 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Numerical Reasoning Question Answering System with Fine-grained Retriever and the Ensemble of Multiple Generators for FinQA
Jun 17, 2022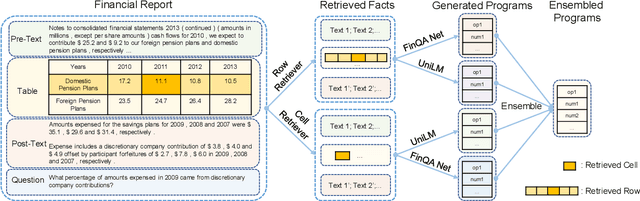


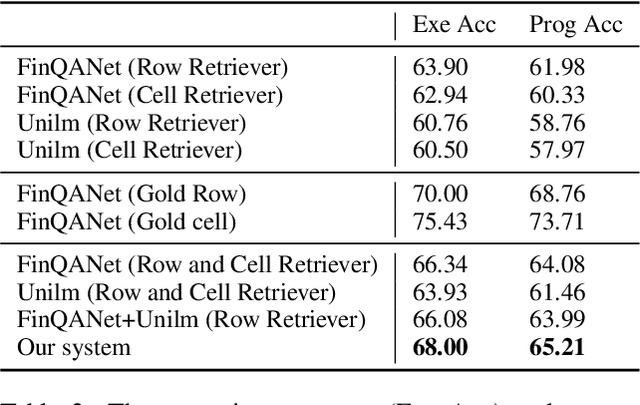
The numerical reasoning in the financial domain -- performing quantitative analysis and summarizing the information from financial reports -- can greatly increase business efficiency and reduce costs of billions of dollars. Here, we propose a numerical reasoning question answering system to answer numerical reasoning questions among financial text and table data sources, consisting of a retriever module, a generator module, and an ensemble module. Specifically, in the retriever module, in addition to retrieving the whole row data, we innovatively design a cell retriever that retrieves the gold cells to avoid bringing unrelated and similar cells in the same row to the inputs of the generator module. In the generator module, we utilize multiple generators to produce programs, which are operation steps to answer the question. Finally, in the ensemble module, we integrate multiple programs to choose the best program as the output of our system. In the final private test set in FinQA Competition, our system obtains 69.79 execution accuracy.
Modeling Users' Contextualized Page-wise Feedback for Click-Through Rate Prediction in E-commerce Search
Mar 29, 2022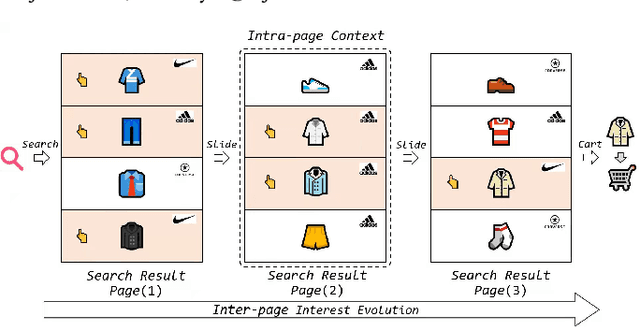

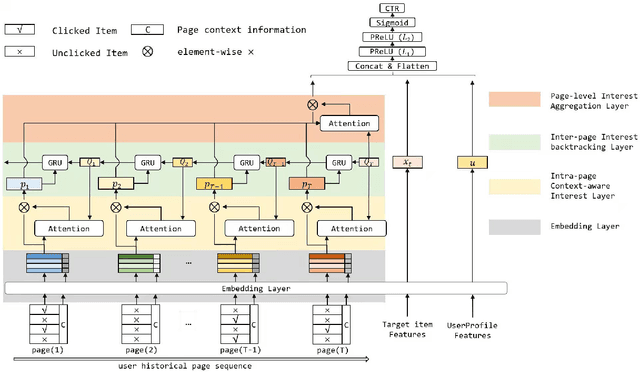
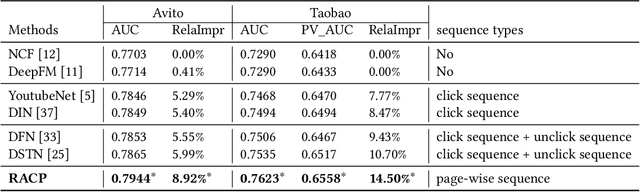
Modeling user's historical feedback is essential for Click-Through Rate Prediction in personalized search and recommendation. Existing methods usually only model users' positive feedback information such as click sequences which neglects the context information of the feedback. In this paper, we propose a new perspective for context-aware users' behavior modeling by including the whole page-wisely exposed products and the corresponding feedback as contextualized page-wise feedback sequence. The intra-page context information and inter-page interest evolution can be captured to learn more specific user preference. We design a novel neural ranking model RACP(i.e., Recurrent Attention over Contextualized Page sequence), which utilizes page-context aware attention to model the intra-page context. A recurrent attention process is used to model the cross-page interest convergence evolution as denoising the interest in the previous pages. Experiments on public and real-world industrial datasets verify our model's effectiveness.
Synonym Knowledge Enhanced Reader for Chinese Idiom Reading Comprehension
Nov 09, 2020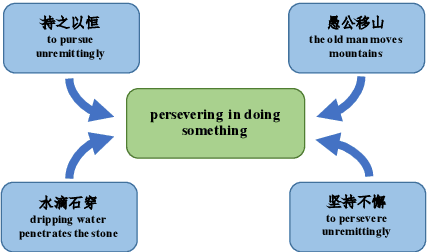

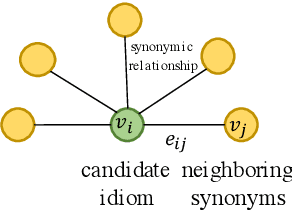
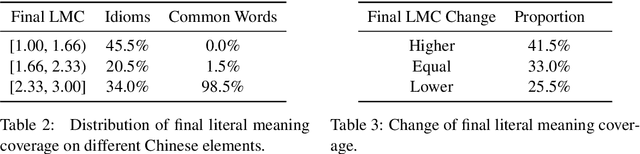
Machine reading comprehension (MRC) is the task that asks a machine to answer questions based on a given context. For Chinese MRC, due to the non-literal and non-compositional semantic characteristics, Chinese idioms pose unique challenges for machines to understand. Previous studies tend to treat idioms separately without fully exploiting the relationship among them. In this paper, we first define the concept of literal meaning coverage to measure the consistency between semantics and literal meanings for Chinese idioms. With the definition, we prove that the literal meanings of many idioms are far from their semantics, and we also verify that the synonymic relationship can mitigate this inconsistency, which would be beneficial for idiom comprehension. Furthermore, to fully utilize the synonymic relationship, we propose the synonym knowledge enhanced reader. Specifically, for each idiom, we first construct a synonym graph according to the annotations from a high-quality synonym dictionary or the cosine similarity between the pre-trained idiom embeddings and then incorporate the graph attention network and gate mechanism to encode the graph. Experimental results on ChID, a large-scale Chinese idiom reading comprehension dataset, show that our model achieves state-of-the-art performance.
Latent Opinions Transfer Network for Target-Oriented Opinion Words Extraction
Jan 07, 2020

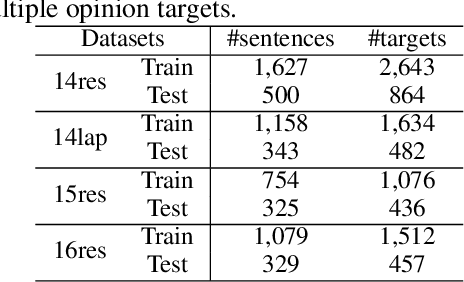

Target-oriented opinion words extraction (TOWE) is a new subtask of ABSA, which aims to extract the corresponding opinion words for a given opinion target in a sentence. Recently, neural network methods have been applied to this task and achieve promising results. However, the difficulty of annotation causes the datasets of TOWE to be insufficient, which heavily limits the performance of neural models. By contrast, abundant review sentiment classification data are easily available at online review sites. These reviews contain substantial latent opinions information and semantic patterns. In this paper, we propose a novel model to transfer these opinions knowledge from resource-rich review sentiment classification datasets to low-resource task TOWE. To address the challenges in the transfer process, we design an effective transformation method to obtain latent opinions, then integrate them into TOWE. Extensive experimental results show that our model achieves better performance compared to other state-of-the-art methods and significantly outperforms the base model without transferring opinions knowledge. Further analysis validates the effectiveness of our model.
Multi-Perspective Inferrer: Reasoning Sentences Relationship from Holistic Perspective
Nov 09, 2019
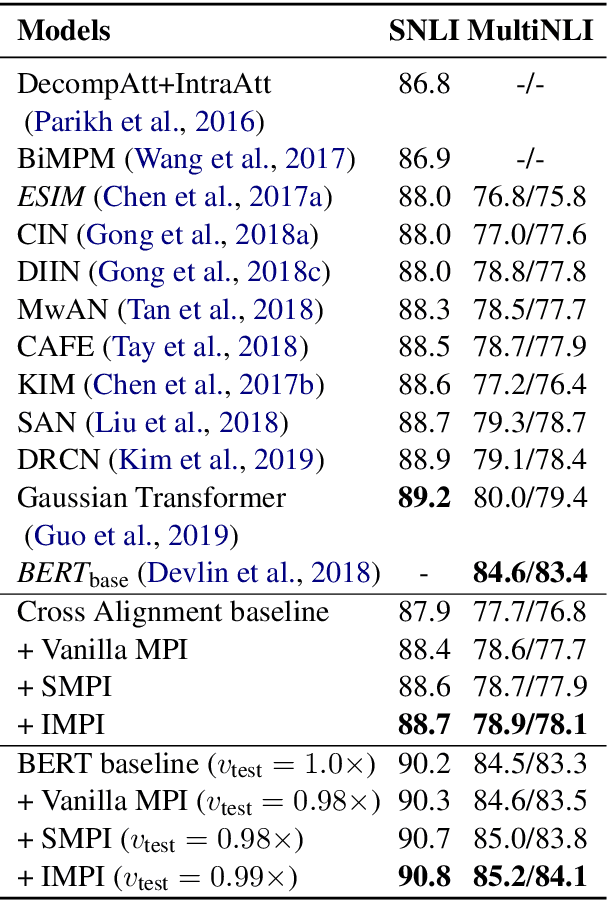
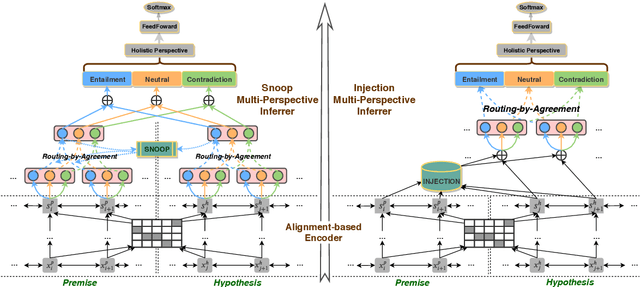
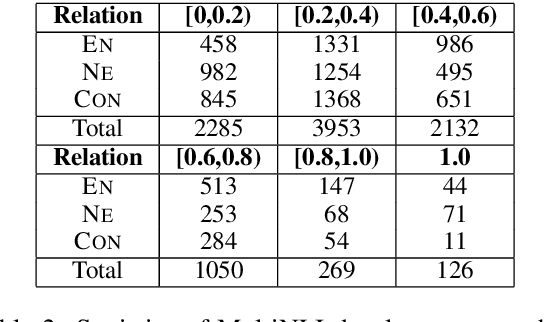
Natural Language Inference (NLI) aims to determine the logic relationships (i.e., entailment, neutral and contradiction) between a pair of premise and hypothesis. Recently, the alignment mechanism effectively helps NLI by capturing the aligned parts (i.e., the similar segments) in the sentence pairs, which imply the perspective of entailment and contradiction. However, these aligned parts will sometimes mislead the judgment of neutral relations. Intuitively, NLI should rely more on multiple perspectives to form a holistic view to eliminate bias. In this paper, we propose the Multi-Perspective Inferrer (MPI), a novel NLI model that reasons relationships from multiple perspectives associated with the three relationships. The MPI determines the perspectives of different parts of the sentences via a routing-by-agreement policy and makes the final decision from a holistic view. Additionally, we introduce an auxiliary supervised signal to ensure the MPI to learn the expected perspectives. Experiments on SNLI and MultiNLI show that 1) the MPI achieves substantial improvements on the base model, which verifies the motivation of multi-perspective inference; 2) visualized evidence verifies that the MPI learns highly interpretable perspectives as expected; 3) more importantly, the MPI is architecture-free and compatible with the powerful BERT.
Dynamic Past and Future for Neural Machine Translation
Apr 21, 2019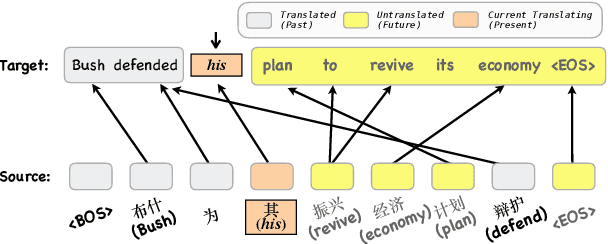
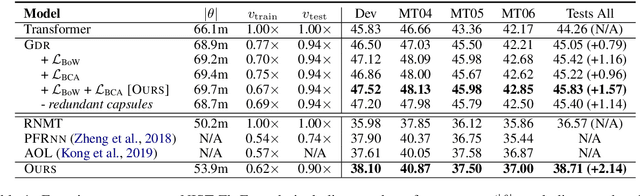
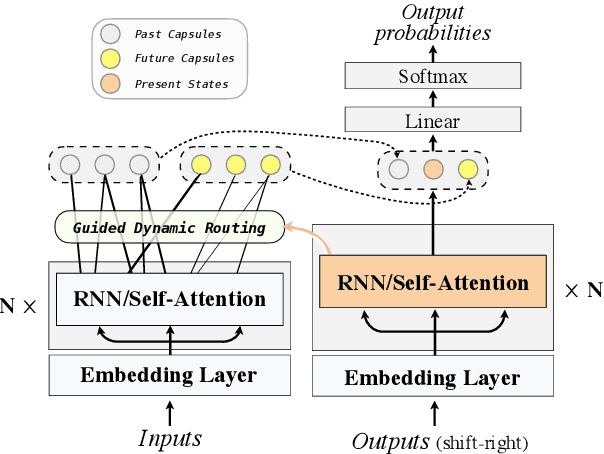
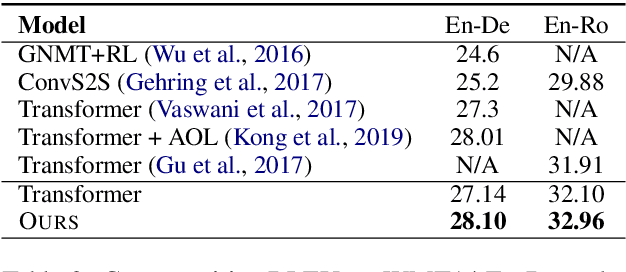
Previous studies have shown that neural machine translation (NMT) models can benefit from modeling translated (Past) and un-translated (Future) source contents as recurrent states (Zheng et al., 2018). However, the recurrent process is less interpretable. In this paper, we propose to model Past and Future by Capsule Network (Hinton et al.,2011), which provides an explicit separation of source words into groups of Past and Future by the process of parts-to-wholes assignment. The assignment is learned with a novel variant of routing-by-agreement mechanism (Sabour et al., 2017), namely Guided Dynamic Routing, in which what to translate at current decoding step guides the routing process to assign each source word to its associated group represented by a capsule, and to refine the representation of the capsule dynamically and iteratively. Experiments on translation tasks of three language pairs show that our model achieves substantial improvements over both RNMT and Transformer. Extensive analysis further verifies that our method does recognize translated and untranslated content as expected, and produces better and more adequate translations.
Learning to Discriminate Noises for Incorporating External Information in Neural Machine Translation
Oct 24, 2018
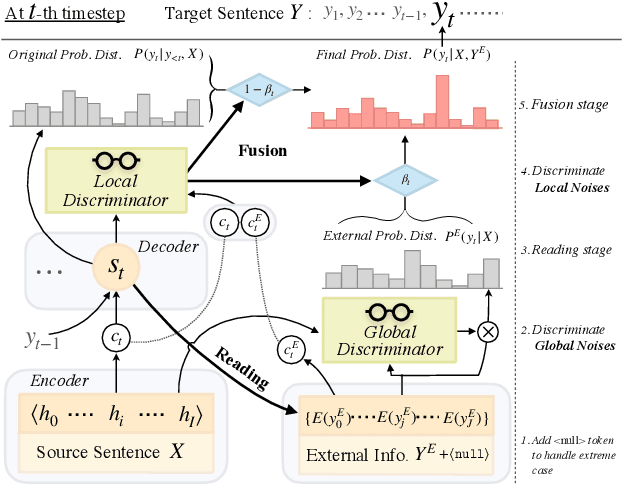
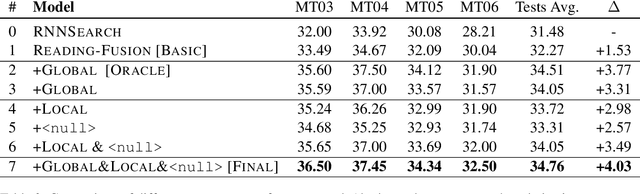
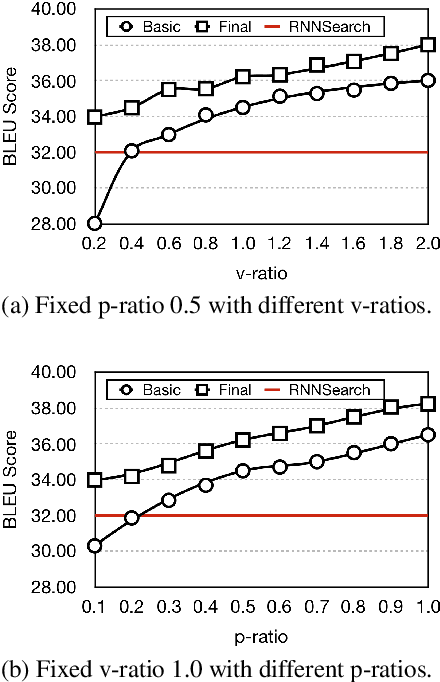
Previous studies show that incorporating external information could improve the translation quality of Neural Machine Translation (NMT) systems. However, these methods will inevitably suffer from the noises in the external information, which may severely reduce the benefit. We argue that there exist two kinds of noise in this external information, i.e. global noise and local noise, which affect the translation of the whole sentence and for some specific words, respectively. To tackle the problem, this study pays special attention to the discrimination of noises during the incorporation. We propose a general framework with two separate word discriminators for the global and local noises, respectively, so that the external information could be better leveraged. Empirical evaluation shows that being trained by the dataset sampled from the original parallel corpus without any extra labeled data or annotation, our model could make better use of external information in different real-world scenarios, language pairs, and neural architectures, leading to significant improvements over the original translation.
Improving Review Representations with User Attention and Product Attention for Sentiment Classification
Jan 24, 2018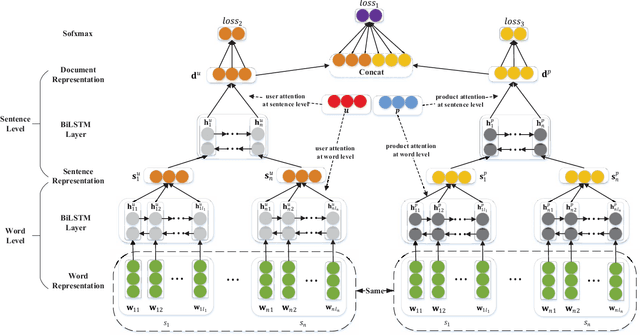

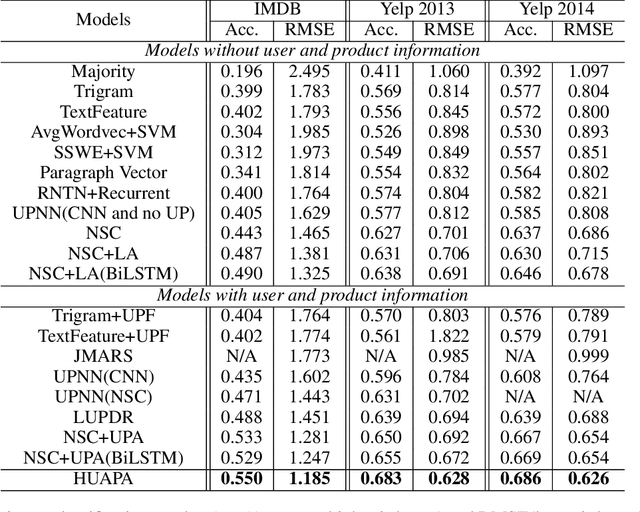
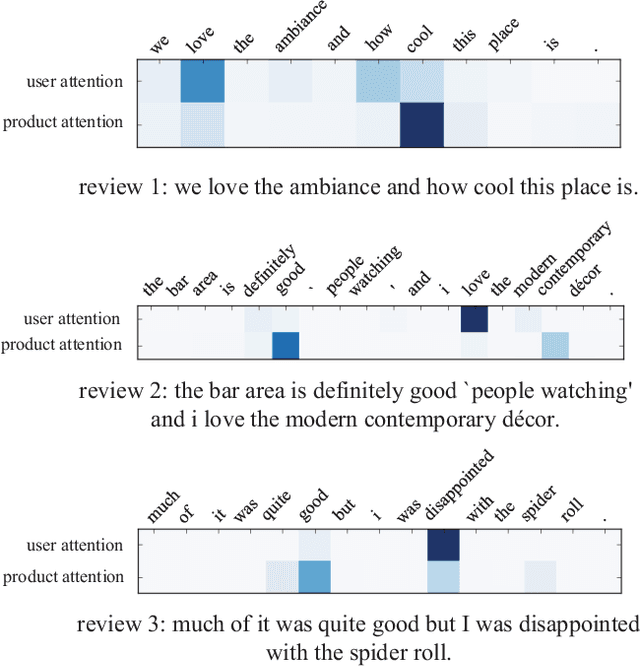
Neural network methods have achieved great success in reviews sentiment classification. Recently, some works achieved improvement by incorporating user and product information to generate a review representation. However, in reviews, we observe that some words or sentences show strong user's preference, and some others tend to indicate product's characteristic. The two kinds of information play different roles in determining the sentiment label of a review. Therefore, it is not reasonable to encode user and product information together into one representation. In this paper, we propose a novel framework to encode user and product information. Firstly, we apply two individual hierarchical neural networks to generate two representations, with user attention or with product attention. Then, we design a combined strategy to make full use of the two representations for training and final prediction. The experimental results show that our model obviously outperforms other state-of-the-art methods on IMDB and Yelp datasets. Through the visualization of attention over words related to user or product, we validate our observation mentioned above.
Dynamic Oracle for Neural Machine Translation in Decoding Phase
Oct 16, 2017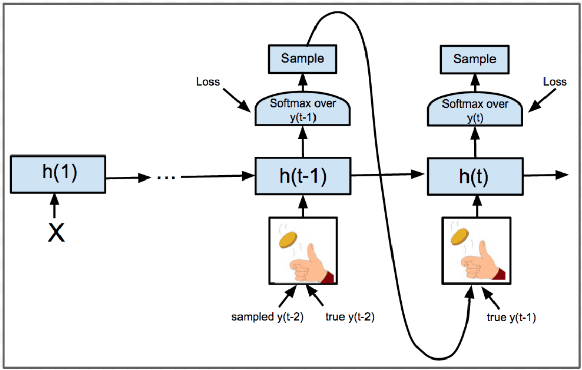
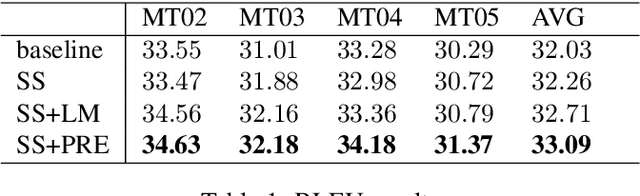

The past several years have witnessed the rapid progress of end-to-end Neural Machine Translation (NMT). However, there exists discrepancy between training and inference in NMT when decoding, which may lead to serious problems since the model might be in a part of the state space it has never seen during training. To address the issue, Scheduled Sampling has been proposed. However, there are certain limitations in Scheduled Sampling and we propose two dynamic oracle-based methods to improve it. We manage to mitigate the discrepancy by changing the training process towards a less guided scheme and meanwhile aggregating the oracle's demonstrations. Experimental results show that the proposed approaches improve translation quality over standard NMT system.
Going Wider: Recurrent Neural Network With Parallel Cells
May 03, 2017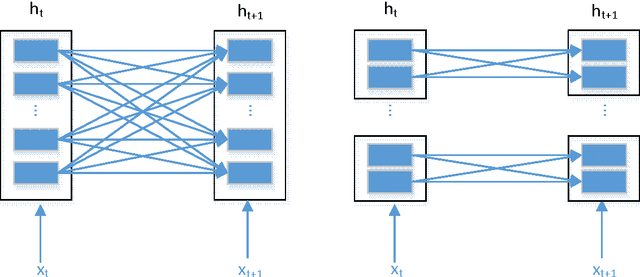
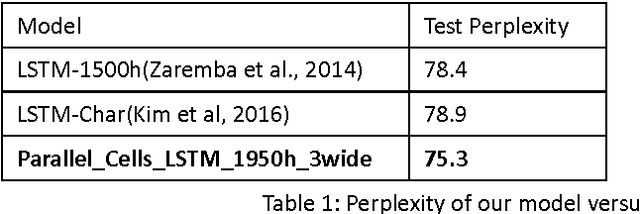
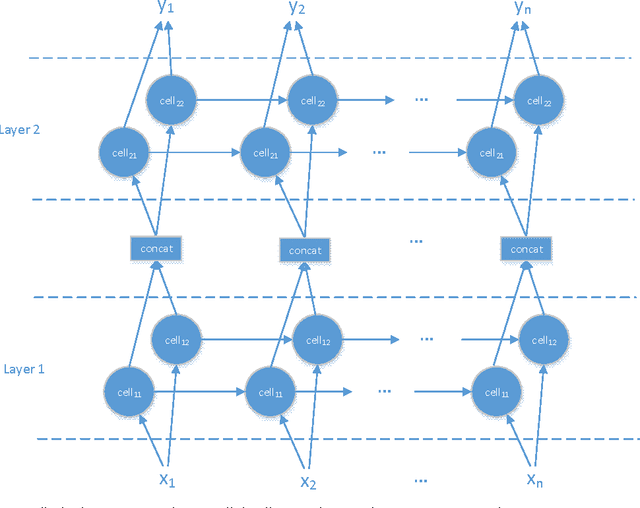
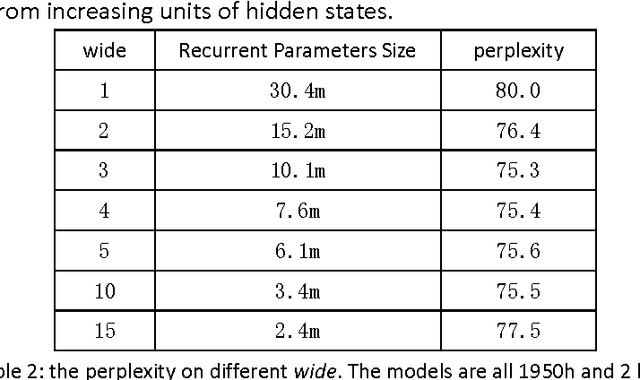
Recurrent Neural Network (RNN) has been widely applied for sequence modeling. In RNN, the hidden states at current step are full connected to those at previous step, thus the influence from less related features at previous step may potentially decrease model's learning ability. We propose a simple technique called parallel cells (PCs) to enhance the learning ability of Recurrent Neural Network (RNN). In each layer, we run multiple small RNN cells rather than one single large cell. In this paper, we evaluate PCs on 2 tasks. On language modeling task on PTB (Penn Tree Bank), our model outperforms state of art models by decreasing perplexity from 78.6 to 75.3. On Chinese-English translation task, our model increases BLEU score for 0.39 points than baseline model.