Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictions For Pre-training Language Models
Paper and Code
Nov 18, 2020

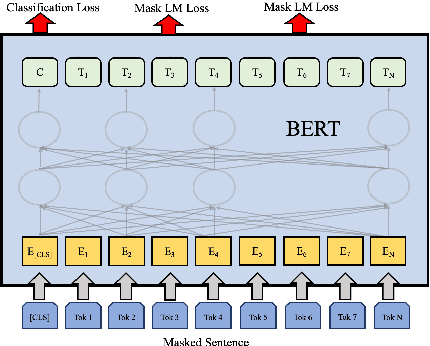

Language model pre-training has proven to be useful in many language understanding tasks. In this paper, we investigate whether it is still helpful to add the specific task's loss in pre-training step. In industry NLP applications, we have large amount of data produced by users. We use the fine-tuned model to give the user-generated unlabeled data a pseudo-label. Then we use the pseudo-label for the task-specific loss and masked language model loss to pre-train. The experiment shows that using the fine-tuned model's predictions for pseudo-labeled pre-training offers further gains in the downstream task. The improvement of our method is stable and remarkable.
* 5 pages
View paper on