 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMOSE: Comprehensive Multi-Modality Online Student Engagement Dataset with High-Quality Labels
Dec 14, 2023


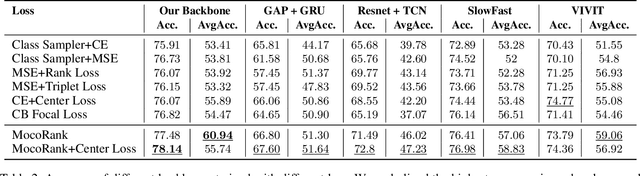
Online learning is a rapidly growing industry due to its convenience. However, a major challenge in online learning is whether students are as engaged as they are in face-to-face classes. An engagement recognition system can significantly improve the learning experience in online classes. Current challenges in engagement detection involve poor label quality in the dataset, intra-class variation, and extreme data imbalance. To address these problems, we present the CMOSE dataset, which contains a large number of data in different engagement levels and high-quality labels generated according to the psychological advice. We demonstrate the advantage of transferability by analyzing the model performance on other engagement datasets. We also developed a training mechanism, MocoRank, to handle the intra-class variation, the ordinal relationship between different classes, and the data imbalance problem. MocoRank outperforms prior engagement detection losses, achieving a 1.32% enhancement in overall accuracy and 5.05% improvement in average accuracy. We further demonstrate the effectiveness of multi-modality by conducting ablation studies on features such as pre-trained video features, high-level facial features, and audio features.
LLM-FP4: 4-Bit Floating-Point Quantized Transformers
Oct 25, 2023We propose LLM-FP4 for quantizing both weights and activations in large language models (LLMs) down to 4-bit floating-point values, in a post-training manner. Existing post-training quantization (PTQ) solutions are primarily integer-based and struggle with bit widths below 8 bits. Compared to integer quantization, floating-point (FP) quantization is more flexible and can better handle long-tail or bell-shaped distributions, and it has emerged as a default choice in many hardware platforms. One characteristic of FP quantization is that its performance largely depends on the choice of exponent bits and clipping range. In this regard, we construct a strong FP-PTQ baseline by searching for the optimal quantization parameters. Furthermore, we observe a high inter-channel variance and low intra-channel variance pattern in activation distributions, which adds activation quantization difficulty. We recognize this pattern to be consistent across a spectrum of transformer models designed for diverse tasks, such as LLMs, BERT, and Vision Transformer models. To tackle this, we propose per-channel activation quantization and show that these additional scaling factors can be reparameterized as exponential biases of weights, incurring a negligible cost. Our method, for the first time, can quantize both weights and activations in the LLaMA-13B to only 4-bit and achieves an average score of 63.1 on the common sense zero-shot reasoning tasks, which is only 5.8 lower than the full-precision model, significantly outperforming the previous state-of-the-art by 12.7 points. Code is available at: https://github.com/nbasyl/LLM-FP4.