 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Users' Contextualized Page-wise Feedback for Click-Through Rate Prediction in E-commerce Search
Mar 29, 2022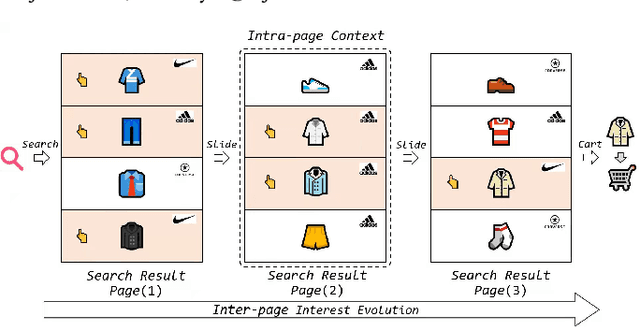

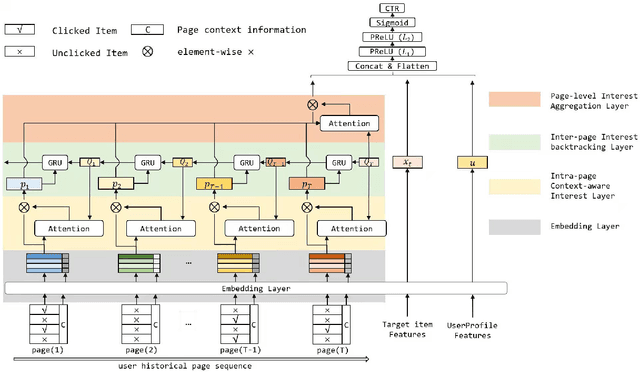
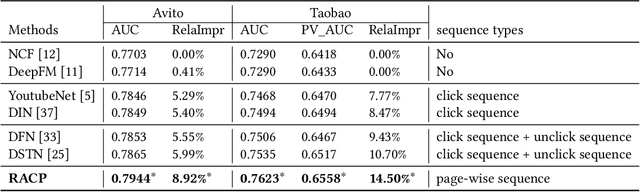
Modeling user's historical feedback is essential for Click-Through Rate Prediction in personalized search and recommendation. Existing methods usually only model users' positive feedback information such as click sequences which neglects the context information of the feedback. In this paper, we propose a new perspective for context-aware users' behavior modeling by including the whole page-wisely exposed products and the corresponding feedback as contextualized page-wise feedback sequence. The intra-page context information and inter-page interest evolution can be captured to learn more specific user preference. We design a novel neural ranking model RACP(i.e., Recurrent Attention over Contextualized Page sequence), which utilizes page-context aware attention to model the intra-page context. A recurrent attention process is used to model the cross-page interest convergence evolution as denoising the interest in the previous pages. Experiments on public and real-world industrial datasets verify our model's effectiveness.
Knowledge-enhanced Session-based Recommendation with Temporal Transformer
Dec 16, 2021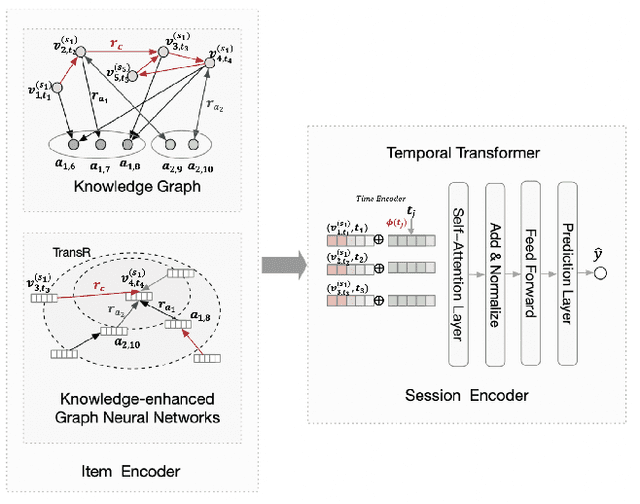
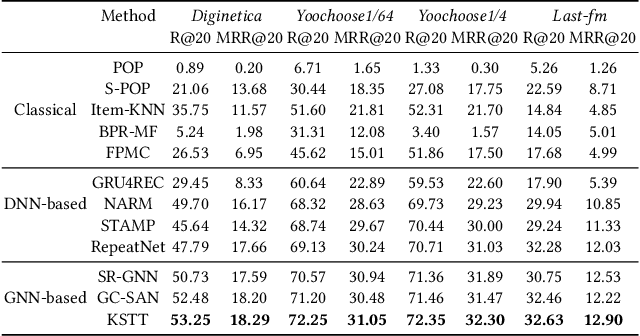
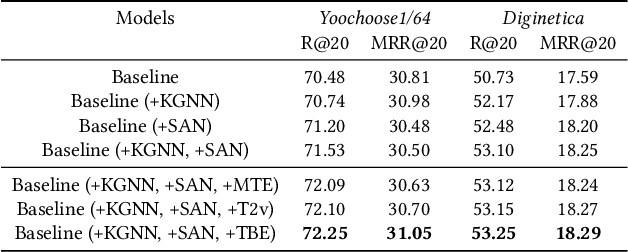
Recent research has achieved impressive progress in the session-based recommendation. However, information such as item knowledge and click time interval, which could be potentially utilized to improve the performance, remains largely unexploited. In this paper, we propose a framework called Knowledge-enhanced Session-based Recommendation with Temporal Transformer (KSTT) to incorporate such information when learning the item and session embeddings. Specifically, a knowledge graph, which models contexts among items within a session and their corresponding attributes, is proposed to obtain item embeddings through graph representation learning. We introduce time interval embedding to represent the time pattern between the item that needs to be predicted and historical click, and use it to replace the position embedding in the original transformer (called temporal transformer). The item embeddings in a session are passed through the temporal transformer network to get the session embedding, based on which the final recommendation is made. Extensive experiments demonstrate that our model outperforms state-of-the-art baselines on four benchmark datasets.
Building Rule Hierarchies for Efficient Logical Rule Learning from Knowledge Graphs
Jun 30, 2020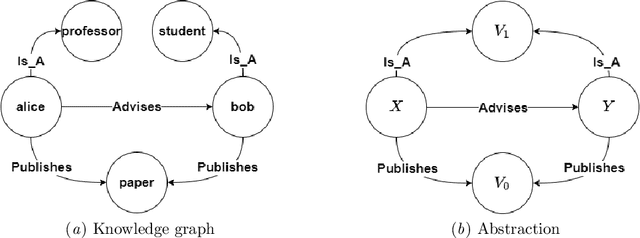
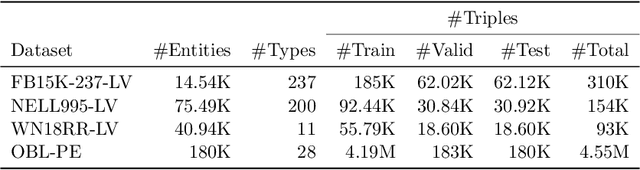
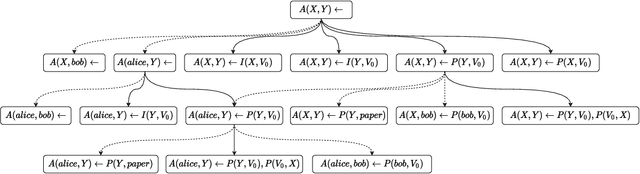
Many systems have been developed in recent years to mine logical rules from large-scale Knowledge Graphs (KGs), on the grounds that representing regularities as rules enables both the interpretable inference of new facts, and the explanation of known facts. Among these systems, the walk-based methods that generate the instantiated rules containing constants by abstracting sampled paths in KGs demonstrate strong predictive performance and expressivity. However, due to the large volume of possible rules, these systems do not scale well where computational resources are often wasted on generating and evaluating unpromising rules. In this work, we address such scalability issues by proposing new methods for pruning unpromising rules using rule hierarchies. The approach consists of two phases. Firstly, since rule hierarchies are not readily available in walk-based methods, we have built a Rule Hierarchy Framework (RHF), which leverages a collection of subsumption frameworks to build a proper rule hierarchy from a set of learned rules. And secondly, we adapt RHF to an existing rule learner where we design and implement two methods for Hierarchical Pruning (HPMs), which utilize the generated hierarchies to remove irrelevant and redundant rules. Through experiments over four public benchmark datasets, we show that the application of HPMs is effective in removing unpromising rules, which leads to significant reductions in the runtime as well as in the number of learned rules, without compromising the predictive performance.
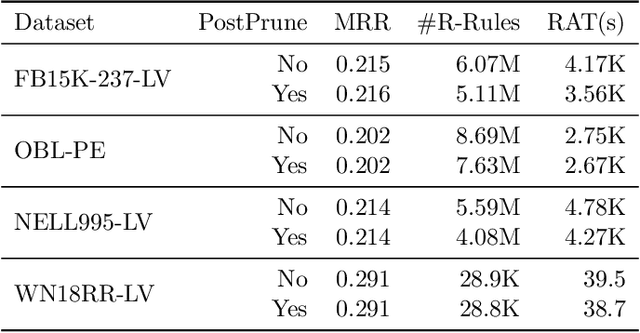
Efficient Rule Learning with Template Saturation for Knowledge Graph Completion
Mar 13, 2020
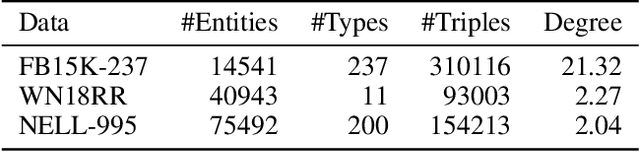
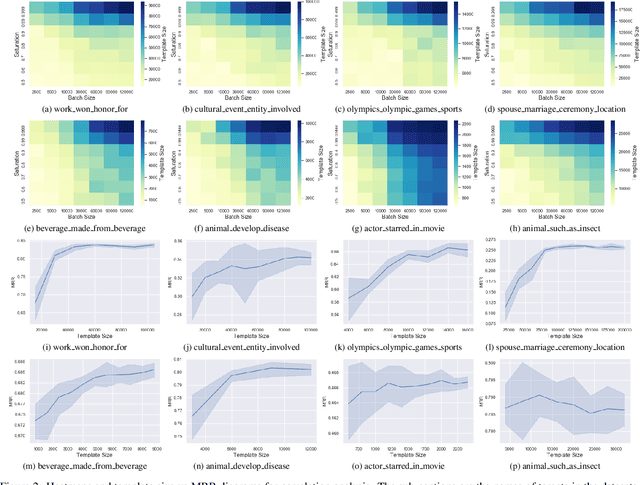
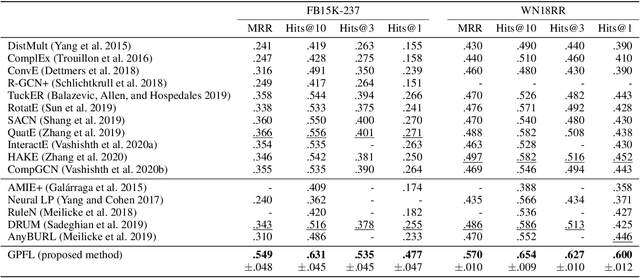
The logic-based methods that learn first-order rules from knowledge graphs (KGs) for knowledge graph completion (KGC) task are desirable in that the learnt models are inductive, interpretable and transferable. The challenge in such rule learners is that the expressive rules are often buried in vast rule space, and the procedure of identifying expressive rules by measuring rule quality is costly to execute. Therefore, optimizations on rule generation and evaluation are in need. In this work, we propose a novel bottom-up probabilistic rule learner that features: 1.) a two-stage procedure for optimized rule generation where the system first generalizes paths sampled from a KG into template rules that contain no constants until a certain degree of template saturation is achieved and then specializes template rules into instantiated rules that contain constants; 2.) a grouping technique for optimized rule evaluation where structurally similar instantiated rules derived from the same template rules are put into the same groups and evaluated collectively over the groundings of the deriving template rules. Through extensive experiments over large benchmark datasets on KGC task, our algorithm demonstrates consistent and substantial performance improvements over all of the state-of-the-art baselines.