 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContent Enhanced BERT-based Text-to-SQL Generation
Nov 27, 2019


We present a simple methods to leverage the table content for the BERT-based model to solve the text-to-SQL problem. Based on the observation that some of the table content match some words in question string and some of the table header also match some words in question string, we encode two addition feature vector for the deep model. Our methods also benefit the model inference in testing time as the tables are almost the same in training and testing time. We test our model on the WikiSQL dataset and outperform the BERT-based baseline by 3.7% in logic form and 3.7% in execution accuracy and achieve state-of-the-art.
Revisiting Semantic Representation and Tree Search for Similar Question Retrieval
Sep 06, 2019


This paper studies the performances of BERT combined with tree structure in short sentence ranking task. In retrieval-based question answering system, we retrieve the most similar question of the query question by ranking all the questions in datasets. If we want to rank all the sentences by neural rankers, we need to score all the sentence pairs. However it consumes large amount of time. So we design a specific tree for searching and combine deep model to solve this problem. We fine-tune BERT on the training data to get semantic vector or sentence embeddings on the test data. We use all the sentence embeddings of test data to build our tree based on k-means and do beam search at predicting time when given a sentence as query. We do the experiments on the semantic textual similarity dataset, Quora Question Pairs, and process the dataset for sentence ranking. Experimental results show that our methods outperform the strong baseline. Our tree accelerate the predicting speed by 500%-1000% without losing too much ranking accuracy.
Using Database Rule for Weak Supervised Text-to-SQL Generation
Jul 31, 2019



We present a simple way to do the task of text-to-SQL problem with weak supervision. We call it Rule-SQL. Given the question and the answer from the database table without the SQL logic form, Rule-SQL use the rules based on table column names and question string for the SQL exploration first and then use the explored SQL for supervised training. We design several rules for reducing the exploration search space. For the deep model, we leverage BERT for the representation layer and separate the model to SELECT, AGG and WHERE parts. The experiment result on WikiSQL outperforms the strong baseline of full supervision and is comparable to the start-of-the-art weak supervised mothods.
Table2answer: Read the database and answer without SQL
Mar 11, 2019


Semantic parsing is the task of mapping natural language to logic form. In question answering, semantic parsing can be used to map the question to logic form and execute the logic form to get the answer. One key problem for semantic parsing is the hard label work. We study this problem in another way: we do not use the logic form any more. Instead we only use the schema and answer info. We think that the logic form step can be injected into the deep model. The reason why we think removing the logic form step is possible is that human can do the task without explicit logic form. We use BERT-based model and do the experiment in the WikiSQL dataset, which is a large natural language to SQL dataset. Our experimental evaluations that show that our model can achieves the baseline results in WikiSQL dataset.
Bidirectional Attention for SQL Generation
Jun 21, 2018
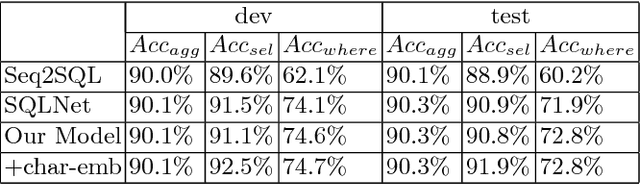


Generating structural query language (SQL) queries from natural language is a long-standing open problem. Answering a natural language question about a database table requires modeling complex interactions between the columns of the table and the question. In this paper, we apply the synthesizing approach to solve this problem. Based on the structure of SQL queries, we break down the model to three sub-modules and design specific deep neural networks for each of them. Taking inspiration from the similar machine reading task, we employ the bidirectional attention mechanisms and character-level embedding with convolutional neural networks (CNNs) to improve the result. Experimental evaluations show that our model achieves the state-of-the-art results in WikiSQL dataset.
Image classification based on support vector machine and the fusion of complementary features
Nov 05, 2015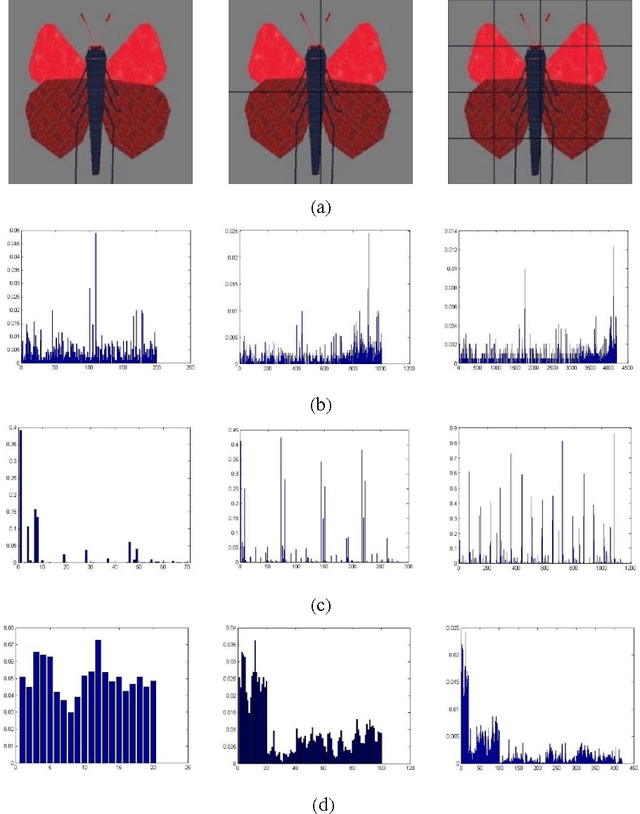
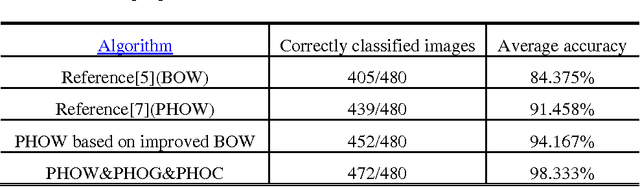
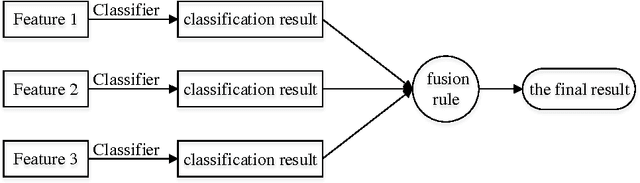
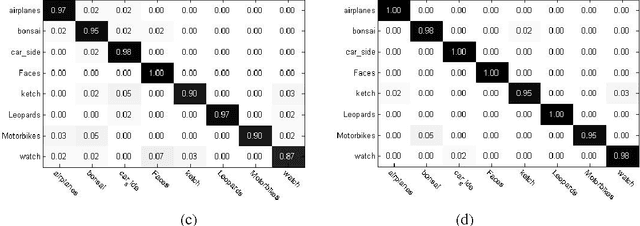
Image Classification based on BOW (Bag-of-words) has broad application prospect in pattern recognition field but the shortcomings are existed because of single feature and low classification accuracy. To this end we combine three ingredients: (i) Three features with functions of mutual complementation are adopted to describe the images, including PHOW (Pyramid Histogram of Words), PHOC (Pyramid Histogram of Color) and PHOG (Pyramid Histogram of Orientated Gradients). (ii) The improvement of traditional BOW model is presented by using dense sample and an improved K-means clustering method for constructing the visual dictionary. (iii) An adaptive feature-weight adjusted image categorization algorithm based on the SVM and the fusion of multiple features is adopted. Experiments carried out on Caltech 101 database confirm the validity of the proposed approach. From the experimental results can be seen that the classification accuracy rate of the proposed method is improved by 7%-17% higher than that of the traditional BOW methods. This algorithm makes full use of global, local and spatial information and has significant improvements to the classification accuracy.