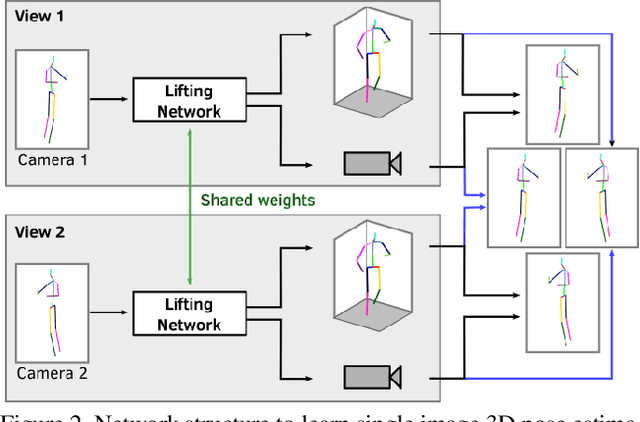
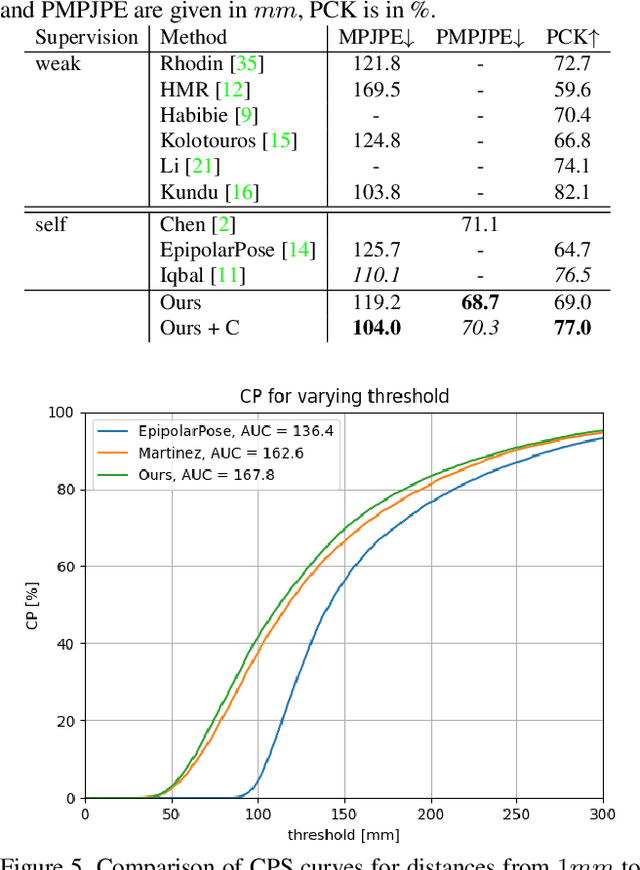
Human pose estimation from single images is a challenging problem in computer vision that requires large amounts of labeled training data to be solved accurately. Unfortunately, for many human activities (\eg outdoor sports) such training data does not exist and is hard or even impossible to acquire with traditional motion capture systems. We propose a self-supervised approach that learns a single image 3D pose estimator from unlabeled multi-view data. To this end, we exploit multi-view consistency constraints to disentangle the observed 2D pose into the underlying 3D pose and camera rotation. In contrast to most existing methods, we do not require calibrated cameras and can therefore learn from moving cameras. Nevertheless, in the case of a static camera setup, we present an optional extension to include constant relative camera rotations over multiple views into our framework. Key to the success are new, unbiased reconstruction objectives that mix information across views and training samples. The proposed approach is evaluated on two benchmark datasets (Human3.6M and MPII-INF-3DHP) and on the in-the-wild SkiPose dataset.