 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIV-Bench: A Video Benchmark for Social Interaction Understanding and Reasoning
Jun 05, 2025The rich and multifaceted nature of human social interaction, encompassing multimodal cues, unobservable relations and mental states, and dynamical behavior, presents a formidable challenge for artificial intelligence. To advance research in this area, we introduce SIV-Bench, a novel video benchmark for rigorously evaluating the capabilities of Multimodal Large Language Models (MLLMs) across Social Scene Understanding (SSU), Social State Reasoning (SSR), and Social Dynamics Prediction (SDP). SIV-Bench features 2,792 video clips and 8,792 meticulously generated question-answer pairs derived from a human-LLM collaborative pipeline. It is originally collected from TikTok and YouTube, covering a wide range of video genres, presentation styles, and linguistic and cultural backgrounds. It also includes a dedicated setup for analyzing the impact of different textual cues-original on-screen text, added dialogue, or no text. Our comprehensive experiments on leading MLLMs reveal that while models adeptly handle SSU, they significantly struggle with SSR and SDP, where Relation Inference (RI) is an acute bottleneck, as further examined in our analysis. Our study also confirms the critical role of transcribed dialogue in aiding comprehension of complex social interactions. By systematically identifying current MLLMs' strengths and limitations, SIV-Bench offers crucial insights to steer the development of more socially intelligent AI. The dataset and code are available at https://kfq20.github.io/sivbench/.
AdaSociety: An Adaptive Environment with Social Structures for Multi-Agent Decision-Making
Nov 06, 2024Traditional interactive environments limit agents' intelligence growth with fixed tasks. Recently, single-agent environments address this by generating new tasks based on agent actions, enhancing task diversity. We consider the decision-making problem in multi-agent settings, where tasks are further influenced by social connections, affecting rewards and information access. However, existing multi-agent environments lack a combination of adaptive physical surroundings and social connections, hindering the learning of intelligent behaviors. To address this, we introduce AdaSociety, a customizable multi-agent environment featuring expanding state and action spaces, alongside explicit and alterable social structures. As agents progress, the environment adaptively generates new tasks with social structures for agents to undertake. In AdaSociety, we develop three mini-games showcasing distinct social structures and tasks. Initial results demonstrate that specific social structures can promote both individual and collective benefits, though current reinforcement learning and LLM-based algorithms show limited effectiveness in leveraging social structures to enhance performance. Overall, AdaSociety serves as a valuable research platform for exploring intelligence in diverse physical and social settings. The code is available at https://github.com/bigai-ai/AdaSociety.
Learning to Balance Altruism and Self-interest Based on Empathy in Mixed-Motive Games
Oct 10, 2024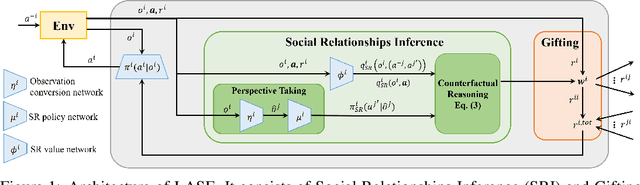



Real-world multi-agent scenarios often involve mixed motives, demanding altruistic agents capable of self-protection against potential exploitation. However, existing approaches often struggle to achieve both objectives. In this paper, based on that empathic responses are modulated by inferred social relationships between agents, we propose LASE Learning to balance Altruism and Self-interest based on Empathy), a distributed multi-agent reinforcement learning algorithm that fosters altruistic cooperation through gifting while avoiding exploitation by other agents in mixed-motive games. LASE allocates a portion of its rewards to co-players as gifts, with this allocation adapting dynamically based on the social relationship -- a metric evaluating the friendliness of co-players estimated by counterfactual reasoning. In particular, social relationship measures each co-player by comparing the estimated $Q$-function of current joint action to a counterfactual baseline which marginalizes the co-player's action, with its action distribution inferred by a perspective-taking module. Comprehensive experiments are performed in spatially and temporally extended mixed-motive games, demonstrating LASE's ability to promote group collaboration without compromising fairness and its capacity to adapt policies to various types of interactive co-players.
Efficient Adaptation in Mixed-Motive Environments via Hierarchical Opponent Modeling and Planning
Jun 12, 2024

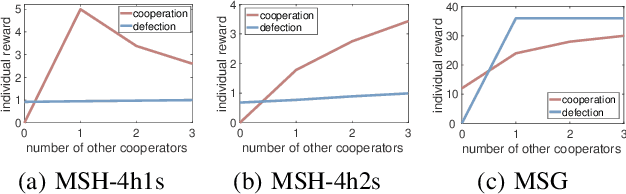
Despite the recent successes of multi-agent reinforcement learning (MARL) algorithms, efficiently adapting to co-players in mixed-motive environments remains a significant challenge. One feasible approach is to hierarchically model co-players' behavior based on inferring their characteristics. However, these methods often encounter difficulties in efficient reasoning and utilization of inferred information. To address these issues, we propose Hierarchical Opponent modeling and Planning (HOP), a novel multi-agent decision-making algorithm that enables few-shot adaptation to unseen policies in mixed-motive environments. HOP is hierarchically composed of two modules: an opponent modeling module that infers others' goals and learns corresponding goal-conditioned policies, and a planning module that employs Monte Carlo Tree Search (MCTS) to identify the best response. Our approach improves efficiency by updating beliefs about others' goals both across and within episodes and by using information from the opponent modeling module to guide planning. Experimental results demonstrate that in mixed-motive environments, HOP exhibits superior few-shot adaptation capabilities when interacting with various unseen agents, and excels in self-play scenarios. Furthermore, the emergence of social intelligence during our experiments underscores the potential of our approach in complex multi-agent environments.