 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking the Power of Critical Factors for 3D Visual Geometry Estimation
Apr 23, 2026Feed-forward visual geometry estimation has recently made rapid progress. However, an important gap remains: multi-frame models usually produce better cross-frame consistency, yet they often underperform strong per-frame methods on single-frame accuracy. This observation motivates our systematic investigation into the critical factors driving model performance through rigorous ablation studies, which reveals several key insights: 1) Scaling up data diversity and quality unlocks further performance gains even in state-of-the-art visual geometry estimation methods; 2) Commonly adopted confidence-aware loss and gradient-based loss mechanisms may unintentionally hinder performance; 3) Joint supervision through both per-sequence and per-frame alignment improves results, while local region alignment surprisingly degrades performance. Furthermore, we introduce two enhancements to integrate the advantages of optimization-based methods and high-resolution inputs: a consistency loss function that enforces alignment between depth maps, camera parameters, and point maps, and an efficient architectural design that leverages high-resolution information. We integrate these designs into CARVE, a resolution-enhanced model for feed-forward visual geometry estimation. Experiments on point cloud reconstruction, video depth estimation, and camera pose/intrinsic estimation show that CARVE achieves strong and robust performance across diverse benchmarks.
GeoBench: Benchmarking and Analyzing Monocular Geometry Estimation Models
Jun 18, 2024



Recent advances in discriminative and generative pretraining have yielded geometry estimation models with strong generalization capabilities. While discriminative monocular geometry estimation methods rely on large-scale fine-tuning data to achieve zero-shot generalization, several generative-based paradigms show the potential of achieving impressive generalization performance on unseen scenes by leveraging pre-trained diffusion models and fine-tuning on even a small scale of synthetic training data. Frustratingly, these models are trained with different recipes on different datasets, making it hard to find out the critical factors that determine the evaluation performance. Besides, current geometry evaluation benchmarks have two main drawbacks that may prevent the development of the field, i.e., limited scene diversity and unfavorable label quality. To resolve the above issues, (1) we build fair and strong baselines in a unified codebase for evaluating and analyzing the geometry estimation models; (2) we evaluate monocular geometry estimators on more challenging benchmarks for geometry estimation task with diverse scenes and high-quality annotations. Our results reveal that pre-trained using large data, discriminative models such as DINOv2, can outperform generative counterparts with a small amount of high-quality synthetic data under the same training configuration, which suggests that fine-tuning data quality is a more important factor than the data scale and model architecture. Our observation also raises a question: if simply fine-tuning a general vision model such as DINOv2 using a small amount of synthetic depth data produces SOTA results, do we really need complex generative models for depth estimation? We believe this work can propel advancements in geometry estimation tasks as well as a wide range of downstream applications.
Comment on All-optical machine learning using diffractive deep neural networks
Sep 22, 2018Lin et al. (Reports, 7 September 2018, p. 1004) reported a remarkable proposal that employs a passive, strictly linear optical setup to perform pattern classifications. But interpreting the multilayer diffractive setup as a deep neural network and advocating it as an all-optical deep learning framework are not well justified and represent a mischaracterization of the system by overlooking its defining characteristics of perfect linearity and strict passivity.
Learning Temporal Structures of Random Patterns
May 28, 2018

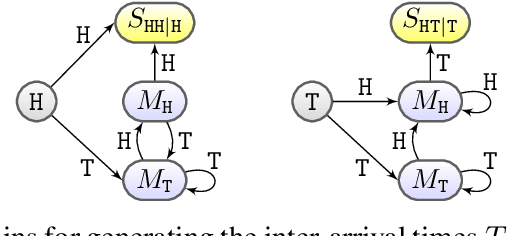
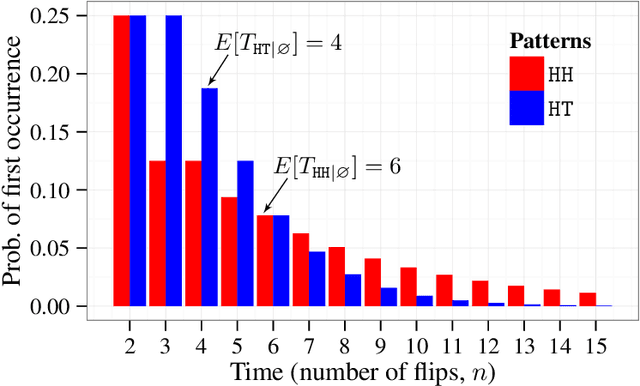
A cornerstone of human statistical learning is the ability to extract temporal regularities / patterns from random sequences. Here we present a method of computing pattern time statistics with generating functions for first-order Markov trials and independent Bernoulli trials. We show that the pattern time statistics cover a wide range of measurements commonly used in existing studies of both human and machine learning of stochastic processes, including probability of alternation, temporal correlation between pattern events, and related variance / risk measures. Moreover, we show that recurrent processing and event segmentation by pattern overlap may provide a coherent explanation for the sensitivity of the human brain to the rich statistics and the latent structures in the learning environment.