 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhoCaL: A Multi-Modal Dataset for Category-Level Object Pose Estimation with Photometrically Challenging Objects
May 18, 2022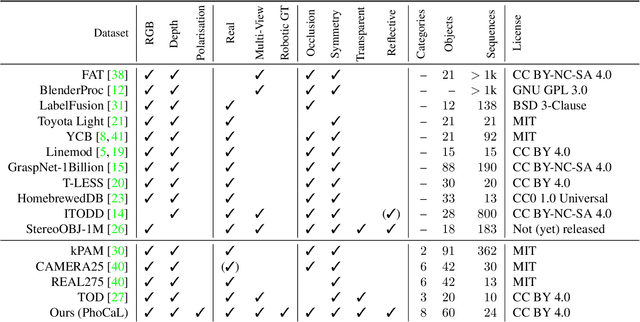



Object pose estimation is crucial for robotic applications and augmented reality. Beyond instance level 6D object pose estimation methods, estimating category-level pose and shape has become a promising trend. As such, a new research field needs to be supported by well-designed datasets. To provide a benchmark with high-quality ground truth annotations to the community, we introduce a multimodal dataset for category-level object pose estimation with photometrically challenging objects termed PhoCaL. PhoCaL comprises 60 high quality 3D models of household objects over 8 categories including highly reflective, transparent and symmetric objects. We developed a novel robot-supported multi-modal (RGB, depth, polarisation) data acquisition and annotation process. It ensures sub-millimeter accuracy of the pose for opaque textured, shiny and transparent objects, no motion blur and perfect camera synchronisation. To set a benchmark for our dataset, state-of-the-art RGB-D and monocular RGB methods are evaluated on the challenging scenes of PhoCaL.
CPS: Class-level 6D Pose and Shape Estimation From Monocular Images
Mar 13, 2020
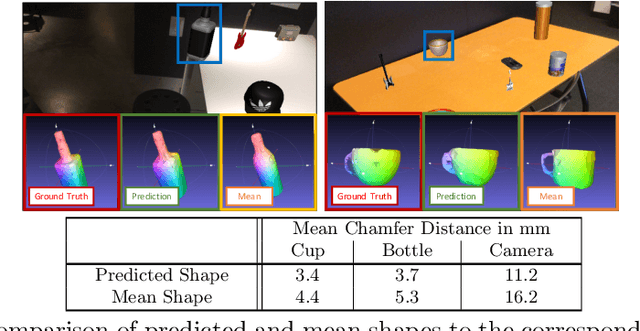
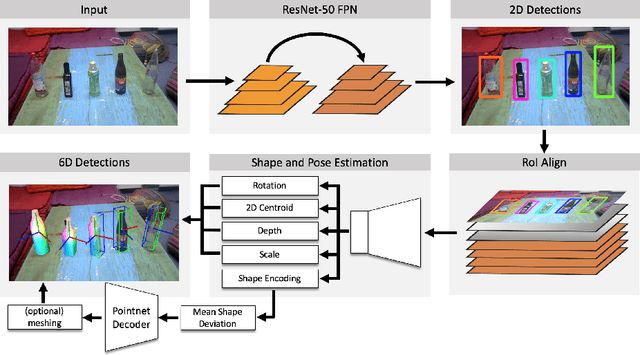
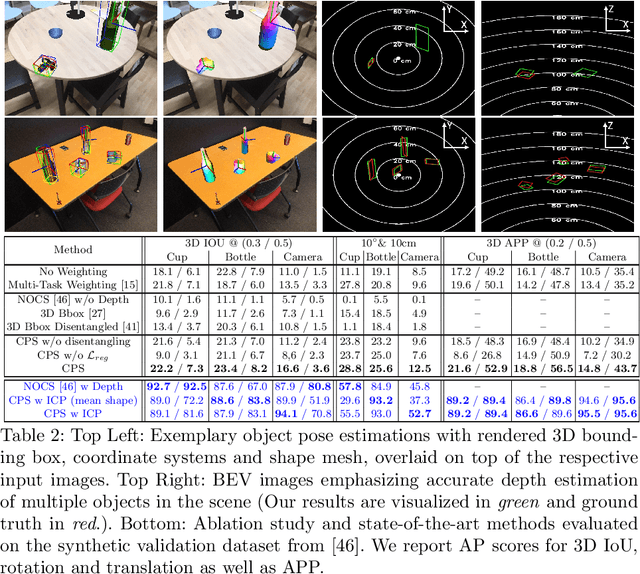
Contemporary monocular 6D pose estimation methods can only cope with a handful of object instances. This naturally limits possible applications as, for instance, robots need to work with hundreds of different objects in a real environment. In this paper, we propose the first deep learning approach for class-wise monocular 6D pose estimation, coupled with metric shape retrieval. We propose a new loss formulation which directly optimizes over all parameters, i.e. 3D orientation, translation, scale and shape at the same time. Instead of decoupling each parameter, we transform the regressed shape, in the form of a point cloud, to 3D and directly measure its metric misalignment. We experimentally demonstrate that we can retrieve precise metric point clouds from a single image, which can also be further processed for e.g. subsequent rendering. Moreover, we show that our new 3D point cloud loss outperforms all baselines and gives overall good results despite the inherent ambiguity due to monocular data.