 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParsiNLU: A Suite of Language Understanding Challenges for Persian
Dec 11, 2020
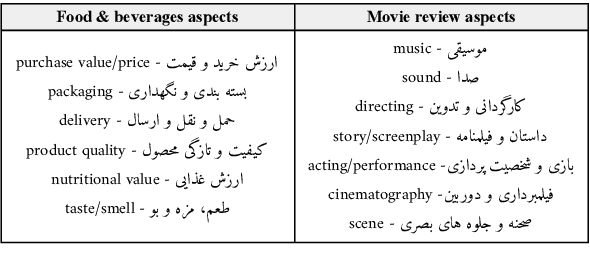
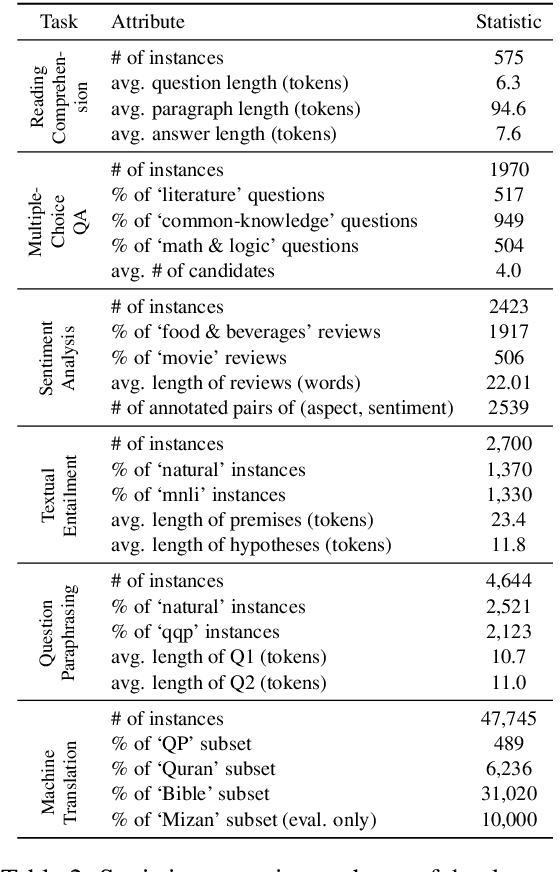
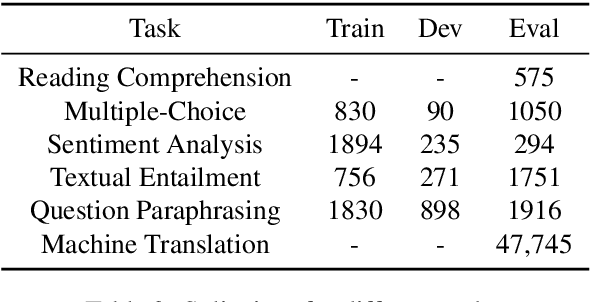
Despite the progress made in recent years in addressing natural language understanding (NLU) challenges, the majority of this progress remains to be concentrated on resource-rich languages like English. This work focuses on Persian language, one of the widely spoken languages in the world, and yet there are few NLU datasets available for this rich language. The availability of high-quality evaluation datasets is a necessity for reliable assessment of the progress on different NLU tasks and domains. We introduce ParsiNLU, the first benchmark in Persian language that includes a range of high-level tasks -- Reading Comprehension, Textual Entailment, etc. These datasets are collected in a multitude of ways, often involving manual annotations by native speakers. This results in over 14.5$k$ new instances across 6 distinct NLU tasks. Besides, we present the first results on state-of-the-art monolingual and multi-lingual pre-trained language-models on this benchmark and compare them with human performance, which provides valuable insights into our ability to tackle natural language understanding challenges in Persian. We hope ParsiNLU fosters further research and advances in Persian language understanding.
Detecting Glaucoma Using 3D Convolutional Neural Network of Raw SD-OCT Optic Nerve Scans
Oct 14, 2019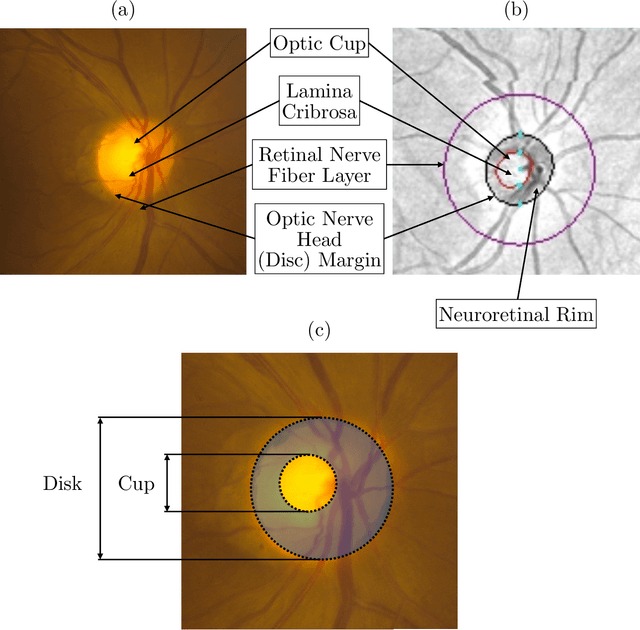

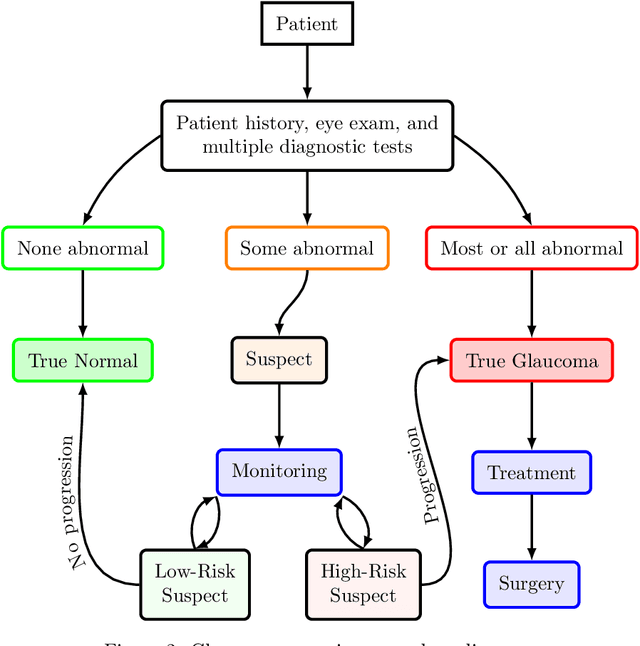

We propose developing and validating a three-dimensional (3D) deep learning system using the entire unprocessed OCT optic nerve volumes to distinguish true glaucoma from normals in order to discover any additional imaging biomarkers within the cube through saliency mapping. The algorithm has been validated against 4 additional distinct datasets from different countries using multimodal test results to define glaucoma rather than just the OCT alone. 2076 OCT (Cirrus SD-OCT, Carl Zeiss Meditec, Dublin, CA) cube scans centered over the optic nerve, of 879 eyes (390 healthy and 489 glaucoma) from 487 patients, age 18-84 years, were exported from the Glaucoma Clinic Imaging Database at the Byers Eye Institute, Stanford University, from March 2010 to December 2017. A 3D deep neural network was trained and tested on this unique OCT optic nerve head dataset from Stanford. A total of 3620 scans (all obtained using the Cirrus SD-OCT device) from 1458 eyes obtained from 4 different institutions, from United States (943 scans), Hong Kong (1625 scans), India (672 scans), and Nepal (380 scans) were used for external evaluation. The 3D deep learning system achieved an area under the receiver operation characteristics curve (AUROC) of 0.8883 in the primary Stanford test set identifying true normal from true glaucoma. The system obtained AUROCs of 0.8571, 0.7695, 0.8706, and 0.7965 on OCT cubes from United States, Hong Kong, India, and Nepal, respectively. We also analyzed the performance of the model separately for each myopia severity level as defined by spherical equivalent and the model was able to achieve F1 scores of 0.9673, 0.9491, and 0.8528 on severe, moderate, and mild myopia cases, respectively. Saliency map visualizations highlighted a significant association between the optic nerve lamina cribrosa region in the glaucoma group.
Deep Relative Attributes
Sep 13, 2016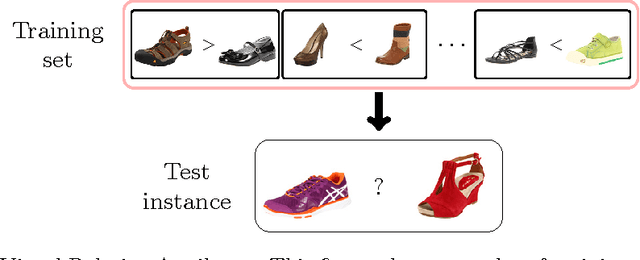
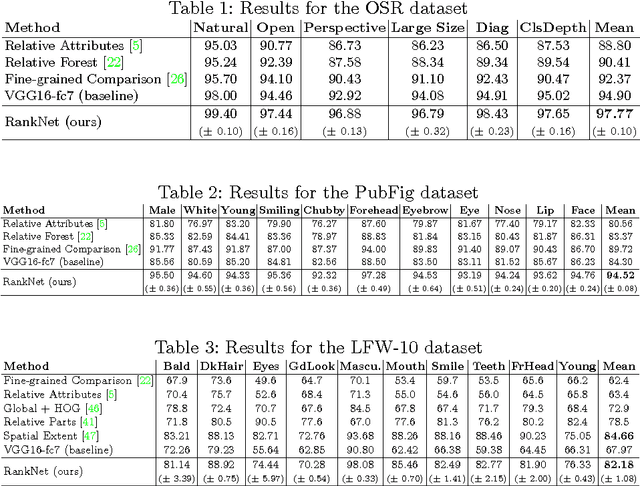
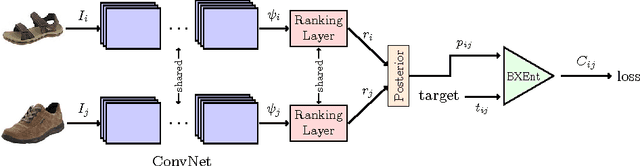
Visual attributes are great means of describing images or scenes, in a way both humans and computers understand. In order to establish a correspondence between images and to be able to compare the strength of each property between images, relative attributes were introduced. However, since their introduction, hand-crafted and engineered features were used to learn increasingly complex models for the problem of relative attributes. This limits the applicability of those methods for more realistic cases. We introduce a deep neural network architecture for the task of relative attribute prediction. A convolutional neural network (ConvNet) is adopted to learn the features by including an additional layer (ranking layer) that learns to rank the images based on these features. We adopt an appropriate ranking loss to train the whole network in an end-to-end fashion. Our proposed method outperforms the baseline and state-of-the-art methods in relative attribute prediction on various coarse and fine-grained datasets. Our qualitative results along with the visualization of the saliency maps show that the network is able to learn effective features for each specific attribute. Source code of the proposed method is available at https://github.com/yassersouri/ghiaseddin.